 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Automated Framework for 3D Reconstruction of Medieval Manuscript Miniatures
Apr 08, 2026This paper presents a semi-automated framework for transforming two-dimensional miniatures from medieval manuscripts into three-dimensional digital models suitable for extended reality (XR), tactile 3D~printing, and web-based visualization. We evaluate seven image-to-3D methods (TripoSR, SF3D, SPAR3D, TRELLIS, Wonder3D, SAM~3D, Hi3DGen) on 69~manuscript figures from two collections using rendering-based metrics (Silhouette IoU, LPIPS, CLIP~Score) and volumetric measures (Depth Range Ratio, watertight percentage), revealing a trade-off between volumetric expansion and geometric fidelity. Hi3DGen balances topological quality with rich surface detail through its normal bridging approach, making it a good starting point for expert refinement. Our pipeline combines SAM segmentation, Hi3DGen mesh generation, expert refinement in ZBrush, and AI-assisted texturing. Two case studies on Gothic illuminations from the Decretum Gratiani (Vatican Library) and Renaissance miniatures by Giulio Clovio demonstrate applicability across artistic traditions. The resulting models can support WebXR visualization, AR overlay on physical manuscripts, and tactile 3D~prints for visually impaired users.
NeuralLVC: Neural Lossless Video Compression via Masked Diffusion with Temporal Conditioning
Apr 03, 2026While neural lossless image compression has advanced significantly with learned entropy models, lossless video compression remains largely unexplored in the neural setting. We present NeuralLVC, a neural lossless video codec that combines masked diffusion with an I/P-frame architecture for exploiting temporal redundancy. Our I-frame model compresses individual frames using bijective linear tokenization that guarantees exact pixel reconstruction. The P-frame model compresses temporal differences between consecutive frames, conditioned on the previous decoded frame via a lightweight reference embedding that adds only 1.3% trainable parameters. Group-wise decoding enables controllable speed-compression trade-offs. Our codec is lossless in the input domain: for video, it reconstructs YUV420 planes exactly; for image evaluation, RGB channels are reconstructed exactly. Experiments on 9 Xiph CIF sequences show that NeuralLVC outperforms H.264 and H.265 lossless by a significant margin. We verify exact reconstruction through end-to-end encode-decode testing with arithmetic coding. These results suggest that masked diffusion with temporal conditioning is a promising direction for neural lossless video compression.
Exploiting CLIP-based Multi-modal Approach for Artwork Classification and Retrieval
Sep 21, 2023Given the recent advances in multimodal image pretraining where visual models trained with semantically dense textual supervision tend to have better generalization capabilities than those trained using categorical attributes or through unsupervised techniques, in this work we investigate how recent CLIP model can be applied in several tasks in artwork domain. We perform exhaustive experiments on the NoisyArt dataset which is a dataset of artwork images crawled from public resources on the web. On such dataset CLIP achieves impressive results on (zero-shot) classification and promising results in both artwork-to-artwork and description-to-artwork domain.
Composed Image Retrieval using Contrastive Learning and Task-oriented CLIP-based Features
Aug 22, 2023Given a query composed of a reference image and a relative caption, the Composed Image Retrieval goal is to retrieve images visually similar to the reference one that integrates the modifications expressed by the caption. Given that recent research has demonstrated the efficacy of large-scale vision and language pre-trained (VLP) models in various tasks, we rely on features from the OpenAI CLIP model to tackle the considered task. We initially perform a task-oriented fine-tuning of both CLIP encoders using the element-wise sum of visual and textual features. Then, in the second stage, we train a Combiner network that learns to combine the image-text features integrating the bimodal information and providing combined features used to perform the retrieval. We use contrastive learning in both stages of training. Starting from the bare CLIP features as a baseline, experimental results show that the task-oriented fine-tuning and the carefully crafted Combiner network are highly effective and outperform more complex state-of-the-art approaches on FashionIQ and CIRR, two popular and challenging datasets for composed image retrieval. Code and pre-trained models are available at https://github.com/ABaldrati/CLIP4Cir
Learning advisor networks for noisy image classification
Nov 08, 2022In this paper, we introduced the novel concept of advisor network to address the problem of noisy labels in image classification. Deep neural networks (DNN) are prone to performance reduction and overfitting problems on training data with noisy annotations. Weighting loss methods aim to mitigate the influence of noisy labels during the training, completely removing their contribution. This discarding process prevents DNNs from learning wrong associations between images and their correct labels but reduces the amount of data used, especially when most of the samples have noisy labels. Differently, our method weighs the feature extracted directly from the classifier without altering the loss value of each data. The advisor helps to focus only on some part of the information present in mislabeled examples, allowing the classifier to leverage that data as well. We trained it with a meta-learning strategy so that it can adapt throughout the training of the main model. We tested our method on CIFAR10 and CIFAR100 with synthetic noise, and on Clothing1M which contains real-world noise, reporting state-of-the-art results.
