 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
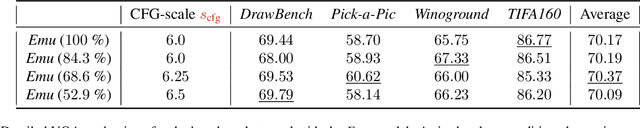
Apr 07, 2026Humans paint images incrementally: they plan a global layout, sketch a coarse draft, inspect, and refine details, and most importantly, each step is grounded in the evolving visual states. However, can unified multimodal models trained on text-image interleaved datasets also imagine the chain of intermediate states? In this paper, we introduce process-driven image generation, a multi-step paradigm that decomposes synthesis into an interleaved reasoning trajectory of thoughts and actions. Rather than generating images in a single step, our approach unfolds across multiple iterations, each consisting of 4 stages: textual planning, visual drafting, textual reflection, and visual refinement. The textual reasoning explicitly conditions how the visual state should evolve, while the generated visual intermediate in turn constrains and grounds the next round of textual reasoning. A core challenge of process-driven generation stems from the ambiguity of intermediate states: how can models evaluate each partially-complete image? We address this through dense, step-wise supervision that maintains two complementary constraints: for the visual intermediate states, we enforce the spatial and semantic consistency; for the textual intermediate states, we preserve the prior visual knowledge while enabling the model to identify and correct prompt-violating elements. This makes the generation process explicit, interpretable, and directly supervisable. To validate proposed method, we conduct experiments under various text-to-image generation benchmarks.
SneakPeek: Future-Guided Instructional Streaming Video Generation
Dec 15, 2025Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.
Autoregressive Distillation of Diffusion Transformers
Apr 15, 2025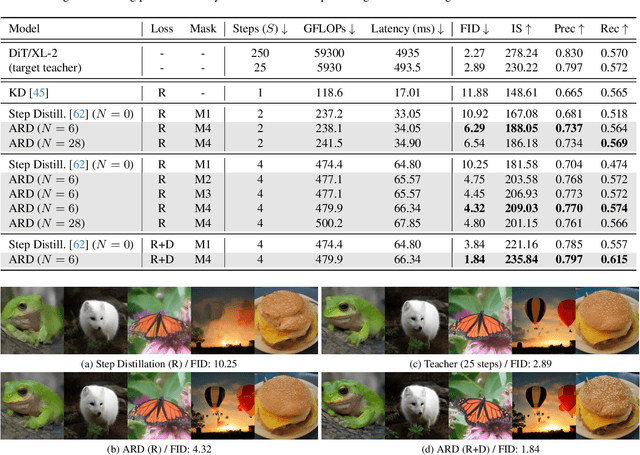
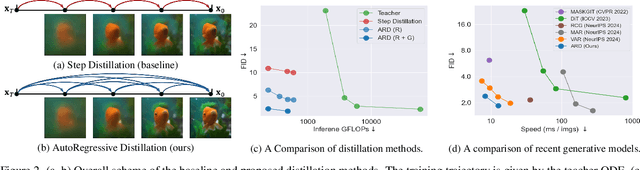
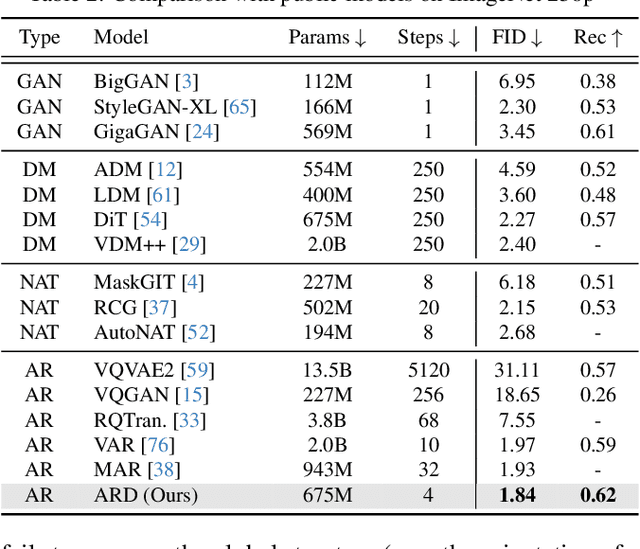
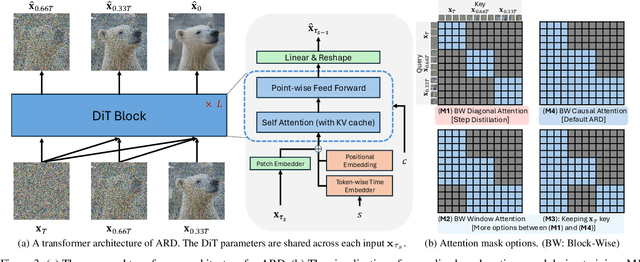
Diffusion models with transformer architectures have demonstrated promising capabilities in generating high-fidelity images and scalability for high resolution. However, iterative sampling process required for synthesis is very resource-intensive. A line of work has focused on distilling solutions to probability flow ODEs into few-step student models. Nevertheless, existing methods have been limited by their reliance on the most recent denoised samples as input, rendering them susceptible to exposure bias. To address this limitation, we propose AutoRegressive Distillation (ARD), a novel approach that leverages the historical trajectory of the ODE to predict future steps. ARD offers two key benefits: 1) it mitigates exposure bias by utilizing a predicted historical trajectory that is less susceptible to accumulated errors, and 2) it leverages the previous history of the ODE trajectory as a more effective source of coarse-grained information. ARD modifies the teacher transformer architecture by adding token-wise time embedding to mark each input from the trajectory history and employs a block-wise causal attention mask for training. Furthermore, incorporating historical inputs only in lower transformer layers enhances performance and efficiency. We validate the effectiveness of ARD in a class-conditioned generation on ImageNet and T2I synthesis. Our model achieves a $5\times$ reduction in FID degradation compared to the baseline methods while requiring only 1.1\% extra FLOPs on ImageNet-256. Moreover, ARD reaches FID of 1.84 on ImageNet-256 in merely 4 steps and outperforms the publicly available 1024p text-to-image distilled models in prompt adherence score with a minimal drop in FID compared to the teacher. Project page: https://github.com/alsdudrla10/ARD.
FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute
Feb 27, 2025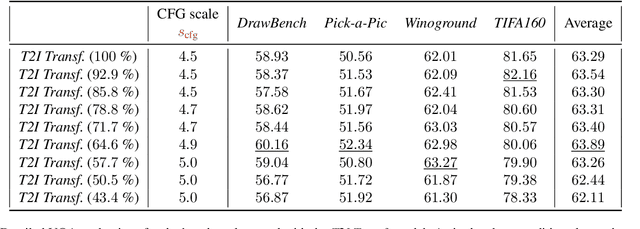


Despite their remarkable performance, modern Diffusion Transformers are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into \emph{flexible} ones -- dubbed FlexiDiT -- allowing them to process inputs at varying compute budgets. We demonstrate how a single \emph{flexible} model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment
Jan 31, 2025



The performance of large language models (LLMs) is closely linked to their underlying size, leading to ever-growing networks and hence slower inference. Speculative decoding has been proposed as a technique to accelerate autoregressive generation, leveraging a fast draft model to propose candidate tokens, which are then verified in parallel based on their likelihood under the target model. While this approach guarantees to reproduce the target output, it incurs a substantial penalty: many high-quality draft tokens are rejected, even when they represent objectively valid continuations. Indeed, we show that even powerful draft models such as GPT-4o, as well as human text cannot achieve high acceptance rates under the standard verification scheme. This severely limits the speedup potential of current speculative decoding methods, as an early rejection becomes overwhelmingly likely when solely relying on alignment of draft and target. We thus ask the following question: Can we adapt verification to recognize correct, but non-aligned replies? To this end, we draw inspiration from the LLM-as-a-judge framework, which demonstrated that LLMs are able to rate answers in a versatile way. We carefully design a dataset to elicit the same capability in the target model by training a compact module on top of the embeddings to produce ``judgements" of the current continuation. We showcase our strategy on the Llama-3.1 family, where our 8b/405B-Judge achieves a speedup of 9x over Llama-405B, while maintaining its quality on a large range of benchmarks. These benefits remain present even in optimized inference frameworks, where our method reaches up to 141 tokens/s for 8B/70B-Judge and 129 tokens/s for 8B/405B on 2 and 8 H100s respectively.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
GGHead: Fast and Generalizable 3D Gaussian Heads
Jun 13, 2024Learning 3D head priors from large 2D image collections is an important step towards high-quality 3D-aware human modeling. A core requirement is an efficient architecture that scales well to large-scale datasets and large image resolutions. Unfortunately, existing 3D GANs struggle to scale to generate samples at high resolutions due to their relatively slow train and render speeds, and typically have to rely on 2D superresolution networks at the expense of global 3D consistency. To address these challenges, we propose Generative Gaussian Heads (GGHead), which adopts the recent 3D Gaussian Splatting representation within a 3D GAN framework. To generate a 3D representation, we