 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADet: Multi-frame LiDAR 3D Object Detection using Variable Aggregation
Nov 20, 2024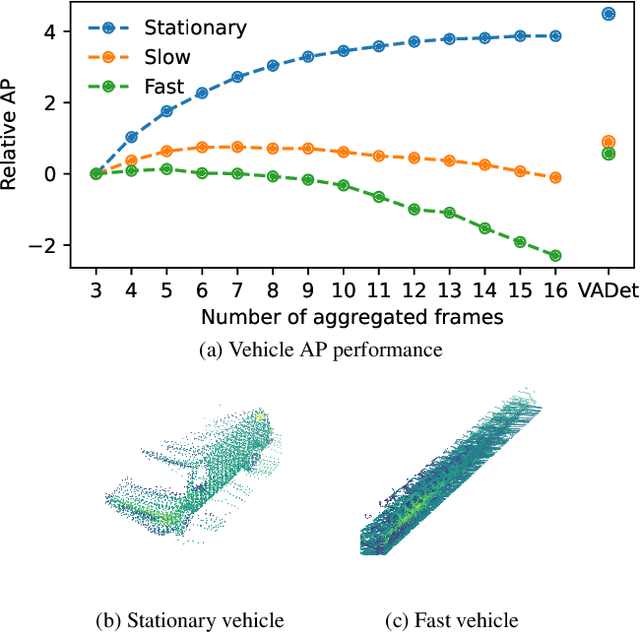


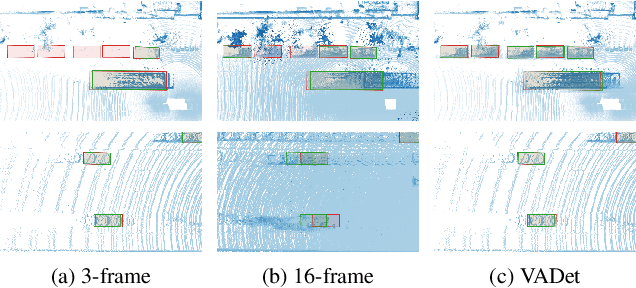
Input aggregation is a simple technique used by state-of-the-art LiDAR 3D object detectors to improve detection. However, increasing aggregation is known to have diminishing returns and even performance degradation, due to objects responding differently to the number of aggregated frames. To address this limitation, we propose an efficient adaptive method, which we call Variable Aggregation Detection (VADet). Instead of aggregating the entire scene using a fixed number of frames, VADet performs aggregation per object, with the number of frames determined by an object's observed properties, such as speed and point density. VADet thus reduces the inherent trade-offs of fixed aggregation and is not architecture specific. To demonstrate its benefits, we apply VADet to three popular single-stage detectors and achieve state-of-the-art performance on the Waymo dataset.
SOAP: Cross-sensor Domain Adaptation for 3D Object Detection Using Stationary Object Aggregation Pseudo-labelling
Jan 08, 2024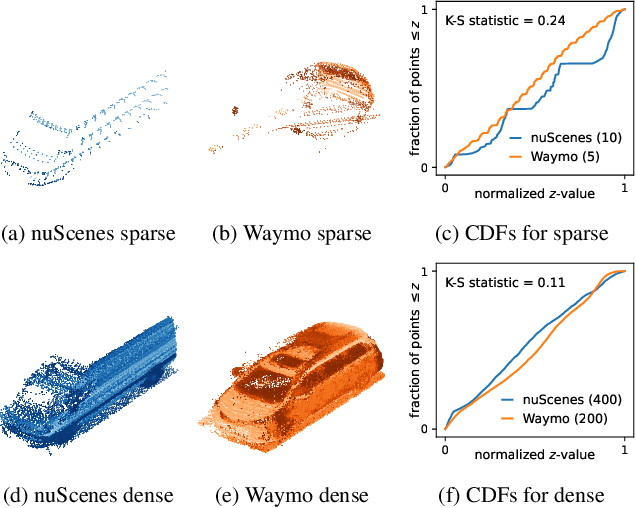

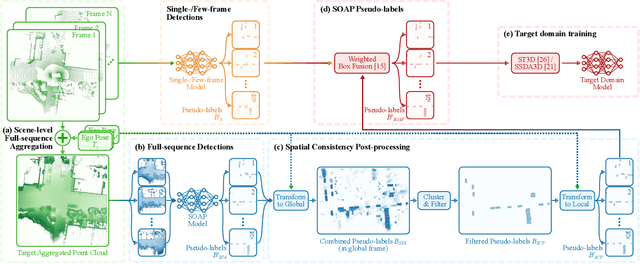
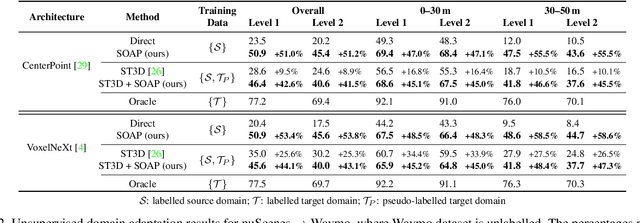
We consider the problem of cross-sensor domain adaptation in the context of LiDAR-based 3D object detection and propose Stationary Object Aggregation Pseudo-labelling (SOAP) to generate high quality pseudo-labels for stationary objects. In contrast to the current state-of-the-art in-domain practice of aggregating just a few input scans, SOAP aggregates entire sequences of point clouds at the input level to reduce the sensor domain gap. Then, by means