 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Time Dynamic Landing of Quadrotors using Adaptive Unscented Kalman Filtering and Nonlinear Model Predictive Control
Jun 01, 2026This paper introduces an estimation and control framework for dynamic landing of multi-rotor uncrewed aerial vehicles on moving platforms. The proposed method integrates nonlinear model predictive control with a real-time minimum-jerk trajectory planner that enforces a prescribed touchdown time, enabling consistent timing during the terminal descent. To enhance robustness in the presence of time-varying sensing quality, we utilize an adaptive unscented kalman filter that updates the process and measurement noise statistics online. In addition, we provide a reference feasibility analysis showing that minimum-jerk references induce bounded thrust and torque commands under standard tracking hypotheses. The proposed framework is evaluated in simulation and hardware experiments, and it is shown to achieve repeatable landings and improved platform velocity prediction accuracy relative to EKF/UKF-based methods.
Contour Refinement using Discrete Diffusion in Low Data Regime
Feb 05, 2026Boundary detection of irregular and translucent objects is an important problem with applications in medical imaging, environmental monitoring and manufacturing, where many of these applications are plagued with scarce labeled data and low in situ computational resources. While recent image segmentation studies focus on segmentation mask alignment with ground-truth, the task of boundary detection remains understudied, especially in the low data regime. In this work, we present a lightweight discrete diffusion contour refinement pipeline for robust boundary detection in the low data regime. We use a Convolutional Neural Network(CNN) architecture with self-attention layers as the core of our pipeline, and condition on a segmentation mask, iteratively denoising a sparse contour representation. We introduce multiple novel adaptations for improved low-data efficacy and inference efficiency, including using a simplified diffusion process, a customized model architecture, and minimal post processing to produce a dense, isolated contour given a dataset of size <500 training images. Our method outperforms several SOTA baselines on the medical imaging dataset KVASIR, is competitive on HAM10K and our custom wildfire dataset, Smoke, while improving inference framerate by 3.5X.
Deployable and Generalizable Motion Prediction: Taxonomy, Open Challenges and Future Directions
May 14, 2025



Motion prediction, the anticipation of future agent states or scene evolution, is rooted in human cognition, bridging perception and decision-making. It enables intelligent systems, such as robots and self-driving cars, to act safely in dynamic, human-involved environments, and informs broader time-series reasoning challenges. With advances in methods, representations, and datasets, the field has seen rapid progress, reflected in quickly evolving benchmark results. Yet, when state-of-the-art methods are deployed in the real world, they often struggle to generalize to open-world conditions and fall short of deployment standards. This reveals a gap between research benchmarks, which are often idealized or ill-posed, and real-world complexity. To address this gap, this survey revisits the generalization and deployability of motion prediction models, with an emphasis on the applications of robotics, autonomous driving, and human motion. We first offer a comprehensive taxonomy of motion prediction methods, covering representations, modeling strategies, application domains, and evaluation protocols. We then study two key challenges: (1) how to push motion prediction models to be deployable to realistic deployment standards, where motion prediction does not act in a vacuum, but functions as one module of closed-loop autonomy stacks - it takes input from the localization and perception, and informs downstream planning and control. 2) how to generalize motion prediction models from limited seen scenarios/datasets to the open-world settings. Throughout the paper, we highlight critical open challenges to guide future work, aiming to recalibrate the community's efforts, fostering progress that is not only measurable but also meaningful for real-world applications.
ALLO: A Photorealistic Dataset and Data Generation Pipeline for Anomaly Detection During Robotic Proximity Operations in Lunar Orbit
Sep 30, 2024



NASA's forthcoming Lunar Gateway space station, which will be uncrewed most of the time, will need to operate with an unprecedented level of autonomy. Enhancing autonomy on the Gateway presents several unique challenges, one of which is to equip the Canadarm3, the Gateway's external robotic system, with the capability to perform worksite monitoring. Monitoring will involve using the arm's inspection cameras to detect any anomalies within the operating environment, a task complicated by the widely-varying lighting conditions in space. In this paper, we introduce the visual anomaly detection and localization task for space applications and establish a benchmark with our novel synthetic dataset called ALLO (for Anomaly Localization in Lunar Orbit). We develop a complete data generation pipeline to create ALLO, which we use to evaluate the performance of state-of-the-art visual anomaly detection algorithms. Given the low tolerance for risk during space operations and the lack of relevant data, we emphasize the need for novel, robust, and accurate anomaly detection methods to handle the challenging visual conditions found in lunar orbit and beyond.
Image-to-Lidar Relational Distillation for Autonomous Driving Data
Sep 01, 2024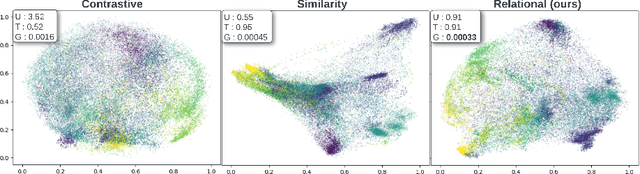

