 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAS: A Decision-Theoretic Approach to Evaluating Large Language Model Confidence
Apr 03, 2026Large language models (LLMs) often produce confident but incorrect answers in settings where abstention would be safer. Standard evaluation protocols, however, require a response and do not account for how confidence should guide decisions under different risk preferences. To address this gap, we introduce the Behavioral Alignment Score (BAS), a decision-theoretic metric for evaluating how well LLM confidence supports abstention-aware decision making. BAS is derived from an explicit answer-or-abstain utility model and aggregates realized utility across a continuum of risk thresholds, yielding a measure of decision-level reliability that depends on both the magnitude and ordering of confidence. We show theoretically that truthful confidence estimates uniquely maximize expected BAS utility, linking calibration to decision-optimal behavior. BAS is related to proper scoring rules such as log loss, but differs structurally: log loss penalizes underconfidence and overconfidence symmetrically, whereas BAS imposes an asymmetric penalty that strongly prioritizes avoiding overconfident errors. Using BAS alongside widely used metrics such as ECE and AURC, we then construct a benchmark of self-reported confidence reliability across multiple LLMs and tasks. Our results reveal substantial variation in decision-useful confidence, and while larger and more accurate models tend to achieve higher BAS, even frontier models remain prone to severe overconfidence. Importantly, models with similar ECE or AURC can exhibit very different BAS due to highly overconfident errors, highlighting limitations of standard metrics. We further show that simple interventions, such as top-$k$ confidence elicitation and post-hoc calibration, can meaningfully improve confidence reliability. Overall, our work provides both a principled metric and a comprehensive benchmark for evaluating LLM confidence reliability.
Entropy Alone is Insufficient for Safe Selective Prediction in LLMs
Mar 22, 2026Selective prediction systems can mitigate harms resulting from language model hallucinations by abstaining from answering in high-risk cases. Uncertainty quantification techniques are often employed to identify such cases, but are rarely evaluated in the context of the wider selective prediction policy and its ability to operate at low target error rates. We identify a model-dependent failure mode of entropy-based uncertainty methods that leads to unreliable abstention behaviour, and address it by combining entropy scores with a correctness probe signal. We find that across three QA benchmarks (TriviaQA, BioASQ, MedicalQA) and four model families, the combined score generally improves both the risk--coverage trade-off and calibration performance relative to entropy-only baselines. Our results highlight the importance of deployment-facing evaluation of uncertainty methods, using metrics that directly reflect whether a system can be trusted to operate at a stated risk level.
Ablate and Rescue: A Causal Analysis of Residual Stream Hyper-Connections
Mar 16, 2026Multi-stream transformer architectures have recently been proposed as a promising direction for managing representation collapse and the vanishing gradient problem for residual connections, yet their internal mechanisms remain unexplored. In particular, the recently introduced Manifold-Constrained Hyper-Connections (mHC) architecture posits multiple residual streams with constrained interaction, but lacks in-depth mechanistic analysis. We present the first open-source mHC language model (https://huggingface.co/wgpeng/mhc-780m) and analyze the multiple-stream architecture with a suite of representation-level metrics and causal interventions to probe how parallel streams encode and utilize information. Specifically, we introduce a systematic stream ablation-and-rescue framework that enables direct causal comparison of residual streams during inference. Through targeted pairwise interventions and controlled recovery experiments, we distinguish functional redundancy from asymmetric utilization and reveal how information is distributed across streams beyond what is observable from representational similarity alone.
Semantic Self-Distillation for Language Model Uncertainty
Feb 04, 2026Large language models present challenges for principled uncertainty quantification, in part due to their complexity and the diversity of their outputs. Semantic dispersion, or the variance in the meaning of sampled answers, has been proposed as a useful proxy for model uncertainty, but the associated computational cost prohibits its use in latency-critical applications. We show that sampled semantic distributions can be distilled into lightweight student models which estimate a prompt-conditioned uncertainty before the language model generates an answer token. The student model predicts a semantic distribution over possible answers; the entropy of this distribution provides an effective uncertainty signal for hallucination prediction, and the probability density allows candidate answers to be evaluated for reliability. On TriviaQA, our student models match or outperform finite-sample semantic dispersion for hallucination prediction and provide a strong signal for out-of-domain answer detection. We term this technique Semantic Self-Distillation (SSD), which we suggest provides a general framework for distilling predictive uncertainty in complex output spaces beyond language.