of what we call quasi-stationary training and spatial consistency post-processing, the SOAP model generates accurate pseudo-labels for stationary objects, closing a minimum of 30.3% domain gap compared to few-frame detectors. Our results also show that state-of-the-art domain adaptation approaches can achieve even greater performance in combination with SOAP, in both the unsupervised and semi-supervised settings.
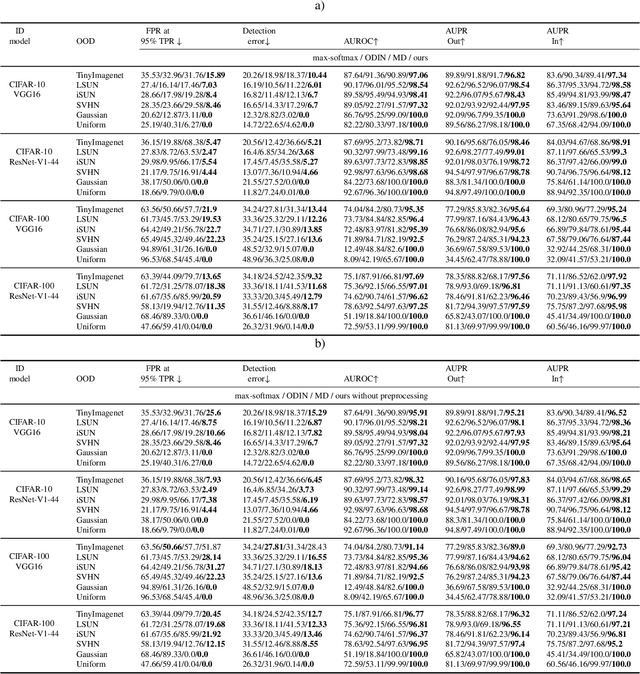
Out-of-Distribution Detection for LiDAR-based 3D Object Detection
Sep 28, 2022



3D object detection is an essential part of automated driving, and deep neural networks (DNNs) have achieved state-of-the-art performance for this task. However, deep models are notorious for assigning high confidence scores to out-of-distribution (OOD) inputs, that is, inputs that are not drawn from the training distribution. Detecting OOD inputs is challenging and essential for the safe deployment of models. OOD detection has been studied extensively for the classification task, but it has not received enough attention for the object detection task, specifically LiDAR-based 3D object detection. In this paper, we focus on the detection of OOD inputs for LiDAR-based 3D object detection. We formulate what OOD inputs mean for object detection and propose to adapt several OOD detection methods for object detection. We accomplish this by our proposed feature extraction method. To evaluate OOD detection methods, we develop a simple but effective technique of generating OOD objects for a given object detection model. Our evaluation based on the KITTI dataset shows that different OOD detection methods have biases toward detecting specific OOD objects. It emphasizes the importance of combined OOD detection methods and more research in this direction.
