 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute
Feb 27, 2025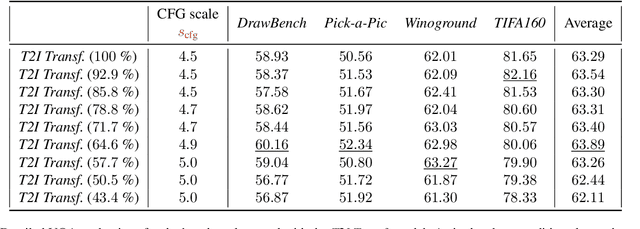

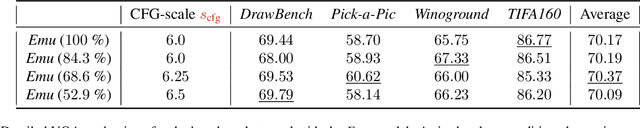

Despite their remarkable performance, modern Diffusion Transformers are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into \emph{flexible} ones -- dubbed FlexiDiT -- allowing them to process inputs at varying compute budgets. We demonstrate how a single \emph{flexible} model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment
Jan 31, 2025



The performance of large language models (LLMs) is closely linked to their underlying size, leading to ever-growing networks and hence slower inference. Speculative decoding has been proposed as a technique to accelerate autoregressive generation, leveraging a fast draft model to propose candidate tokens, which are then verified in parallel based on their likelihood under the target model. While this approach guarantees to reproduce the target output, it incurs a substantial penalty: many high-quality draft tokens are rejected, even when they represent objectively valid continuations. Indeed, we show that even powerful draft models such as GPT-4o, as well as human text cannot achieve high acceptance rates under the standard verification scheme. This severely limits the speedup potential of current speculative decoding methods, as an early rejection becomes overwhelmingly likely when solely relying on alignment of draft and target. We thus ask the following question: Can we adapt verification to recognize correct, but non-aligned replies? To this end, we draw inspiration from the LLM-as-a-judge framework, which demonstrated that LLMs are able to rate answers in a versatile way. We carefully design a dataset to elicit the same capability in the target model by training a compact module on top of the embeddings to produce ``judgements" of the current continuation. We showcase our strategy on the Llama-3.1 family, where our 8b/405B-Judge achieves a speedup of 9x over Llama-405B, while maintaining its quality on a large range of benchmarks. These benefits remain present even in optimized inference frameworks, where our method reaches up to 141 tokens/s for 8B/70B-Judge and 129 tokens/s for 8B/405B on 2 and 8 H100s respectively.
Tokenisation is NP-Complete
Dec 19, 2024In this work, we prove the NP-completeness of two variants of tokenisation, defined as the problem of compressing a dataset to at most $\delta$ symbols by either finding a vocabulary directly (direct tokenisation), or selecting a sequence of merge operations (bottom-up tokenisation).
Interpolated-MLPs: Controllable Inductive Bias
Oct 12, 2024



Due to their weak inductive bias, Multi-Layer Perceptrons (MLPs) have subpar performance at low-compute levels compared to standard architectures such as convolution-based networks (CNN). Recent work, however, has shown that the performance gap drastically reduces as the amount of compute is increased without changing the amount of inductive bias. In this work, we study the converse: in the low-compute regime, how does the incremental increase of inductive bias affect performance? To quantify inductive bias, we propose a "soft MLP" approach, which we coin Interpolated MLP (I-MLP). We control the amount of inductive bias in the standard MLP by introducing a novel algorithm based on interpolation between fixed weights from a prior model with high inductive bias. We showcase our method using various prior models, including CNNs and the MLP-Mixer architecture. This interpolation scheme allows fractional control of inductive bias, which may be attractive when full inductive bias is not desired (e.g. in the mid-compute regime). We find experimentally that for Vision Tasks in the low-compute regime, there is a continuous and two-sided logarithmic relationship between inductive bias and performance when using CNN and MLP-Mixer prior models.
The pitfalls of next-token prediction
Mar 11, 2024Can a mere next-token predictor faithfully model human intelligence? We crystallize this intuitive concern, which is fragmented in the literature. As a starting point, we argue that the two often-conflated phases of next-token prediction -- autoregressive inference and teacher-forced training -- must be treated distinctly. The popular criticism that errors can compound during autoregressive inference, crucially assumes that teacher-forcing has learned an accurate next-token predictor. This assumption sidesteps a more deep-rooted problem we expose: in certain classes of tasks, teacher-forcing can simply fail to learn an accurate next-token predictor in the first place. We describe a general mechanism of how teacher-forcing can fail, and design a minimal planning task where both the Transformer and the Mamba architecture empirically fail in that manner -- remarkably, despite the task being straightforward to learn. We provide preliminary evidence that this failure can be resolved when training to predict multiple tokens in advance. We hope this finding can ground future debates and inspire explorations beyond the next-token prediction paradigm. We make our code available under https://github.com/gregorbachmann/Next-Token-Failures
A Language Model's Guide Through Latent Space
Feb 22, 2024Concept guidance has emerged as a cheap and simple way to control the behavior of language models by probing their hidden representations for concept vectors and using them to perturb activations at inference time. While the focus of previous work has largely been on truthfulness, in this paper we extend this framework to a richer set of concepts such as appropriateness, humor, creativity and quality, and explore to what degree current detection and guidance strategies work in these challenging settings. To facilitate evaluation, we develop a novel metric for concept guidance that takes into account both the success of concept elicitation as well as the potential degradation in fluency of the guided model. Our extensive experiments reveal that while some concepts such as truthfulness more easily allow for guidance with current techniques, novel concepts such as appropriateness or humor either remain difficult to elicit, need extensive tuning to work, or even experience confusion. Moreover, we find that probes with optimal detection accuracies do not necessarily make for the optimal guides, contradicting previous observations for truthfulness. Our work warrants a deeper investigation into the interplay between detectability, guidability, and the nature of the concept, and we hope that our rich experimental test-bed for guidance research inspires stronger follow-up approaches.
How Good is a Single Basin?
Feb 05, 2024The multi-modal nature of neural loss landscapes is often considered to be the main driver behind the empirical success of deep ensembles. In this work, we probe this belief by constructing various "connected" ensembles which are restricted to lie in the same basin. Through our experiments, we demonstrate that increased connectivity indeed negatively impacts performance. However, when incorporating the knowledge from other basins implicitly through distillation, we show that the gap in performance can be mitigated by re-discovering (multi-basin) deep ensembles within a single basin. Thus, we conjecture that while the extra-basin knowledge is at least partially present in any given basin, it cannot be easily harnessed without learning it from other basins.
Disentangling Linear Mode-Connectivity
Dec 15, 2023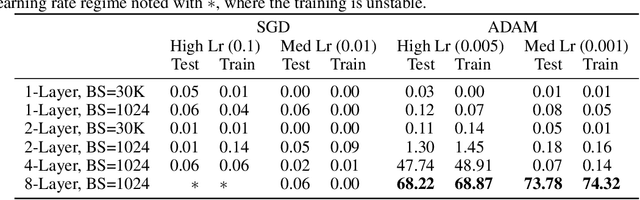