AutoMedPrompt: A New Framework for Optimizing LLM Medical Prompts Using Textual Gradients
Feb 21, 2025Large language models (LLMs) have demonstrated increasingly sophisticated performance in medical and other fields of knowledge. Traditional methods of creating specialist LLMs require extensive fine-tuning and training of models on large datasets. Recently, prompt engineering, instead of fine-tuning, has shown potential to boost the performance of general foundation models. However, prompting methods such as chain-of-thought (CoT) may not be suitable for all subspecialty, and k-shot approaches may introduce irrelevant tokens into the context space. We present AutoMedPrompt, which explores the use of textual gradients to elicit medically relevant reasoning through system prompt optimization. AutoMedPrompt leverages TextGrad's automatic differentiation via text to improve the ability of general foundation LLMs. We evaluated AutoMedPrompt on Llama 3, an open-source LLM, using several QA benchmarks, including MedQA, PubMedQA, and the nephrology subspecialty-specific NephSAP. Our results show that prompting with textual gradients outperforms previous methods on open-source LLMs and surpasses proprietary models such as GPT-4, Claude 3 Opus, and Med-PaLM 2. AutoMedPrompt sets a new state-of-the-art (SOTA) performance on PubMedQA with an accuracy of 82.6$\%$, while also outperforming previous prompting strategies on open-sourced models for MedQA (77.7$\%$) and NephSAP (63.8$\%$).
PBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Dec 12, 2024We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
Self-supervised denoising of visual field data improves detection of glaucoma progression
Nov 19, 2024Perimetric measurements provide insight into a patient's peripheral vision and day-to-day functioning and are the main outcome measure for identifying progression of visual damage from glaucoma. However, visual field data can be noisy, exhibiting high variance, especially with increasing damage. In this study, we demonstrate the utility of self-supervised deep learning in denoising visual field data from over 4000 patients to enhance its signal-to-noise ratio and its ability to detect true glaucoma progression. We deployed both a variational autoencoder (VAE) and a masked autoencoder to determine which self-supervised model best smooths the visual field data while reconstructing salient features that are less noisy and more predictive of worsening disease. Our results indicate that including a categorical p-value at every visual field location improves the smoothing of visual field data. Masked autoencoders led to cleaner denoised data than previous methods, such as variational autoencoders. A 4.7% increase in detection of progressing eyes with pointwise linear regression (PLR) was observed. The masked and variational autoencoders' smoothed data predicted glaucoma progression 2.3 months earlier when p-values were included compared to when they were not. The faster prediction of time to progression (TTP) and the higher percentage progression detected support our hypothesis that masking out visual field elements during training while including p-values at each location would improve the task of detection of visual field progression. Our study has clinically relevant implications regarding masking when training neural networks to denoise visual field data, resulting in earlier and more accurate detection of glaucoma progression. This denoising model can be integrated into future models for visual field analysis to enhance detection of glaucoma progression.
Interpolated-MLPs: Controllable Inductive Bias
Oct 12, 2024



Due to their weak inductive bias, Multi-Layer Perceptrons (MLPs) have subpar performance at low-compute levels compared to standard architectures such as convolution-based networks (CNN). Recent work, however, has shown that the performance gap drastically reduces as the amount of compute is increased without changing the amount of inductive bias. In this work, we study the converse: in the low-compute regime, how does the incremental increase of inductive bias affect performance? To quantify inductive bias, we propose a "soft MLP" approach, which we coin Interpolated MLP (I-MLP). We control the amount of inductive bias in the standard MLP by introducing a novel algorithm based on interpolation between fixed weights from a prior model with high inductive bias. We showcase our method using various prior models, including CNNs and the MLP-Mixer architecture. This interpolation scheme allows fractional control of inductive bias, which may be attractive when full inductive bias is not desired (e.g. in the mid-compute regime). We find experimentally that for Vision Tasks in the low-compute regime, there is a continuous and two-sided logarithmic relationship between inductive bias and performance when using CNN and MLP-Mixer prior models.