LiDAR-MIMO: Efficient Uncertainty Estimation for LiDAR-based 3D Object Detection
Jun 01, 2022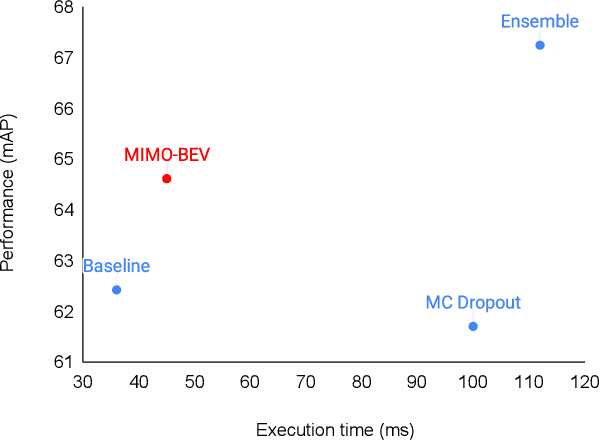



The estimation of uncertainty in robotic vision, such as 3D object detection, is an essential component in developing safe autonomous systems aware of their own performance. However, the deployment of current uncertainty estimation methods in 3D object detection remains challenging due to timing and computational constraints. To tackle this issue, we propose LiDAR-MIMO, an adaptation of the multi-input multi-output (MIMO) uncertainty estimation method to the LiDAR-based 3D object detection task. Our method modifies the original MIMO by performing multi-input at the feature level to ensure the detection, uncertainty estimation, and runtime performance benefits are retained despite the limited capacity of the underlying detector and the large computational costs of point cloud processing. We compare LiDAR-MIMO with MC dropout and ensembles as baselines and show comparable uncertainty estimation results with only a small number of output heads. Further, LiDAR-MIMO can be configured to be twice as fast as MC dropout and ensembles, while achieving higher mAP than MC dropout and approaching that of ensembles.
The missing link: Developing a safety case for perception components in automated driving
Aug 30, 2021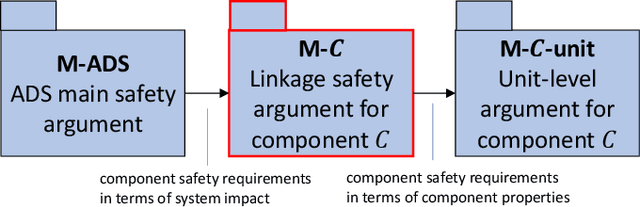
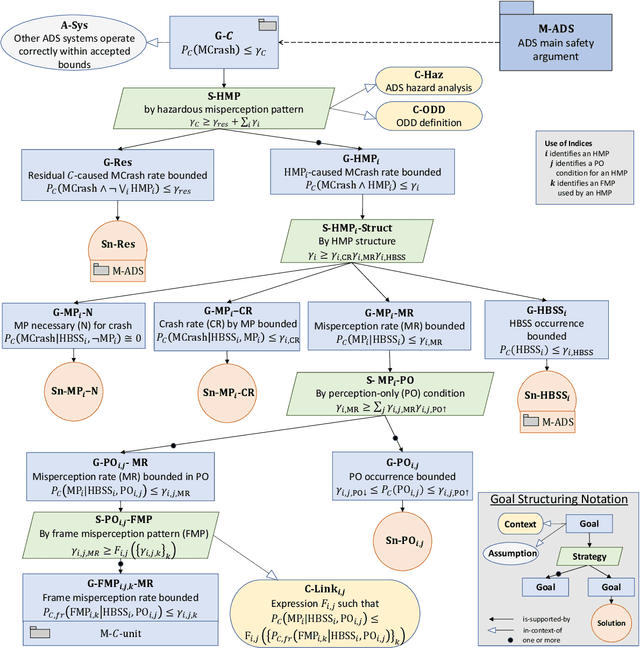
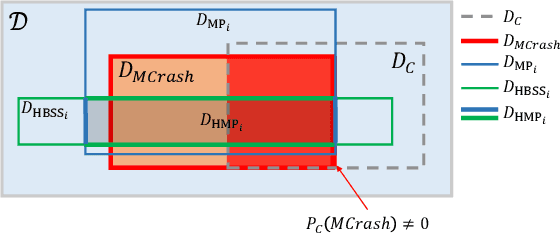
Safety assurance is a central concern for the development and societal acceptance of automated driving (AD) systems. Perception is a key aspect of AD that relies heavily on Machine Learning (ML). Despite the known challenges with the safety assurance of ML-based components, proposals have recently emerged for unit-level safety cases addressing these components. Unfortunately, AD safety cases express safety requirements at the system-level and these efforts are missing the critical linking argument connecting safety requirements at the system-level to component performance requirements at the unit-level. In this paper, we propose a generic template for such a linking argument specifically tailored for perception components. The template takes a deductive and formal approach to define strong traceability between levels. We demonstrate the applicability of the template with a detailed case study and discuss its use as a tool to support incremental development of perception components.
