 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapMem: Snapshot-based 3D Scene Memory for Embodied Exploration and Reasoning
Nov 23, 2024



Constructing compact and informative 3D scene representations is essential for effective embodied exploration and reasoning, especially in complex environments over long periods. Existing scene representations, such as object-centric 3D scene graphs, have significant limitations. They oversimplify spatial relationships by modeling scenes as individual objects, with inter-object relationships described by restrictive texts, making it difficult to answer queries that require nuanced spatial understanding. Furthermore, these representations lack natural mechanisms for active exploration and memory management, which hampers their application to lifelong autonomy. In this work, we propose SnapMem, a novel snapshot-based scene representation serving as 3D scene memory for embodied agents. SnapMem employs informative images, termed Memory Snapshots, to capture rich visual information of explored regions. It also integrates frontier-based exploration by introducing Frontier Snapshots-glimpses of unexplored areas-that enable agents to make informed exploration decisions by considering both known and potential new information. Meanwhile, to support lifelong memory in active exploration settings, we further present an incremental construction pipeline for SnapMem, as well as an effective memory retrieval technique for memory management. Experimental results on three benchmarks demonstrate that SnapMem significantly enhances agents' exploration and reasoning capabilities in 3D environments over extended periods, highlighting its potential for advancing applications in embodied AI.
Dormant: Defending against Pose-driven Human Image Animation
Sep 22, 2024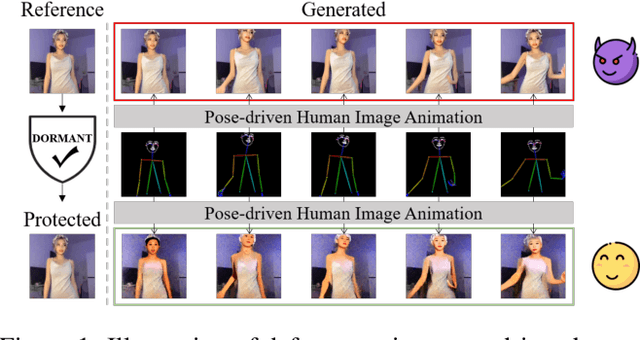
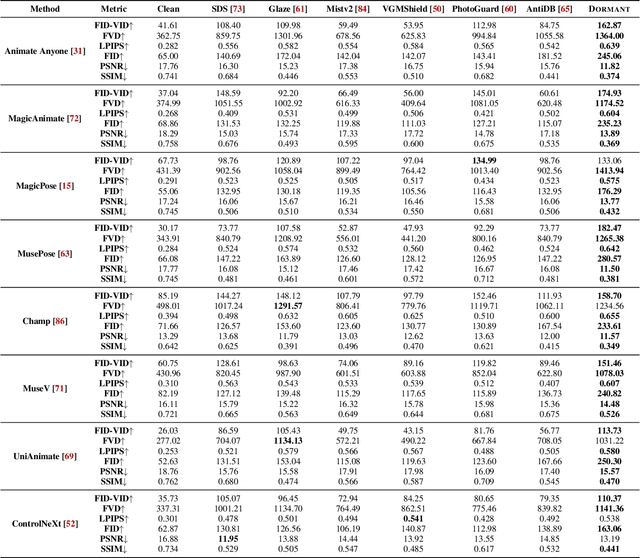
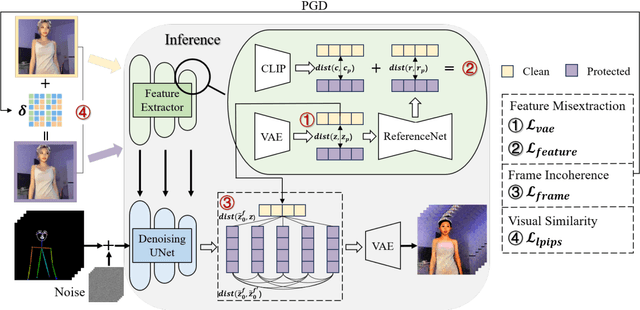
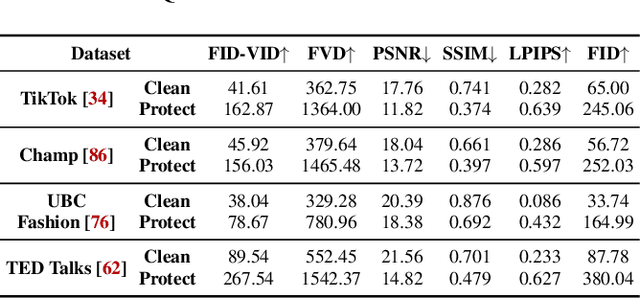
Pose-driven human image animation has achieved tremendous progress, enabling the generation of vivid and realistic human videos from just one single photo. However, it conversely exacerbates the risk of image misuse, as attackers may use one available image to create videos involving politics, violence and other illegal content. To counter this threat, we propose Dormant, a novel protection approach tailored to defend against pose-driven human image animation techniques. Dormant applies protective perturbation to one human image, preserving the visual similarity to the original but resulting in poor-quality video generation. The protective perturbation is optimized to induce misextraction of appearance features from the image and create incoherence among the generated video frames. Our extensive evaluation across 8 animation methods and 4 datasets demonstrates the superiority of Dormant over 6 baseline protection methods, leading to misaligned identities, visual distortions, noticeable artifacts, and inconsistent frames in the generated videos. Moreover, Dormant shows effectiveness on 6 real-world commercial services, even with fully black-box access.
