 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-distribution Detection in Classifiers via Generation
Oct 09, 2019
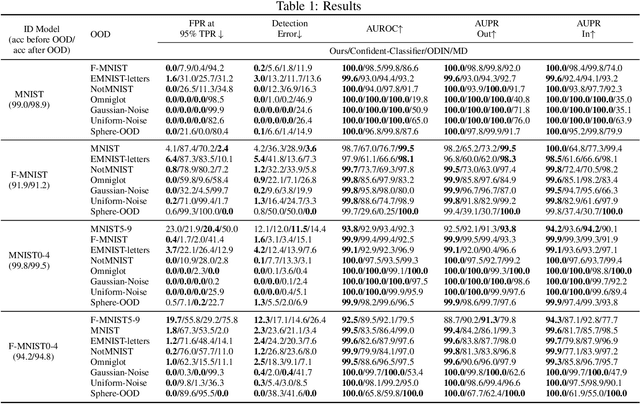
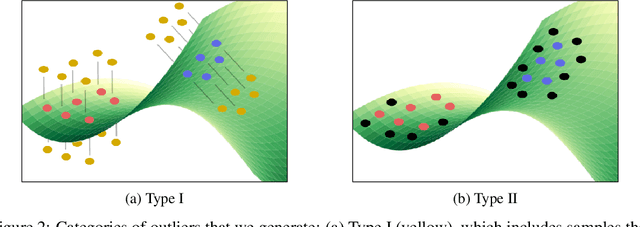
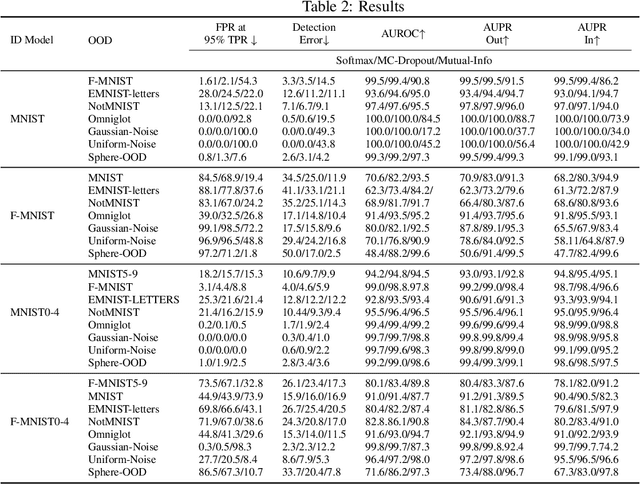
By design, discriminatively trained neural network classifiers produce reliable predictions only for in-distribution samples. For their real-world deployments, detecting out-of-distribution (OOD) samples is essential. Assuming OOD to be outside the closed boundary of in-distribution, typical neural classifiers do not contain the knowledge of this boundary for OOD detection during inference. There have been recent approaches to instill this knowledge in classifiers by explicitly training the classifier with OOD samples close to the in-distribution boundary. However, these generated samples fail to cover the entire in-distribution boundary effectively, thereby resulting in a sub-optimal OOD detector. In this paper, we analyze the feasibility of such approaches by investigating the complexity of producing such "effective" OOD samples. We also propose a novel algorithm to generate such samples using a manifold learning network (e.g., variational autoencoder) and then train an n+1 classifier for OOD detection, where the $n+1^{th}$ class represents the OOD samples. We compare our approach against several recent classifier-based OOD detectors on MNIST and Fashion-MNIST datasets. Overall the proposed approach consistently performs better than the others.
