 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Inverse Constrained Reinforcement Learning: Definitions, Progress and Challenges
Sep 11, 2024



Inverse Constrained Reinforcement Learning (ICRL) is the task of inferring the implicit constraints followed by expert agents from their demonstration data. As an emerging research topic, ICRL has received considerable attention in recent years. This article presents a categorical survey of the latest advances in ICRL. It serves as a comprehensive reference for machine learning researchers and practitioners, as well as starters seeking to comprehend the definitions, advancements, and important challenges in ICRL. We begin by formally defining the problem and outlining the algorithmic framework that facilitates constraint inference across various scenarios. These include deterministic or stochastic environments, environments with limited demonstrations, and multiple agents. For each context, we illustrate the critical challenges and introduce a series of fundamental methods to tackle these issues. This survey encompasses discrete, virtual, and realistic environments for evaluating ICRL agents. We also delve into the most pertinent applications of ICRL, such as autonomous driving, robot control, and sports analytics. To stimulate continuing research, we conclude the survey with a discussion of key unresolved questions in ICRL that can effectively foster a bridge between theoretical understanding and practical industrial applications.
Benchmarking Constraint Inference in Inverse Reinforcement Learning
Jun 20, 2022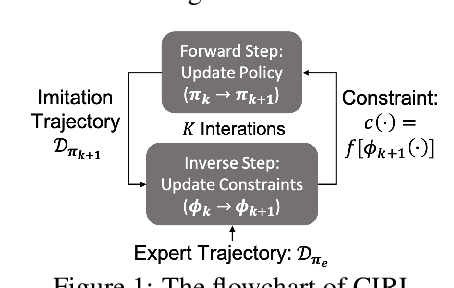
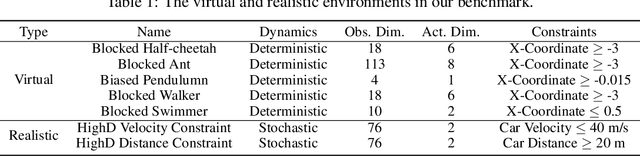
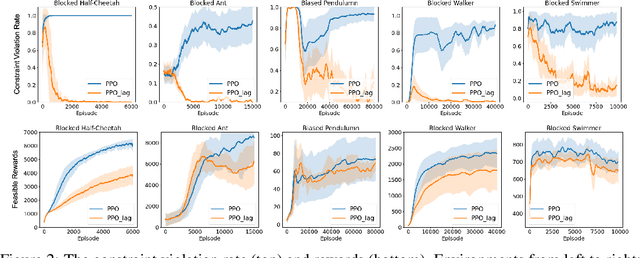

When deploying Reinforcement Learning (RL) agents into a physical system, we must ensure that these agents are well aware of the underlying constraints. In many real-world problems, however, the constraints followed by expert agents (e.g., humans) are often hard to specify mathematically and unknown to the RL agents. To tackle these issues, Constraint Inverse Reinforcement Learning (CIRL) considers the formalism of Constrained Markov Decision Processes (CMDPs) and estimates constraints from expert demonstrations by learning a constraint function. As an emerging research topic, CIRL does not have common benchmarks, and previous works tested their algorithms with hand-crafted environments (e.g., grid worlds). In this paper, we construct a CIRL benchmark in the context of two major application domains: robot control and autonomous driving. We design relevant constraints for each environment and empirically study the ability of different algorithms to recover those constraints based on expert trajectories that respect those constraints. To handle stochastic dynamics, we propose a variational approach that infers constraint distributions, and we demonstrate its performance by comparing it with other CIRL baselines on our benchmark. The benchmark, including the information for reproducing the performance of CIRL algorithms, is publicly available at https://github.com/Guiliang/CIRL-benchmarks-public
