 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondition-Aware Multimodal Fusion for Robust Semantic Perception of Driving Scenes
Paper and Code
Oct 14, 2024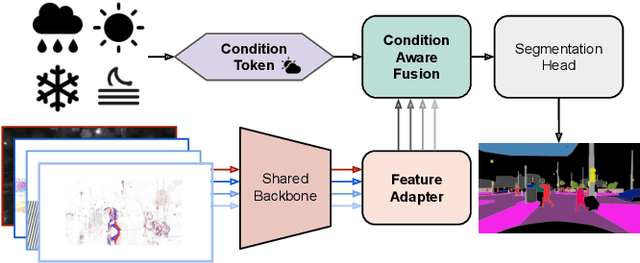
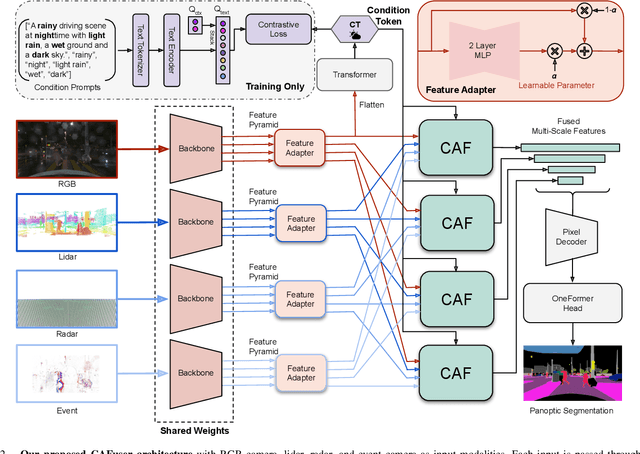
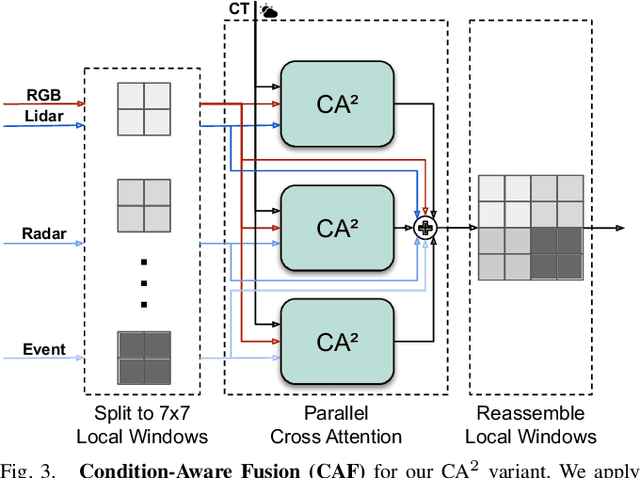
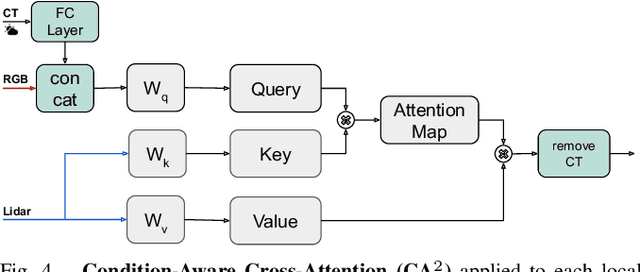
Leveraging multiple sensors is crucial for robust semantic perception in autonomous driving, as each sensor type has complementary strengths and weaknesses. However, existing sensor fusion methods often treat sensors uniformly across all conditions, leading to suboptimal performance. By contrast, we propose a novel, condition-aware multimodal fusion approach for robust semantic perception of driving scenes. Our method, CAFuser uses an RGB camera input to classify environmental conditions and generate a Condition Token that guides the fusion of multiple sensor modalities. We further newly introduce modality-specific feature adapters to align diverse sensor inputs into a shared latent space, enabling efficient integration with a single and shared pre-trained backbone. By dynamically adapting sensor fusion based on the actual condition, our model significantly improves robustness and accuracy, especially in adverse-condition scenarios. We set the new state of the art with CAFuser on the MUSES dataset with 59.7 PQ for multimodal panoptic segmentation and 78.2 mIoU for semantic segmentation, ranking first on the public benchmarks.