The Effect of Optimization Methods on the Robustness of Out-of-Distribution Detection Approaches
Jun 25, 2020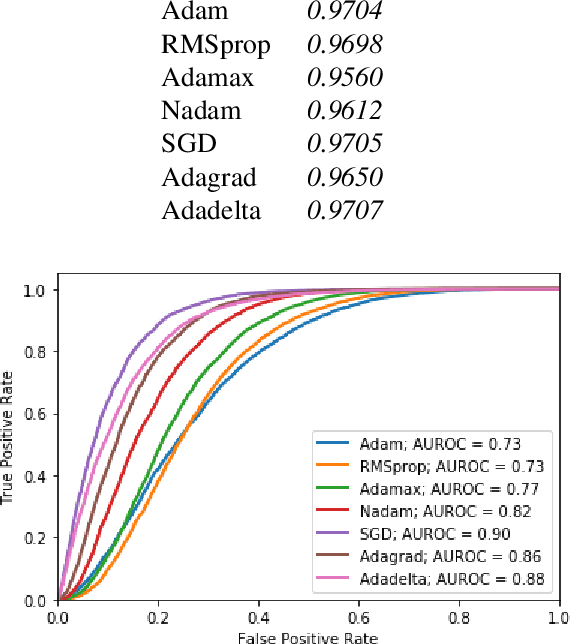

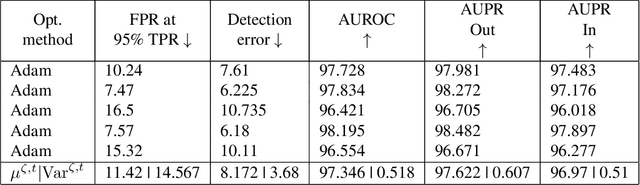
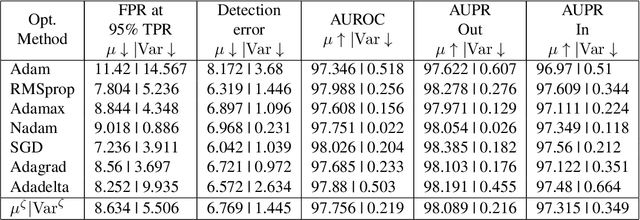
Deep neural networks (DNNs) have become the de facto learning mechanism in different domains. Their tendency to perform unreliably on out-of-distribution (OOD) inputs hinders their adoption in critical domains. Several approaches have been proposed for detecting OOD inputs. However, existing approaches still lack robustness. In this paper, we shed light on the robustness of OOD detection (OODD) approaches by revealing the important role of optimization methods. We show that OODD approaches are sensitive to the type of optimization method used during training deep models. Optimization methods can provide different solutions to a non-convex problem and so these solutions may or may not satisfy the assumptions (e.g., distributions of deep features) made by OODD approaches. Furthermore, we propose a robustness score that takes into account the role of optimization methods. This provides a sound way to compare OODD approaches. In addition to comparing several OODD approaches using our proposed robustness score, we demonstrate that some optimization methods provide better solutions for OODD approaches.