JDT3D: Addressing the Gaps in LiDAR-Based Tracking-by-Attention
Jul 06, 2024



Tracking-by-detection (TBD) methods achieve state-of-the-art performance on 3D tracking benchmarks for autonomous driving. On the other hand, tracking-by-attention (TBA) methods have the potential to outperform TBD methods, particularly for long occlusions and challenging detection settings. This work investigates why TBA methods continue to lag in performance behind TBD methods using a LiDAR-based joint detector and tracker called JDT3D. Based on this analysis, we propose two generalizable methods to bridge the gap between TBD and TBA methods: track sampling augmentation and confidence-based query propagation. JDT3D is trained and evaluated on the nuScenes dataset, achieving 0.574 on the AMOTA metric on the nuScenes test set, outperforming all existing LiDAR-based TBA approaches by over 6%. Based on our results, we further discuss some potential challenges with the existing TBA model formulation to explain the continued gap in performance with TBD methods. The implementation of JDT3D can be found at the following link: https://github.com/TRAILab/JDT3D.
MEA-Defender: A Robust Watermark against Model Extraction Attack
Jan 26, 2024Recently, numerous highly-valuable Deep Neural Networks (DNNs) have been trained using deep learning algorithms. To protect the Intellectual Property (IP) of the original owners over such DNN models, backdoor-based watermarks have been extensively studied. However, most of such watermarks fail upon model extraction attack, which utilizes input samples to query the target model and obtains the corresponding outputs, thus training a substitute model using such input-output pairs. In this paper, we propose a novel watermark to protect IP of DNN models against model extraction, named MEA-Defender. In particular, we obtain the watermark by combining two samples from two source classes in the input domain and design a watermark loss function that makes the output domain of the watermark within that of the main task samples. Since both the input domain and the output domain of our watermark are indispensable parts of those of the main task samples, the watermark will be extracted into the stolen model along with the main task during model extraction. We conduct extensive experiments on four model extraction attacks, using five datasets and six models trained based on supervised learning and self-supervised learning algorithms. The experimental results demonstrate that MEA-Defender is highly robust against different model extraction attacks, and various watermark removal/detection approaches.
DataElixir: Purifying Poisoned Dataset to Mitigate Backdoor Attacks via Diffusion Models
Dec 20, 2023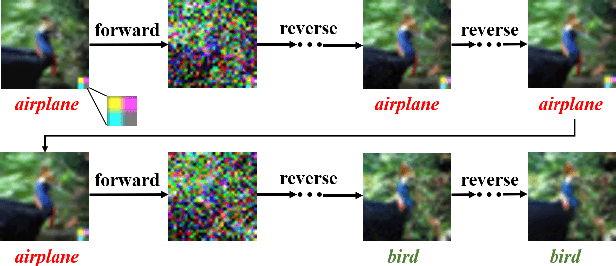
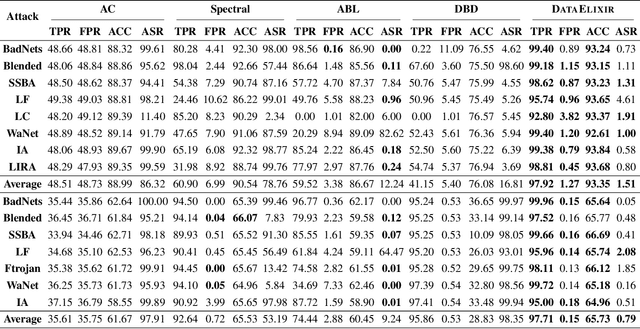

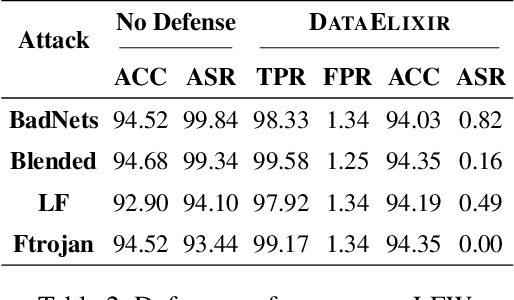
Dataset sanitization is a widely adopted proactive defense against poisoning-based backdoor attacks, aimed at filtering out and removing poisoned samples from training datasets. However, existing methods have shown limited efficacy in countering the ever-evolving trigger functions, and often leading to considerable degradation of benign accuracy. In this paper, we propose DataElixir, a novel sanitization approach tailored to purify poisoned datasets. We leverage diffusion models to eliminate trigger features and restore benign features, thereby turning the poisoned samples into benign ones. Specifically, with multiple iterations of the forward and reverse process, we extract intermediary images and their predicted labels for each sample in the original dataset. Then, we identify anomalous samples in terms of the presence of label transition of the intermediary images, detect the target label by quantifying distribution discrepancy, select their purified images considering pixel and feature distance, and determine their ground-truth labels by training a benign model. Experiments conducted on 9 popular attacks demonstrates that DataElixir effectively mitigates various complex attacks while exerting minimal impact on benign accuracy, surpassing the performance of baseline defense methods.