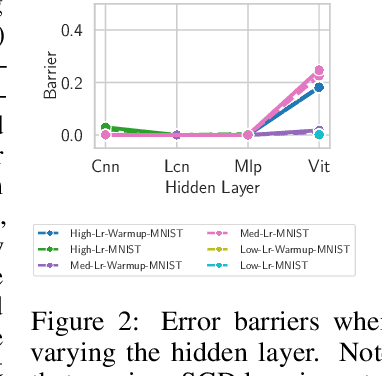
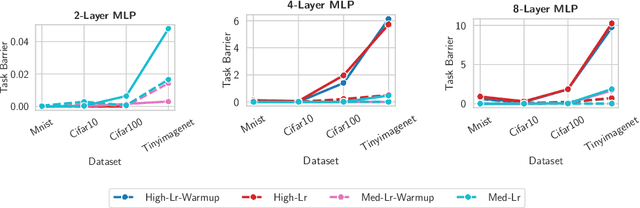
Linear mode-connectivity (LMC) (or lack thereof) is one of the intriguing characteristics of neural network loss landscapes. While empirically well established, it unfortunately still lacks a proper theoretical understanding. Even worse, although empirical data points are abound, a systematic study of when networks exhibit LMC is largely missing in the literature. In this work we aim to close this gap. We explore how LMC is affected by three factors: (1) architecture (sparsity, weight-sharing), (2) training strategy (optimization setup) as well as (3) the underlying dataset. We place particular emphasis on minimal but non-trivial settings, removing as much unnecessary complexity as possible. We believe that our insights can guide future theoretical works on uncovering the inner workings of LMC.
Navigating Scaling Laws: Accelerating Vision Transformer's Training via Adaptive Strategies
Nov 06, 2023



In recent years, the state-of-the-art in deep learning has been dominated by very large models that have been pre-trained on vast amounts of data. The paradigm is very simple: Investing more computational resources (optimally) leads to better performance, and even predictably so; neural scaling laws have been derived that accurately forecast the performance of a network for a desired level of compute. This leads to the notion of a "compute-optimal" model, i.e. a model that allocates a given level of compute during training optimally to maximise performance. In this work, we extend the concept of optimality by allowing for an "adaptive" model, i.e. a model that can change its shape during the course of training. By allowing the shape to adapt, we can optimally traverse between the underlying scaling laws, leading to a significant reduction in the required compute to reach a given target performance. We focus on vision tasks and the family of Vision Transformers, where the patch size as well as the width naturally serve as adaptive shape parameters. We demonstrate that, guided by scaling laws, we can design compute-optimal adaptive models that beat their "static" counterparts.
Scaling MLPs: A Tale of Inductive Bias
Jun 23, 2023In this work we revisit the most fundamental building block in deep learning, the multi-layer perceptron (MLP), and study the limits of its performance on vision tasks. Empirical insights into MLPs are important for multiple reasons. (1) Given the recent narrative "less inductive bias is better", popularized due to transformers eclipsing convolutional models, it is natural to explore the limits of this hypothesis. To that end, MLPs offer an ideal test bed, being completely free of any inductive bias. (2) MLPs have almost exclusively been the main protagonist in the deep learning theory literature due to their mathematical simplicity, serving as a proxy to explain empirical phenomena observed for more complex architectures. Surprisingly, experimental datapoints for MLPs are very difficult to find in the literature, especially when coupled with large pre-training protocols. This discrepancy between practice and theory is worrying: Do MLPs reflect the empirical advances exhibited by practical models? Or do theorists need to rethink the role of MLPs as a proxy? We provide insights into both these aspects. We show that the performance of MLPs drastically improves with scale (93% on CIFAR10, 79% on CIFAR100, 69% on TinyImageNet), highlighting that lack of inductive bias can indeed be compensated. We observe that MLPs mimic the behaviour of their modern counterparts faithfully, with some components in the learning setting however surprisingly exhibiting stronger or unexpected behaviours. Due to their inherent computational efficiency, large pre-training experiments become more accessible for academic researchers. All of our experiments were run on a single GPU.