Detecting Out-of-Distribution Inputs in Deep Neural Networks Using an Early-Layer Output
Oct 23, 2019

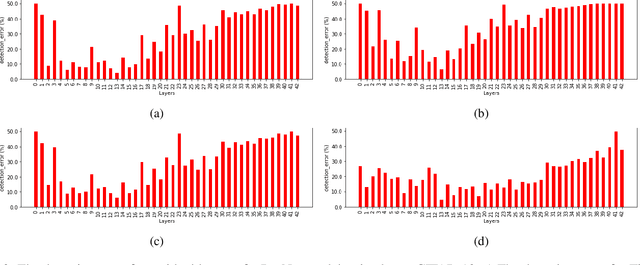
Deep neural networks achieve superior performance in challenging tasks such as image classification. However, deep classifiers tend to incorrectly classify out-of-distribution (OOD) inputs, which are inputs that do not belong to the classifier training distribution. Several approaches have been proposed to detect OOD inputs, but the detection task is still an ongoing challenge. In this paper, we propose a new OOD detection approach that can be easily applied to an existing classifier and does not need to have access to OOD samples. The detector is a one-class classifier trained on the output of an early layer of the original classifier fed with its original training set. We apply our approach to several low- and high-dimensional datasets and compare it to the state-of-the-art detection approaches. Our approach achieves substantially better results over multiple metrics.
Out-of-distribution Detection in Classifiers via Generation
Oct 09, 2019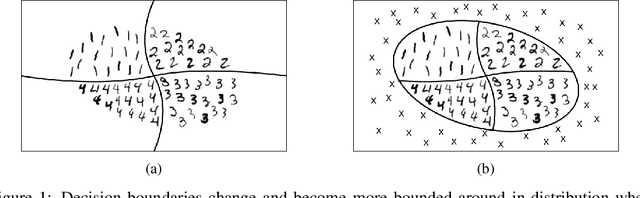
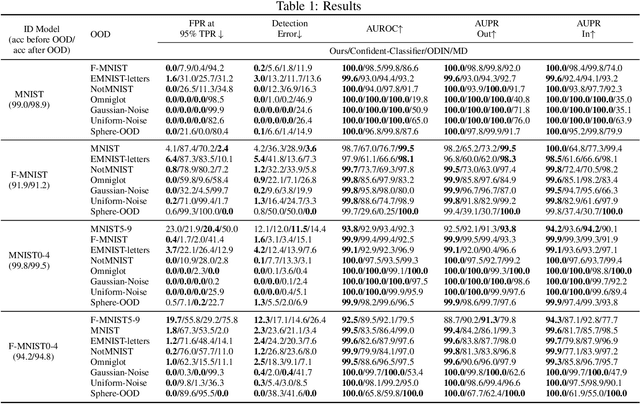
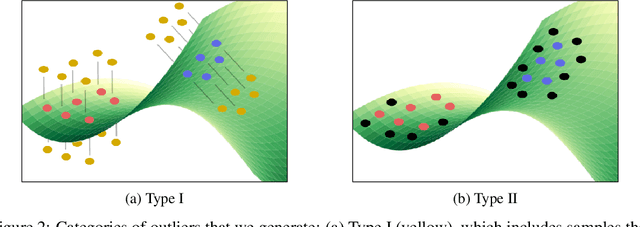
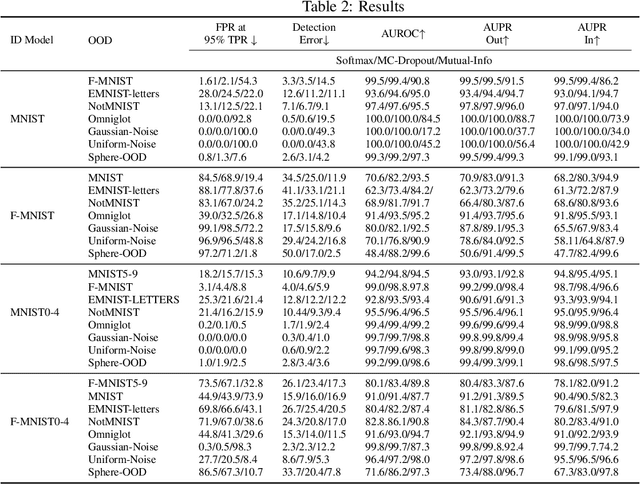
By design, discriminatively trained neural network classifiers produce reliable predictions only for in-distribution samples. For their real-world deployments, detecting out-of-distribution (OOD) samples is essential. Assuming OOD to be outside the closed boundary of in-distribution, typical neural classifiers do not contain the knowledge of this boundary for OOD detection during inference. There have been recent approaches to instill this knowledge in classifiers by explicitly training the classifier with OOD samples close to the in-distribution boundary. However, these generated samples fail to cover the entire in-distribution boundary effectively, thereby resulting in a sub-optimal OOD detector. In this paper, we analyze the feasibility of such approaches by investigating the complexity of producing such "effective" OOD samples. We also propose a novel algorithm to generate such samples using a manifold learning network (e.g., variational autoencoder) and then train an n+1 classifier for OOD detection, where the $n+1^{th}$ class represents the OOD samples. We compare our approach against several recent classifier-based OOD detectors on MNIST and Fashion-MNIST datasets. Overall the proposed approach consistently performs better than the others.