* Paper published as Poster at ICIAP21
Learning Group Activities from Skeletons without Individual Action Labels
May 14, 2021
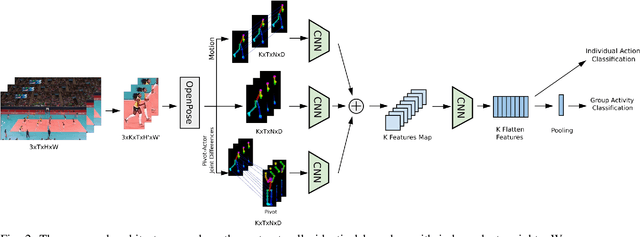
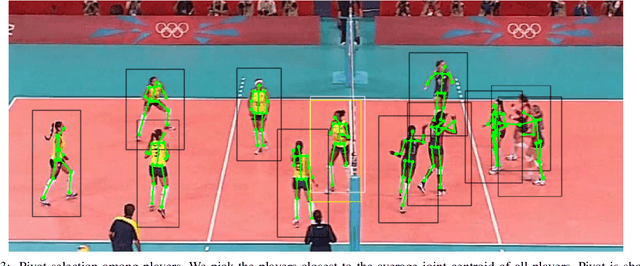
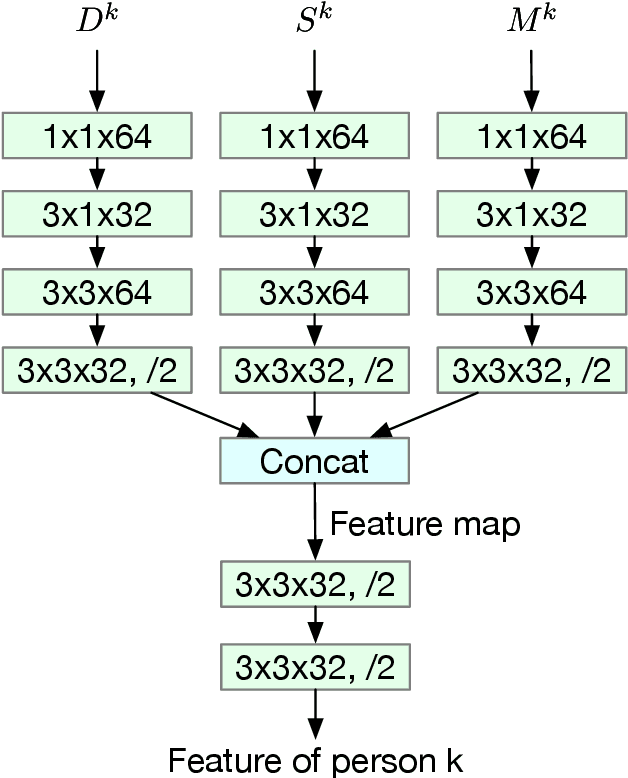
To understand human behavior we must not just recognize individual actions but model possibly complex group activity and interactions. Hierarchical models obtain the best results in group activity recognition but require fine grained individual action annotations at the actor level. In this paper we show that using only skeletal data we can train a state-of-the art end-to-end system using only group activity labels at the sequence level. Our experiments show that models trained without individual action supervision perform poorly. On the other hand we show that pseudo-labels can be computed from any pre-trained feature extractor with comparable final performance. Finally our carefully designed lean pose only architecture shows highly competitive results versus more complex multimodal approaches even in the self-supervised variant.
