 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Dec 12, 2024We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
Condition-Aware Multimodal Fusion for Robust Semantic Perception of Driving Scenes
Oct 14, 2024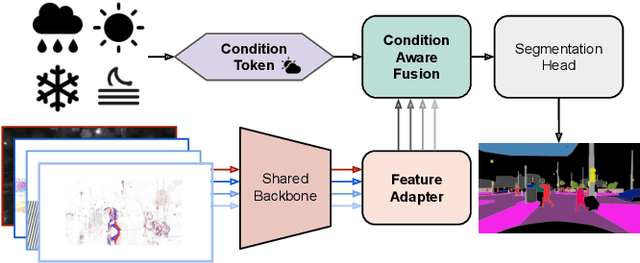
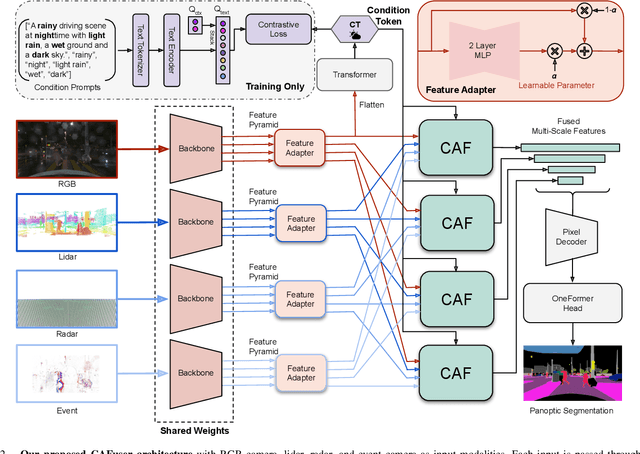
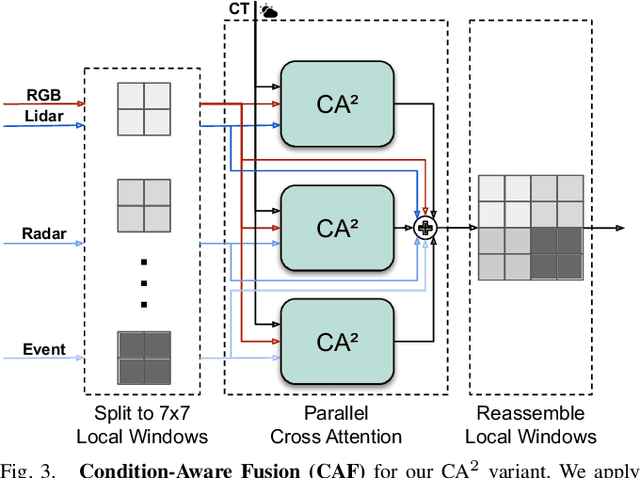
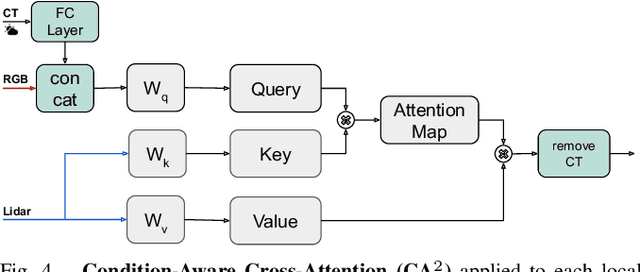
Leveraging multiple sensors is crucial for robust semantic perception in autonomous driving, as each sensor type has complementary strengths and weaknesses. However, existing sensor fusion methods often treat sensors uniformly across all conditions, leading to suboptimal performance. By contrast, we propose a novel, condition-aware multimodal fusion approach for robust semantic perception of driving scenes. Our method, CAFuser uses an RGB camera input to classify environmental conditions and generate a Condition Token that guides the fusion of multiple sensor modalities. We further newly introduce modality-specific feature adapters to align diverse sensor inputs into a shared latent space, enabling efficient integration with a single and shared pre-trained backbone. By dynamically adapting sensor fusion based on the actual condition, our model significantly improves robustness and accuracy, especially in adverse-condition scenarios. We set the new state of the art with CAFuser on the MUSES dataset with 59.7 PQ for multimodal panoptic segmentation and 78.2 mIoU for semantic segmentation, ranking first on the public benchmarks.
HRFuser: A Multi-resolution Sensor Fusion Architecture for 2D Object Detection
Jun 30, 2022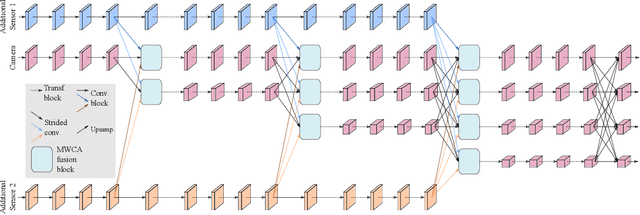
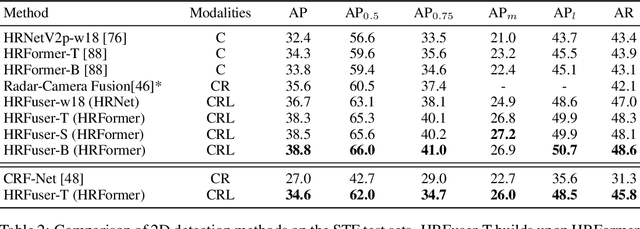
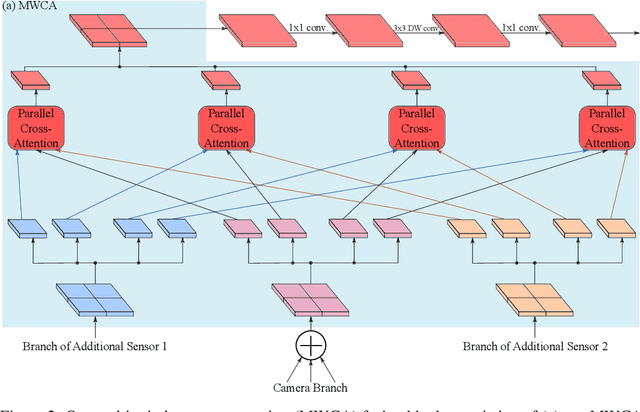

Besides standard cameras, autonomous vehicles typically include multiple additional sensors, such as lidars and radars, which help acquire richer information for perceiving the content of the driving scene. While several recent works focus on fusing certain pairs of sensors - such as camera and lidar or camera and radar - by using architectural components specific to the examined setting, a generic and modular sensor fusion architecture is missing from the literature. In this work, we focus on 2D object detection, a fundamental high-level task which is defined on the 2D image domain, and propose HRFuser, a multi-resolution sensor fusion architecture that scales straightforwardly to an arbitrary number of input modalities. The design of HRFuser is based on state-of-the-art high-resolution networks for image-only dense prediction and incorporates a novel multi-window cross-attention block as the means to perform fusion of multiple modalities at multiple resolutions. Even though cameras alone provide very informative features for 2D detection, we demonstrate via extensive experiments on the nuScenes and Seeing Through Fog datasets that our model effectively leverages complementary features from additional modalities, substantially improving upon camera-only performance and consistently outperforming state-of-the-art fusion methods for 2D detection both in normal and adverse conditions. The source code will be made publicly available.