 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRFuser: A Multi-resolution Sensor Fusion Architecture for 2D Object Detection
Paper and Code
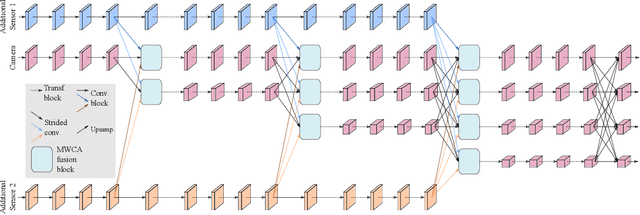
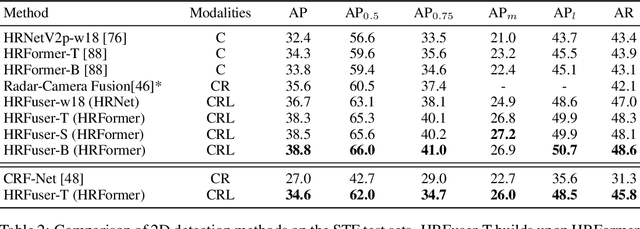
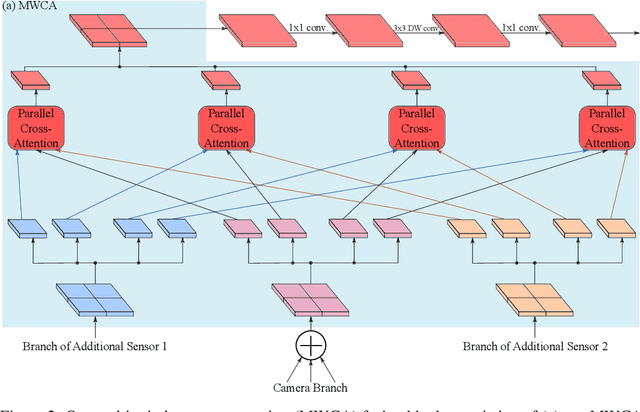

Besides standard cameras, autonomous vehicles typically include multiple additional sensors, such as lidars and radars, which help acquire richer information for perceiving the content of the driving scene. While several recent works focus on fusing certain pairs of sensors - such as camera and lidar or camera and radar - by using architectural components specific to the examined setting, a generic and modular sensor fusion architecture is missing from the literature. In this work, we focus on 2D object detection, a fundamental high-level task which is defined on the 2D image domain, and propose HRFuser, a multi-resolution sensor fusion architecture that scales straightforwardly to an arbitrary number of input modalities. The design of HRFuser is based on state-of-the-art high-resolution networks for image-only dense prediction and incorporates a novel multi-window cross-attention block as the means to perform fusion of multiple modalities at multiple resolutions. Even though cameras alone provide very informative features for 2D detection, we demonstrate via extensive experiments on the nuScenes and Seeing Through Fog datasets that our model effectively leverages complementary features from additional modalities, substantially improving upon camera-only performance and consistently outperforming state-of-the-art fusion methods for 2D detection both in normal and adverse conditions. The source code will be made publicly available.