Image Retrieval using Multi-scale CNN Features Pooling
Apr 24, 2020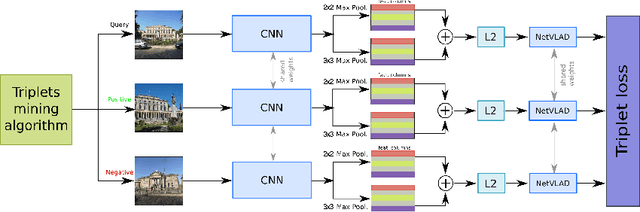
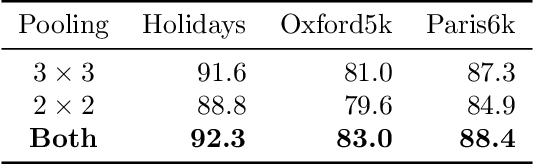
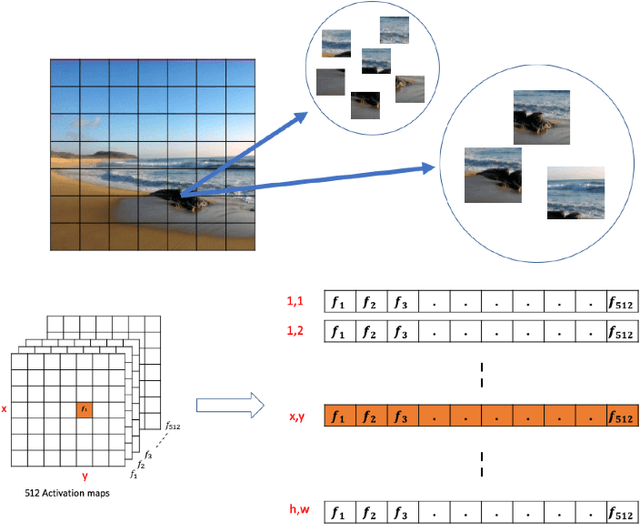
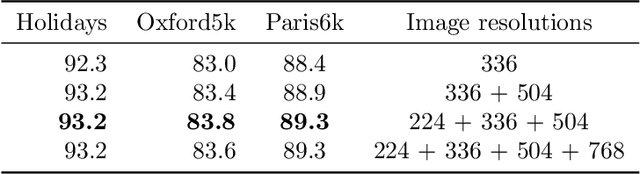
In this paper, we address the problem of image retrieval by learning images representation based on the activations of a Convolutional Neural Network. We present an end-to-end trainable network architecture that exploits a novel multi-scale local pooling based on NetVLAD and a triplet mining procedure based on samples difficulty to obtain an effective image representation. Extensive experiments show that our approach is able to reach state-of-the-art results on three standard datasets.