aUToLights: A Robust Multi-Camera Traffic Light Detection and Tracking System
May 15, 2023Following four successful years in the SAE AutoDrive Challenge Series I, the University of Toronto is participating in the Series II competition to develop a Level 4 autonomous passenger vehicle capable of handling various urban driving scenarios by 2025. Accurate detection of traffic lights and correct identification of their states is essential for safe autonomous operation in cities. Herein, we describe our recently-redesigned traffic light perception system for autonomous vehicles like the University of Toronto's self-driving car, Artemis. Similar to most traffic light perception systems, we rely primarily on camera-based object detectors. We deploy the YOLOv5 detector for bounding box regression and traffic light classification across multiple cameras and fuse the observations. To improve robustness, we incorporate priors from high-definition semantic maps and perform state filtering using hidden Markov models. We demonstrate a multi-camera, real time-capable traffic light perception pipeline that handles complex situations including multiple visible intersections, traffic light variations, temporary occlusion, and flashing light states. To validate our system, we collected and annotated a varied dataset incorporating flashing states and a range of occlusion types. Our results show superior performance in challenging real-world scenarios compared to single-frame, single-camera object detection.
DBIA: Data-free Backdoor Injection Attack against Transformer Networks
Nov 22, 2021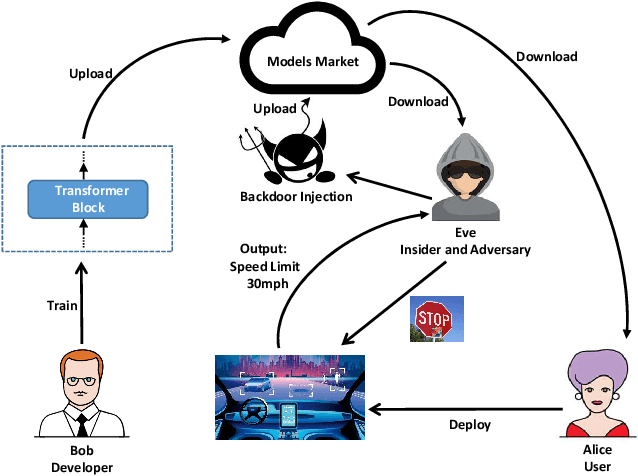

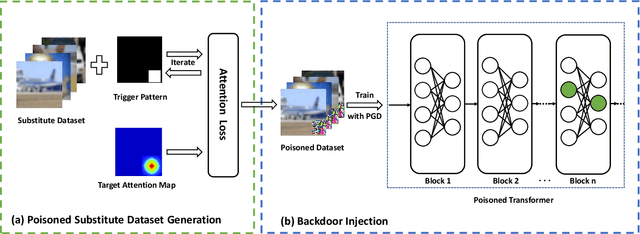
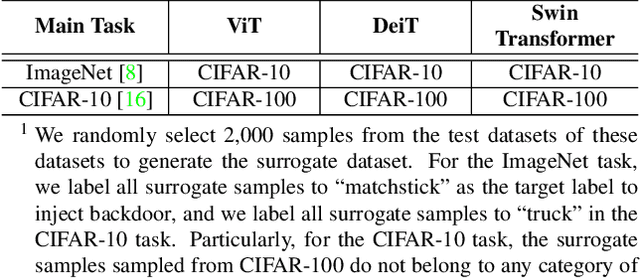
Recently, transformer architecture has demonstrated its significance in both Natural Language Processing (NLP) and Computer Vision (CV) tasks. Though other network models are known to be vulnerable to the backdoor attack, which embeds triggers in the model and controls the model behavior when the triggers are presented, little is known whether such an attack is still valid on the transformer models and if so, whether it can be done in a more cost-efficient manner. In this paper, we propose DBIA, a novel data-free backdoor attack against the CV-oriented transformer networks, leveraging the inherent attention mechanism of transformers to generate triggers and injecting the backdoor using the poisoned surrogate dataset. We conducted extensive experiments based on three benchmark transformers, i.e., ViT, DeiT and Swin Transformer, on two mainstream image classification tasks, i.e., CIFAR10 and ImageNet. The evaluation results demonstrate that, consuming fewer resources, our approach can embed backdoors with a high success rate and a low impact on the performance of the victim transformers. Our code is available at https://anonymous.4open.science/r/DBIA-825D.