Adversarial Databases Improve Success in Retrieval-based Large Language Models
Jul 19, 2024Open-source LLMs have shown great potential as fine-tuned chatbots, and demonstrate robust abilities in reasoning and surpass many existing benchmarks. Retrieval-Augmented Generation (RAG) is a technique for improving the performance of LLMs on tasks that the models weren't explicitly trained on, by leveraging external knowledge databases. Numerous studies have demonstrated the effectiveness of RAG to more successfully accomplish downstream tasks when using vector datasets that consist of relevant background information. It has been implicitly assumed by those in the field that if adversarial background information is utilized in this context, that the success of using a RAG-based approach would be nonexistent or even negatively impact the results. To address this assumption, we tested several open-source LLMs on the ability of RAG to improve their success in answering multiple-choice questions (MCQ) in the medical subspecialty field of Nephrology. Unlike previous studies, we examined the effect of RAG in utilizing both relevant and adversarial background databases. We set up several open-source LLMs, including Llama 3, Phi-3, Mixtral 8x7b, Zephyr$\beta$, and Gemma 7B Instruct, in a zero-shot RAG pipeline. As adversarial sources of information, text from the Bible and a Random Words generated database were used for comparison. Our data show that most of the open-source LLMs improve their multiple-choice test-taking success as expected when incorporating relevant information vector databases. Surprisingly however, adversarial Bible text significantly improved the success of many LLMs and even random word text improved test taking ability of some of the models. In summary, our results demonstrate for the first time the countertintuitive ability of adversarial information datasets to improve the RAG-based LLM success.
Predicting Outcomes in Video Games with Long Short Term Memory Networks
Feb 24, 2024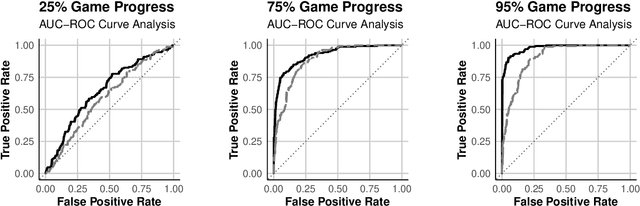
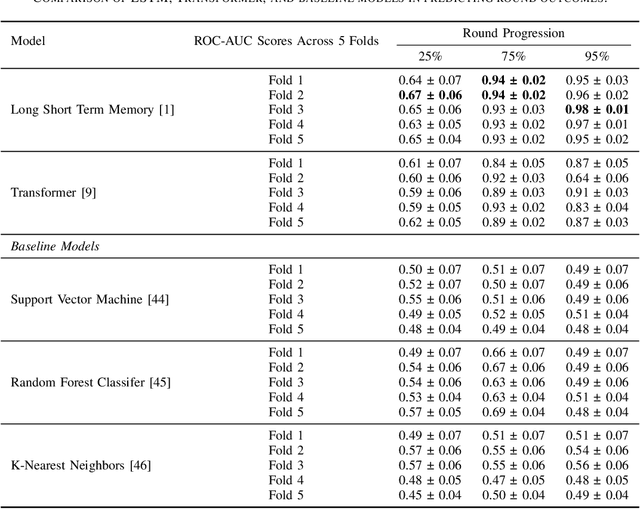
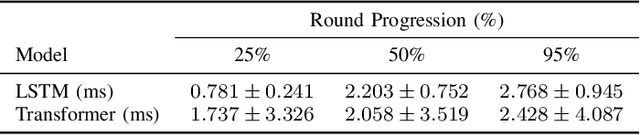
Forecasting winners in E-sports with real-time analytics has the potential to further engage audiences watching major tournament events. However, making such real-time predictions is challenging due to unpredictable variables within the game involving diverse player strategies and decision-making. Our work attempts to enhance audience engagement within video game tournaments by introducing a real-time method of predicting wins. Our Long Short Term Memory Network (LSTMs) based approach enables efficient predictions of win-lose outcomes by only using the health indicator of each player as a time series. As a proof of concept, we evaluate our model's performance within a classic, two-player arcade game, Super Street Fighter II Turbo. We also benchmark our method against state of the art methods for time series forecasting; i.e. Transformer models found in large language models (LLMs). Finally, we open-source our data set and code in hopes of furthering work in predictive analysis for arcade games.