Am I Done? Predicting Action Progress in Videos
Mar 28, 2018
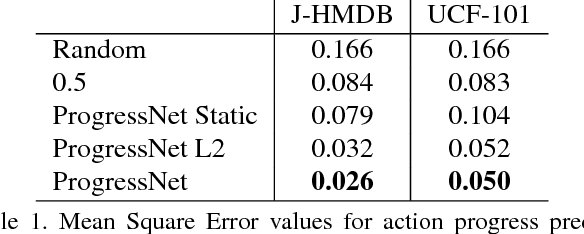
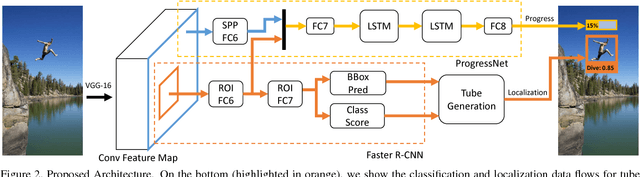
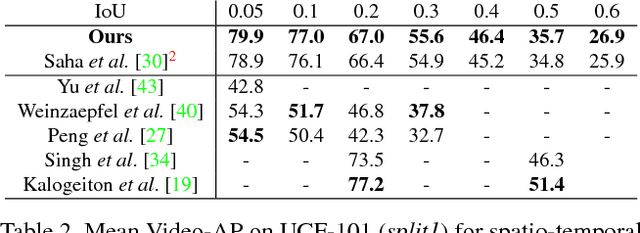
In this paper we introduce the problem of predicting action progress in videos. We argue that this is an extremely important task because, on the one hand, it can be valuable for a wide range of applications and, on the other hand, it facilitates better action detection results. To this end we introduce a novel approach, named ProgressNet, capable of predicting when an action takes place in a video, where it is located within the frames, and how far it has progressed during its execution. Motivated by the recent success obtained from the interaction of Convolutional and Recurrent Neural Networks, our model is based on a combination of the Faster R-CNN framework, to make framewise predictions, and LSTM networks, to estimate action progress through time. After introducing two evaluation protocols for the task at hand, we demonstrate the capability of our model to effectively predict action progress on the UCF-101 and J-HMDB datasets. Additionally, we show that exploiting action progress it is also possible to improve spatio-temporal localization.
Automatic Image Annotation via Label Transfer in the Semantic Space
Jun 01, 2017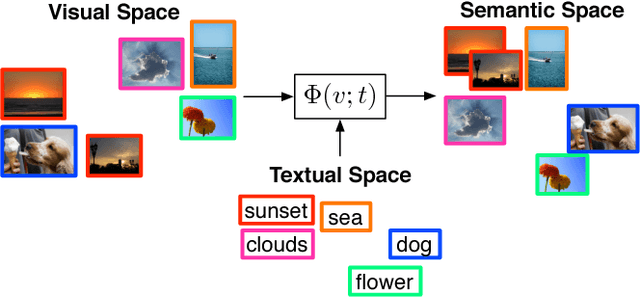
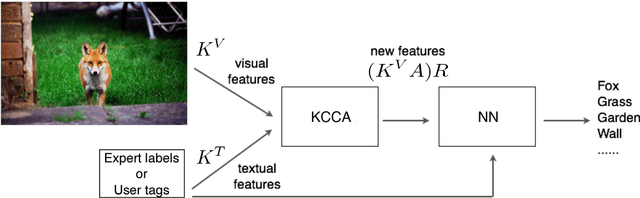
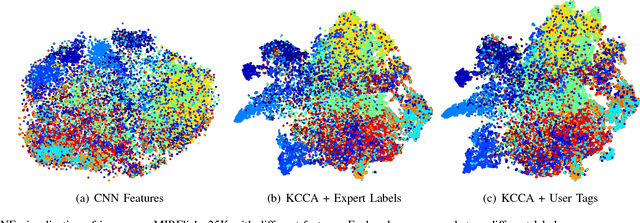
Automatic image annotation is among the fundamental problems in computer vision and pattern recognition, and it is becoming increasingly important in order to develop algorithms that are able to search and browse large-scale image collections. In this paper, we propose a label propagation framework based on Kernel Canonical Correlation Analysis (KCCA), which builds a latent semantic space where correlation of visual and textual features are well preserved into a semantic embedding. The proposed approach is robust and can work either when the training set is well annotated by experts, as well as when it is noisy such as in the case of user-generated tags in social media. We report extensive results on four popular datasets. Our results show that our KCCA-based framework can be applied to several state-of-the-art label transfer methods to obtain significant improvements. Our approach works even with the noisy tags of social users, provided that appropriate denoising is performed. Experiments on a large scale setting show that our method can provide some benefits even when the semantic space is estimated on a subset of training images.