Learning Soft Constraints From Constrained Expert Demonstrations
Jun 02, 2022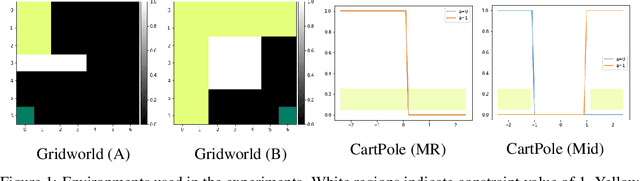
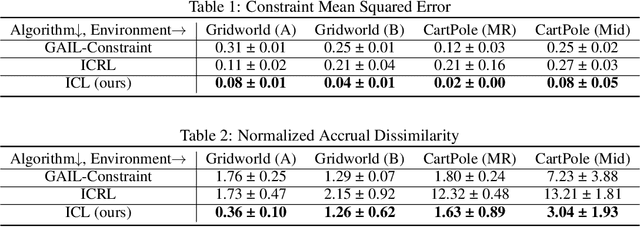

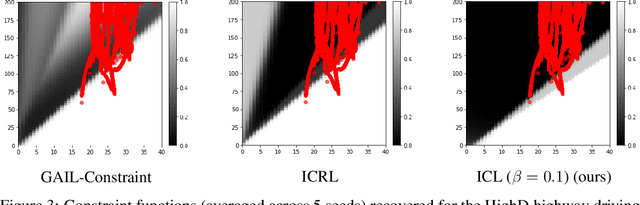
Inverse reinforcement learning (IRL) methods assume that the expert data is generated by an agent optimizing some reward function. However, in many settings, the agent may optimize a reward function subject to some constraints, where the constraints induce behaviors that may be otherwise difficult to express with just a reward function. We consider the setting where the reward function is given, and the constraints are unknown, and propose a method that is able to recover these constraints satisfactorily from the expert data. While previous work has focused on recovering hard constraints, our method can recover cumulative soft constraints that the agent satisfies on average per episode. In IRL fashion, our method solves this problem by adjusting the constraint function iteratively through a constrained optimization procedure, until the agent behavior matches the expert behavior. Despite the simplicity of the formulation, our method is able to obtain good results. We demonstrate our approach on synthetic environments and real world highway driving data.
Out-of-distribution Detection in Classifiers via Generation
Oct 09, 2019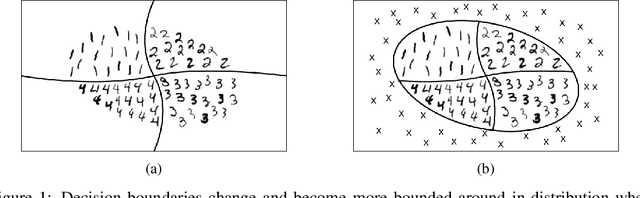
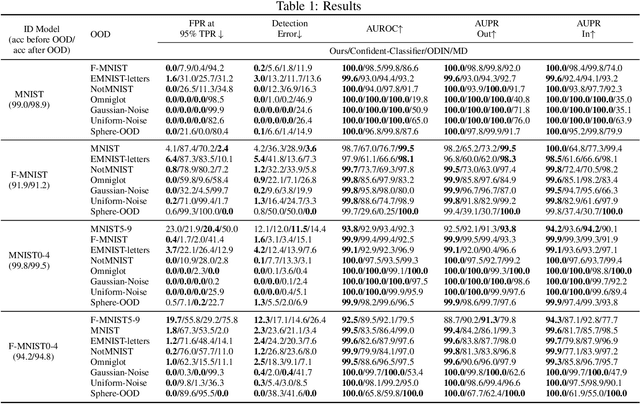
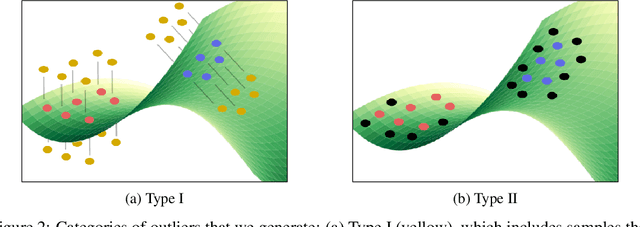
By design, discriminatively trained neural network classifiers produce reliable predictions only for in-distribution samples. For their real-world deployments, detecting out-of-distribution (OOD) samples is essential. Assuming OOD to be outside the closed boundary of in-distribution, typical neural classifiers do not contain the knowledge of this boundary for OOD detection during inference. There have been recent approaches to instill this knowledge in classifiers by explicitly training the classifier with OOD samples close to the in-distribution boundary. However, these generated samples fail to cover the entire in-distribution boundary effectively, thereby resulting in a sub-optimal OOD detector. In this paper, we analyze the feasibility of such approaches by investigating the complexity of producing such "effective" OOD samples. We also propose a novel algorithm to generate such samples using a manifold learning network (e.g., variational autoencoder) and then train an n+1 classifier for OOD detection, where the $n+1^{th}$ class represents the OOD samples. We compare our approach against several recent classifier-based OOD detectors on MNIST and Fashion-MNIST datasets. Overall the proposed approach consistently performs better than the others.