Analysis of Confident-Classifiers for Out-of-distribution Detection
Apr 27, 2019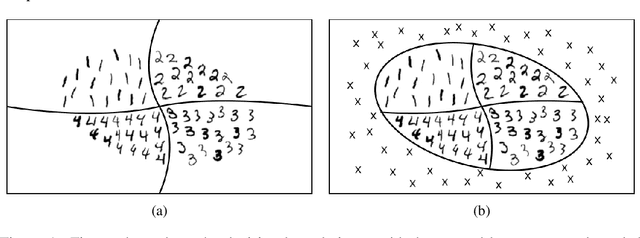
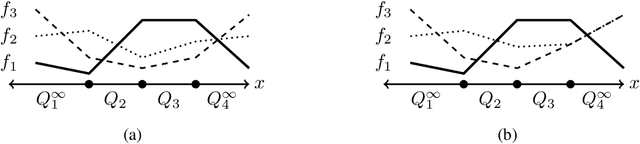
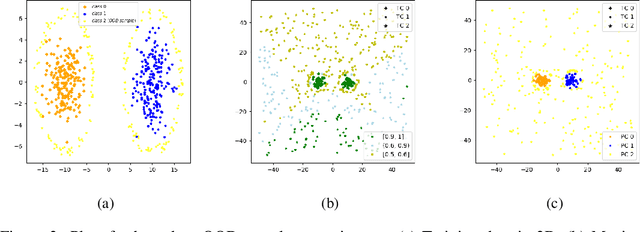
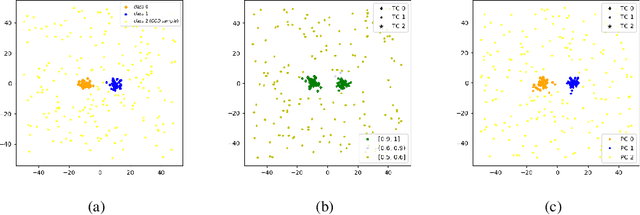
Discriminatively trained neural classifiers can be trusted, only when the input data comes from the training distribution (in-distribution). Therefore, detecting out-of-distribution (OOD) samples is very important to avoid classification errors. In the context of OOD detection for image classification, one of the recent approaches proposes training a classifier called "confident-classifier" by minimizing the standard cross-entropy loss on in-distribution samples and minimizing the KL divergence between the predictive distribution of OOD samples in the low-density regions of in-distribution and the uniform distribution (maximizing the entropy of the outputs). Thus, the samples could be detected as OOD if they have low confidence or high entropy. In this paper, we analyze this setting both theoretically and experimentally. We conclude that the resulting confident-classifier still yields arbitrarily high confidence for OOD samples far away from the in-distribution. We instead suggest training a classifier by adding an explicit "reject" class for OOD samples.
Improving Reconstruction Autoencoder Out-of-distribution Detection with Mahalanobis Distance
Dec 06, 2018

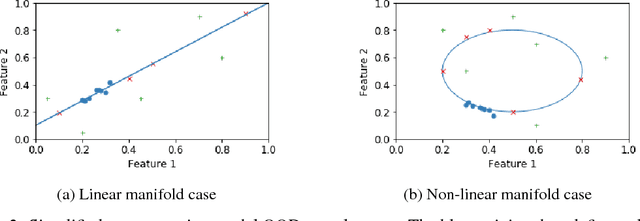
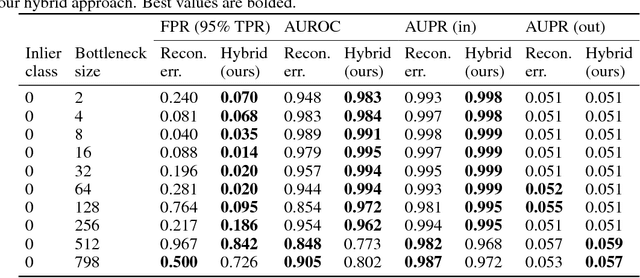
There is an increasingly apparent need for validating the classifications made by deep learning systems in safety-critical applications like autonomous vehicle systems. A number of recent papers have proposed methods for detecting anomalous image data that appear different from known inlier data samples, including reconstruction-based autoencoders. Autoencoders optimize the compression of input data to a latent space of a dimensionality smaller than the original input and attempt to accurately reconstruct the input using that compressed representation. Since the latent vector is optimized to capture the salient features from the inlier class only, it is commonly assumed that images of objects from outside of the training class cannot effectively be compressed and reconstructed. Some thus consider reconstruction error as a kind of novelty measure. Here we suggest that reconstruction-based approaches fail to capture particular anomalies that lie far from known inlier samples in latent space but near the latent dimension manifold defined by the parameters of the model. We propose incorporating the Mahalanobis distance in latent space to better capture these out-of-distribution samples and our results show that this method often improves performance over the baseline approach.
Calibrating Uncertainties in Object Localization Task
Nov 27, 2018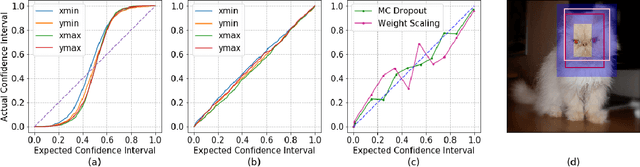
In many safety-critical applications such as autonomous driving and surgical robots, it is desirable to obtain prediction uncertainties from object detection modules to help support safe decision-making. Specifically, such modules need to estimate the probability of each predicted object in a given region and the confidence interval for its bounding box. While recent Bayesian deep learning methods provide a principled way to estimate this uncertainty, the estimates for the bounding boxes obtained using these methods are uncalibrated. In this paper, we address this problem for the single-object localization task by adapting an existing technique for calibrating regression models. We show, experimentally, that the resulting calibrated model obtains more reliable uncertainty estimates.