Socializing the Semantic Gap: A Comparative Survey on Image Tag Assignment, Refinement and Retrieval
Mar 23, 2016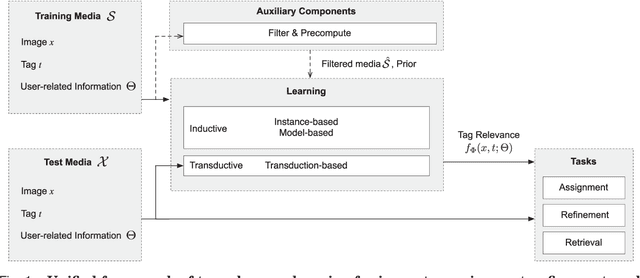
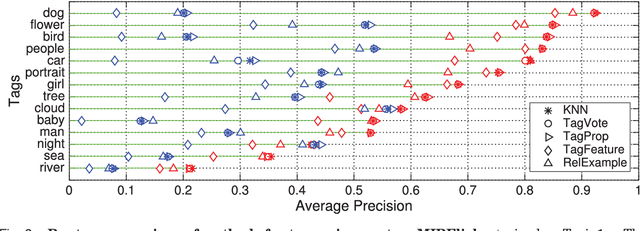
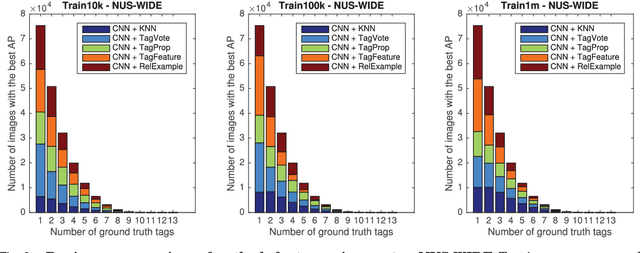
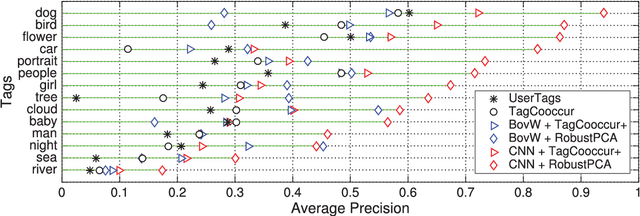
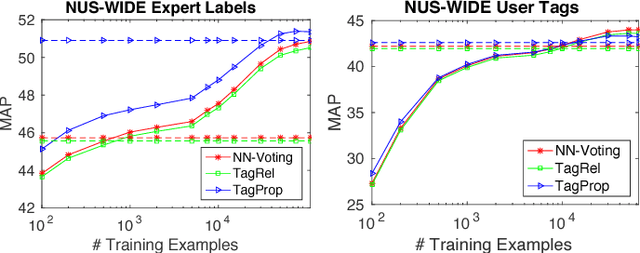
Where previous reviews on content-based image retrieval emphasize on what can be seen in an image to bridge the semantic gap, this survey considers what people tag about an image. A comprehensive treatise of three closely linked problems, i.e., image tag assignment, refinement, and tag-based image retrieval is presented. While existing works vary in terms of their targeted tasks and methodology, they rely on the key functionality of tag relevance, i.e. estimating the relevance of a specific tag with respect to the visual content of a given image and its social context. By analyzing what information a specific method exploits to construct its tag relevance function and how such information is exploited, this paper introduces a taxonomy to structure the growing literature, understand the ingredients of the main works, clarify their connections and difference, and recognize their merits and limitations. For a head-to-head comparison between the state-of-the-art, a new experimental protocol is presented, with training sets containing 10k, 100k and 1m images and an evaluation on three test sets, contributed by various research groups. Eleven representative works are implemented and evaluated. Putting all this together, the survey aims to provide an overview of the past and foster progress for the near future.
* to appear in ACM Computing Surveys