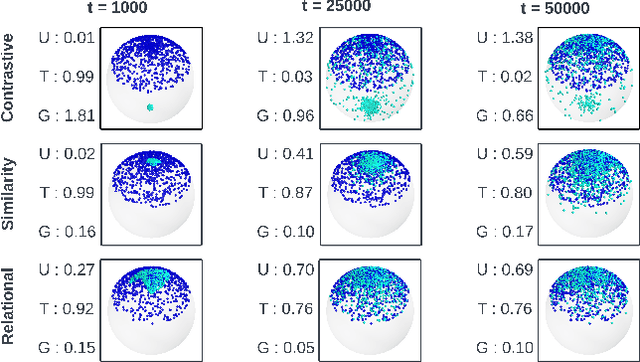
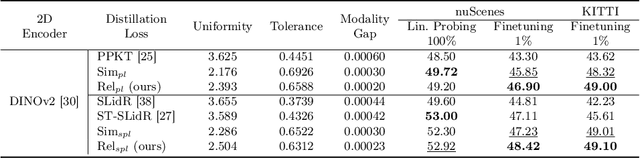
Pre-trained on extensive and diverse multi-modal datasets, 2D foundation models excel at addressing 2D tasks with little or no downstream supervision, owing to their robust representations. The emergence of 2D-to-3D distillation frameworks has extended these capabilities to 3D models. However, distilling 3D representations for autonomous driving datasets presents challenges like self-similarity, class imbalance, and point cloud sparsity, hindering the effectiveness of contrastive distillation, especially in zero-shot learning contexts. Whereas other methodologies, such as similarity-based distillation, enhance zero-shot performance, they tend to yield less discriminative representations, diminishing few-shot performance. We investigate the gap in structure between the 2D and the 3D representations that result from state-of-the-art distillation frameworks and reveal a significant mismatch between the two. Additionally, we demonstrate that the observed structural gap is negatively correlated with the efficacy of the distilled representations on zero-shot and few-shot 3D semantic segmentation. To bridge this gap, we propose a relational distillation framework enforcing intra-modal and cross-modal constraints, resulting in distilled 3D representations that closely capture the structure of the 2D representation. This alignment significantly enhances 3D representation performance over those learned through contrastive distillation in zero-shot segmentation tasks. Furthermore, our relational loss consistently improves the quality of 3D representations in both in-distribution and out-of-distribution few-shot segmentation tasks, outperforming approaches that rely on the similarity loss.
JDT3D: Addressing the Gaps in LiDAR-Based Tracking-by-Attention
Jul 06, 2024