employ a powerful 2D CNN generator to predict Gaussian attributes in the UV space of a template head mesh. This way, GGHead exploits the regularity of the template's UV layout, substantially facilitating the challenging task of predicting an unstructured set of 3D Gaussians. We further improve the geometric fidelity of the generated 3D representations with a novel total variation loss on rendered UV coordinates. Intuitively, this regularization encourages that neighboring rendered pixels should stem from neighboring Gaussians in the template's UV space. Taken together, our pipeline can efficiently generate 3D heads trained only from single-view 2D image observations. Our proposed framework matches the quality of existing 3D head GANs on FFHQ while being both substantially faster and fully 3D consistent. As a result, we demonstrate real-time generation and rendering of high-quality 3D-consistent heads at $1024^2$ resolution for the first time.
Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization
Feb 19, 2024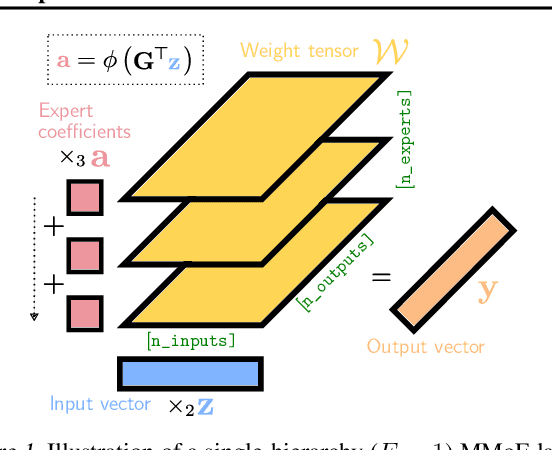



The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification. Our MMoE model code is available at https://github.com/james-oldfield/MMoE.
Leveraging the Context through Multi-Round Interactions for Jailbreaking Attacks
Feb 14, 2024



Large Language Models (LLMs) are susceptible to Jailbreaking attacks, which aim to extract harmful information by subtly modifying the attack query. As defense mechanisms evolve, directly obtaining harmful information becomes increasingly challenging for Jailbreaking attacks. In this work, inspired by human practices of indirect context to elicit harmful information, we focus on a new attack form called Contextual Interaction Attack. The idea relies on the autoregressive nature of the generation process in LLMs. We contend that the prior context--the information preceding the attack query--plays a pivotal role in enabling potent Jailbreaking attacks. Specifically, we propose an approach that leverages preliminary question-answer pairs to interact with the LLM. By doing so, we guide the responses of the model toward revealing the 'desired' harmful information. We conduct experiments on four different LLMs and demonstrate the efficacy of this attack, which is black-box and can also transfer across LLMs. We believe this can lead to further developments and understanding of the context vector in LLMs.
Multilinear Operator Networks
Jan 31, 2024Despite the remarkable capabilities of deep neural networks in image recognition, the dependence on activation functions remains a largely unexplored area and has yet to be eliminated. On the other hand, Polynomial Networks is a class of models that does not require activation functions, but have yet to perform on par with modern architectures. In this work, we aim close this gap and propose MONet, which relies solely on multilinear operators. The core layer of MONet, called Mu-Layer, captures multiplicative interactions of the elements of the input token. MONet captures high-degree interactions of the input elements and we demonstrate the efficacy of our approach on a series of image recognition and scientific computing benchmarks. The proposed model outperforms prior polynomial networks and performs on par with modern architectures. We believe that MONet can inspire further research on models that use entirely multilinear operations.