 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Dec 12, 2024We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
Physically Feasible Semantic Segmentation
Aug 26, 2024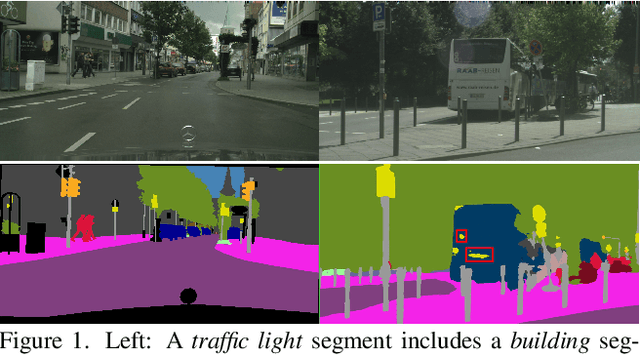
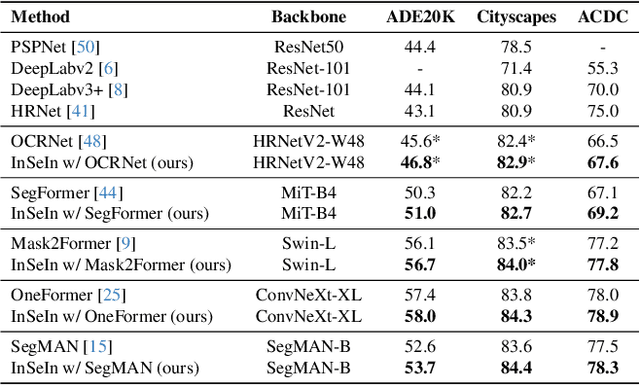
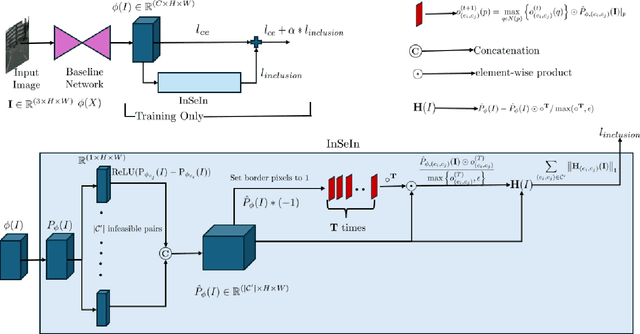

State-of-the-art semantic segmentation models are typically optimized in a data-driven fashion, minimizing solely per-pixel classification objectives on their training data. This purely data-driven paradigm often leads to absurd segmentations, especially when the domain of input images is shifted from the one encountered during training. For instance, state-of-the-art models may assign the label ``road'' to a segment which is located above a segment that is respectively labeled as ``sky'', although our knowledge of the physical world dictates that such a configuration is not feasible for images captured by forward-facing upright cameras. Our method, Physically Feasible Semantic Segmentation (PhyFea), extracts explicit physical constraints that govern spatial class relations from the training sets of semantic segmentation datasets and enforces a differentiable loss function that penalizes violations of these constraints to promote prediction feasibility. PhyFea yields significant performance improvements in mIoU over each state-of-the-art network we use as baseline across ADE20K, Cityscapes and ACDC, notably a $1.5\%$ improvement on ADE20K and a $2.1\%$ improvement on ACDC.