Tracking-by-detection (TBD) methods achieve state-of-the-art performance on 3D tracking benchmarks for autonomous driving. On the other hand, tracking-by-attention (TBA) methods have the potential to outperform TBD methods, particularly for long occlusions and challenging detection settings. This work investigates why TBA methods continue to lag in performance behind TBD methods using a LiDAR-based joint detector and tracker called JDT3D. Based on this analysis, we propose two generalizable methods to bridge the gap between TBD and TBA methods: track sampling augmentation and confidence-based query propagation. JDT3D is trained and evaluated on the nuScenes dataset, achieving 0.574 on the AMOTA metric on the nuScenes test set, outperforming all existing LiDAR-based TBA approaches by over 6%. Based on our results, we further discuss some potential challenges with the existing TBA model formulation to explain the continued gap in performance with TBD methods. The implementation of JDT3D can be found at the following link: https://github.com/TRAILab/JDT3D.
SWTrack: Multiple Hypothesis Sliding Window 3D Multi-Object Tracking
Feb 27, 2024Modern robotic systems are required to operate in dense dynamic environments, requiring highly accurate real-time track identification and estimation. For 3D multi-object tracking, recent approaches process a single measurement frame recursively with greedy association and are prone to errors in ambiguous association decisions. Our method, Sliding Window Tracker (SWTrack), yields more accurate association and state estimation by batch processing many frames of sensor data while being capable of running online in real-time. The most probable track associations are identified by evaluating all possible track hypotheses across the temporal sliding window. A novel graph optimization approach is formulated to solve the multidimensional assignment problem with lifted graph edges introduced to account for missed detections and graph sparsity enforced to retain real-time efficiency. We evaluate our SWTrack implementation$^{2}$ on the NuScenes autonomous driving dataset to demonstrate improved tracking performance.
Class Instance Balanced Learning for Long-Tailed Classification
Jul 11, 2023The long-tailed image classification task remains important in the development of deep neural networks as it explicitly deals with large imbalances in the class frequencies of the training data. While uncommon in engineered datasets, this imbalance is almost always present in real-world data. Previous approaches have shown that combining cross-entropy and contrastive learning can improve performance on the long-tailed task, but they do not explore the tradeoff between head and tail classes. We propose a novel class instance balanced loss (CIBL), which reweights the relative contributions of a cross-entropy and a contrastive loss as a function of the frequency of class instances in the training batch. This balancing favours the contrastive loss for more common classes, leading to a learned classifier with a more balanced performance across all class frequencies. Furthermore, increasing the relative weight on the contrastive head shifts performance from common (head) to rare (tail) classes, allowing the user to skew the performance towards these classes if desired. We also show that changing the linear classifier head with a cosine classifier yields a network that can be trained to similar performance in substantially fewer epochs. We obtain competitive results on both CIFAR-100-LT and ImageNet-LT.
ProPanDL: A Modular Architecture for Uncertainty-Aware Panoptic Segmentation
Apr 17, 2023We introduce ProPanDL, a family of networks capable of uncertainty-aware panoptic segmentation. Unlike existing segmentation methods, ProPanDL is capable of estimating full probability distributions for both the semantic and spatial aspects of panoptic segmentation. We implement and evaluate ProPanDL variants capable of estimating both parametric (Variance Network) and parameter-free (SampleNet) distributions quantifying pixel-wise spatial uncertainty. We couple these approaches with two methods (Temperature Scaling and Evidential Deep Learning) for semantic uncertainty estimation. To evaluate the uncertainty-aware panoptic segmentation task, we address limitations with existing approaches by proposing new metrics that enable separate evaluation of spatial and semantic uncertainty. We additionally propose the use of the energy score, a proper scoring rule, for more robust evaluation of spatial output distributions. Using these metrics, we conduct an extensive evaluation of ProPanDL variants. Our results demonstrate that ProPanDL is capable of estimating well-calibrated and meaningful output distributions while still retaining strong performance on the base panoptic segmentation task.
LiDAR-MIMO: Efficient Uncertainty Estimation for LiDAR-based 3D Object Detection
Jun 01, 2022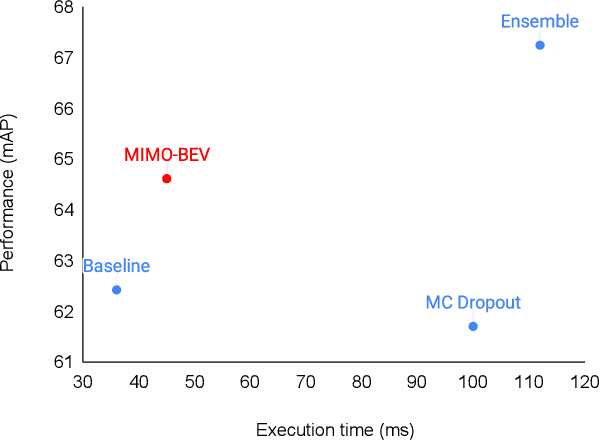



The estimation of uncertainty in robotic vision, such as 3D object detection, is an essential component in developing safe autonomous systems aware of their own performance. However, the deployment of current uncertainty estimation methods in 3D object detection remains challenging due to timing and computational constraints. To tackle this issue, we propose LiDAR-MIMO, an adaptation of the multi-input multi-output (MIMO) uncertainty estimation method to the LiDAR-based 3D object detection task. Our method modifies the original MIMO by performing multi-input at the feature level to ensure the detection, uncertainty estimation, and runtime performance benefits are retained despite the limited capacity of the underlying detector and the large computational costs of point cloud processing. We compare LiDAR-MIMO with MC dropout and ensembles as baselines and show comparable uncertainty estimation results with only a small number of output heads. Further, LiDAR-MIMO can be configured to be twice as fast as MC dropout and ensembles, while achieving higher mAP than MC dropout and approaching that of ensembles.