Analysis of Confident-Classifiers for Out-of-distribution Detection
Apr 27, 2019
Discriminatively trained neural classifiers can be trusted, only when the input data comes from the training distribution (in-distribution). Therefore, detecting out-of-distribution (OOD) samples is very important to avoid classification errors. In the context of OOD detection for image classification, one of the recent approaches proposes training a classifier called "confident-classifier" by minimizing the standard cross-entropy loss on in-distribution samples and minimizing the KL divergence between the predictive distribution of OOD samples in the low-density regions of in-distribution and the uniform distribution (maximizing the entropy of the outputs). Thus, the samples could be detected as OOD if they have low confidence or high entropy. In this paper, we analyze this setting both theoretically and experimentally. We conclude that the resulting confident-classifier still yields arbitrarily high confidence for OOD samples far away from the in-distribution. We instead suggest training a classifier by adding an explicit "reject" class for OOD samples.
Improving Reconstruction Autoencoder Out-of-distribution Detection with Mahalanobis Distance
Dec 06, 2018

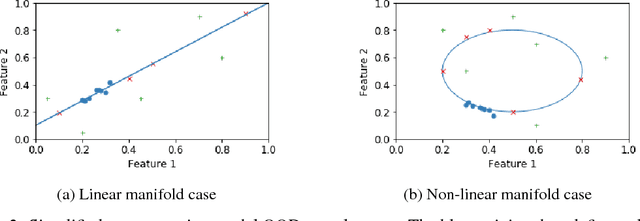
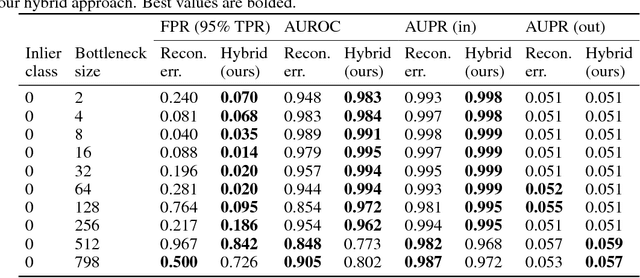
There is an increasingly apparent need for validating the classifications made by deep learning systems in safety-critical applications like autonomous vehicle systems. A number of recent papers have proposed methods for detecting anomalous image data that appear different from known inlier data samples, including reconstruction-based autoencoders. Autoencoders optimize the compression of input data to a latent space of a dimensionality smaller than the original input and attempt to accurately reconstruct the input using that compressed representation. Since the latent vector is optimized to capture the salient features from the inlier class only, it is commonly assumed that images of objects from outside of the training class cannot effectively be compressed and reconstructed. Some thus consider reconstruction error as a kind of novelty measure. Here we suggest that reconstruction-based approaches fail to capture particular anomalies that lie far from known inlier samples in latent space but near the latent dimension manifold defined by the parameters of the model. We propose incorporating the Mahalanobis distance in latent space to better capture these out-of-distribution samples and our results show that this method often improves performance over the baseline approach.