 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAP-DIFF: Semantic Adversarial Patch Generation for Black-Box Face Recognition Models via Diffusion Models
Feb 27, 2025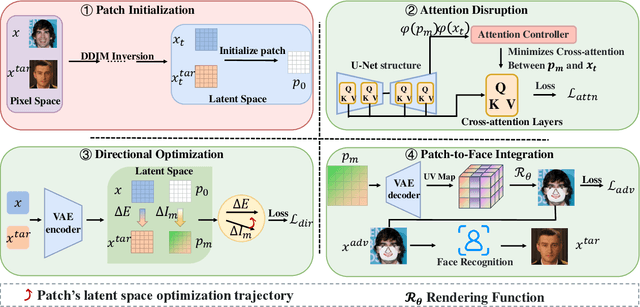
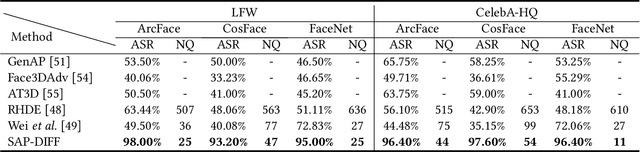

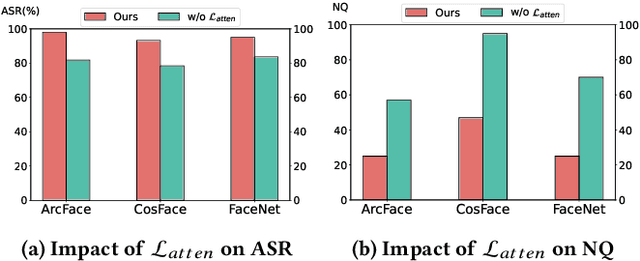
Given the need to evaluate the robustness of face recognition (FR) models, many efforts have focused on adversarial patch attacks that mislead FR models by introducing localized perturbations. Impersonation attacks are a significant threat because adversarial perturbations allow attackers to disguise themselves as legitimate users. This can lead to severe consequences, including data breaches, system damage, and misuse of resources. However, research on such attacks in FR remains limited. Existing adversarial patch generation methods exhibit limited efficacy in impersonation attacks due to (1) the need for high attacker capabilities, (2) low attack success rates, and (3) excessive query requirements. To address these challenges, we propose a novel method SAP-DIFF that leverages diffusion models to generate adversarial patches via semantic perturbations in the latent space rather than direct pixel manipulation. We introduce an attention disruption mechanism to generate features unrelated to the original face, facilitating the creation of adversarial samples and a directional loss function to guide perturbations toward the target identity feature space, thereby enhancing attack effectiveness and efficiency. Extensive experiments on popular FR models and datasets demonstrate that our method outperforms state-of-the-art approaches, achieving an average attack success rate improvement of 45.66% (all exceeding 40%), and a reduction in the number of queries by about 40% compared to the SOTA approach
Dormant: Defending against Pose-driven Human Image Animation
Sep 22, 2024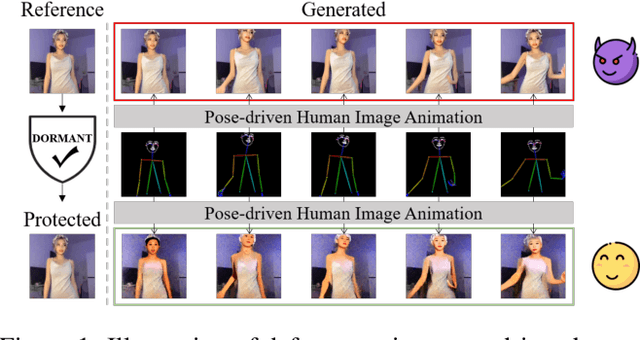
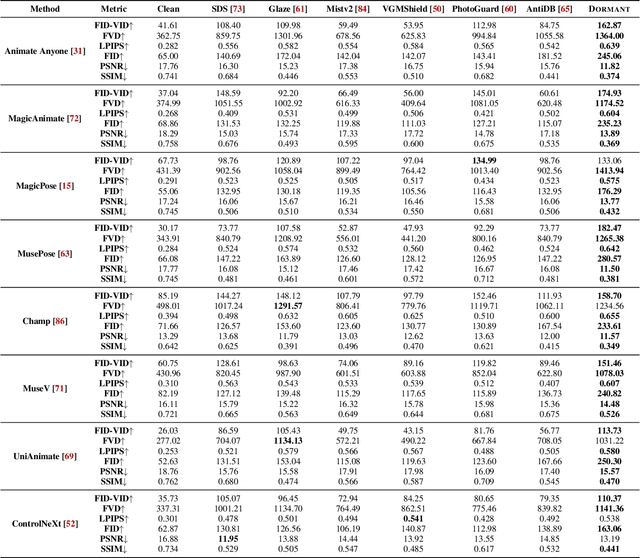
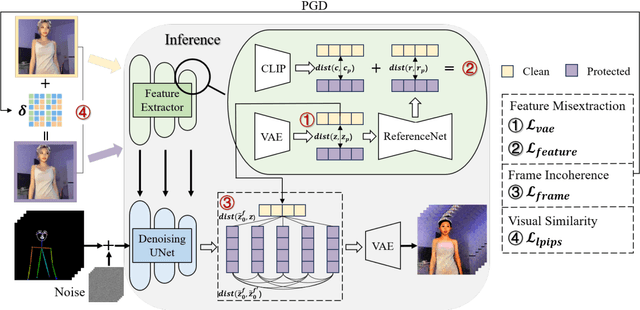
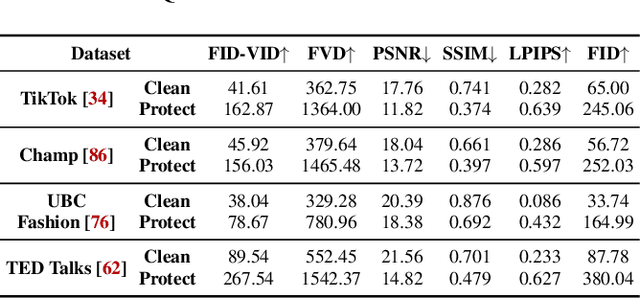
Pose-driven human image animation has achieved tremendous progress, enabling the generation of vivid and realistic human videos from just one single photo. However, it conversely exacerbates the risk of image misuse, as attackers may use one available image to create videos involving politics, violence and other illegal content. To counter this threat, we propose Dormant, a novel protection approach tailored to defend against pose-driven human image animation techniques. Dormant applies protective perturbation to one human image, preserving the visual similarity to the original but resulting in poor-quality video generation. The protective perturbation is optimized to induce misextraction of appearance features from the image and create incoherence among the generated video frames. Our extensive evaluation across 8 animation methods and 4 datasets demonstrates the superiority of Dormant over 6 baseline protection methods, leading to misaligned identities, visual distortions, noticeable artifacts, and inconsistent frames in the generated videos. Moreover, Dormant shows effectiveness on 6 real-world commercial services, even with fully black-box access.