 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADet: Multi-frame LiDAR 3D Object Detection using Variable Aggregation
Paper and Code
Nov 20, 2024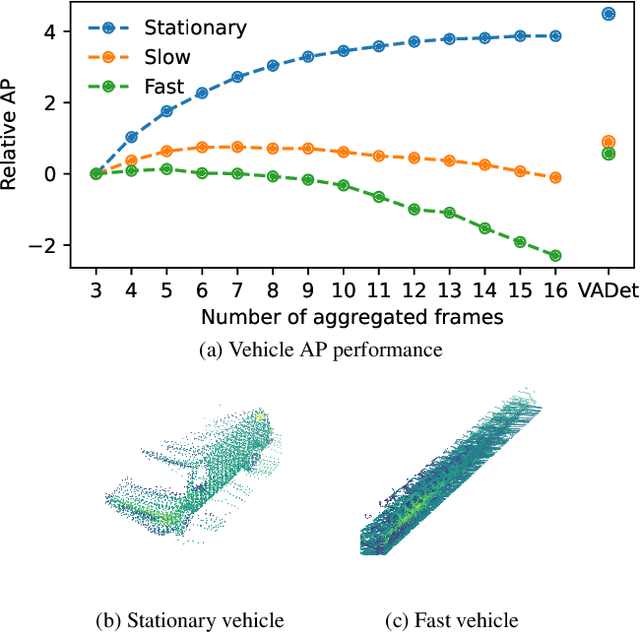


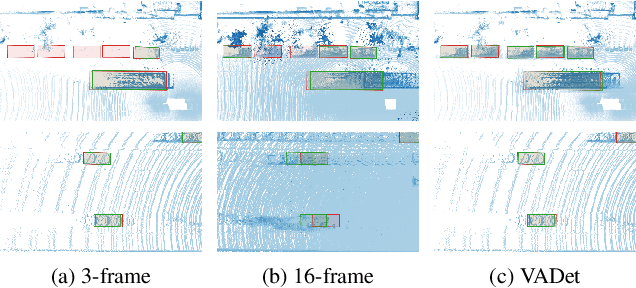
Input aggregation is a simple technique used by state-of-the-art LiDAR 3D object detectors to improve detection. However, increasing aggregation is known to have diminishing returns and even performance degradation, due to objects responding differently to the number of aggregated frames. To address this limitation, we propose an efficient adaptive method, which we call Variable Aggregation Detection (VADet). Instead of aggregating the entire scene using a fixed number of frames, VADet performs aggregation per object, with the number of frames determined by an object's observed properties, such as speed and point density. VADet thus reduces the inherent trade-offs of fixed aggregation and is not architecture specific. To demonstrate its benefits, we apply VADet to three popular single-stage detectors and achieve state-of-the-art performance on the Waymo dataset.