 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAm I Done? Predicting Action Progress in Videos
Paper and Code

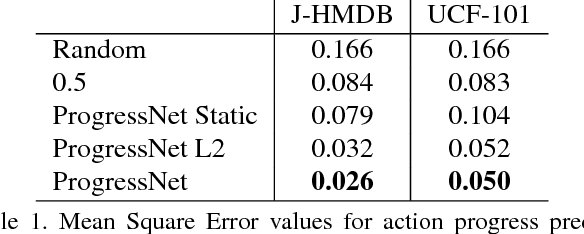
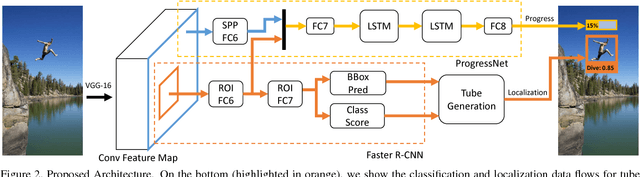
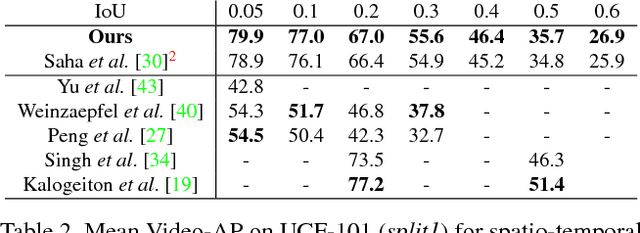
In this paper we introduce the problem of predicting action progress in videos. We argue that this is an extremely important task because, on the one hand, it can be valuable for a wide range of applications and, on the other hand, it facilitates better action detection results. To this end we introduce a novel approach, named ProgressNet, capable of predicting when an action takes place in a video, where it is located within the frames, and how far it has progressed during its execution. Motivated by the recent success obtained from the interaction of Convolutional and Recurrent Neural Networks, our model is based on a combination of the Faster R-CNN framework, to make framewise predictions, and LSTM networks, to estimate action progress through time. After introducing two evaluation protocols for the task at hand, we demonstrate the capability of our model to effectively predict action progress on the UCF-101 and J-HMDB datasets. Additionally, we show that exploiting action progress it is also possible to improve spatio-temporal localization.