Design Space of Behaviour Planning for Autonomous Driving
Aug 21, 2019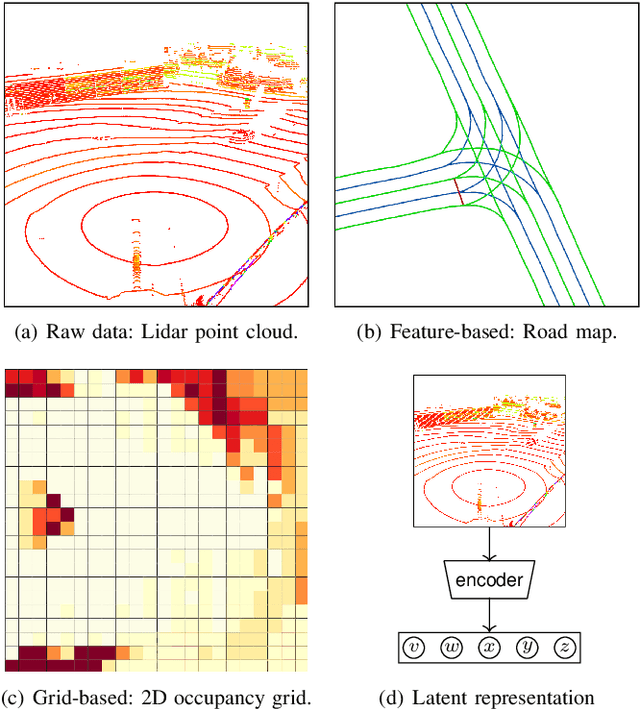
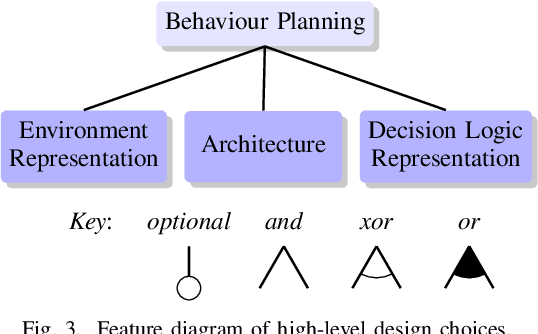
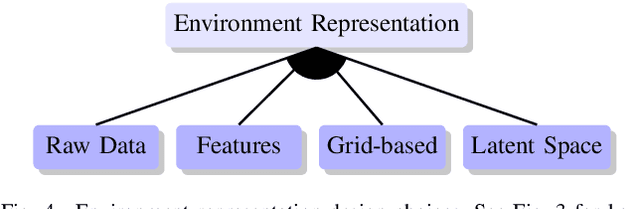
We explore the complex design space of behaviour planning for autonomous driving. Design choices that successfully address one aspect of behaviour planning can critically constrain others. To aid the design process, in this work we decompose the design space with respect to important choices arising from the current state of the art approaches, and describe the resulting trade-offs. In doing this, we also identify interesting directions of future work.
Analysis of Confident-Classifiers for Out-of-distribution Detection
Apr 27, 2019
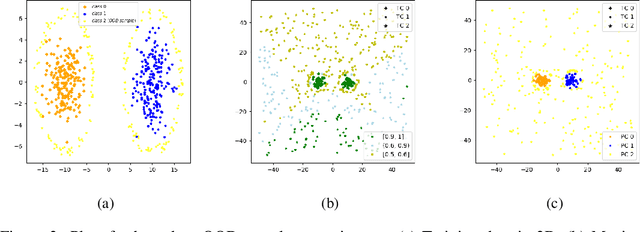
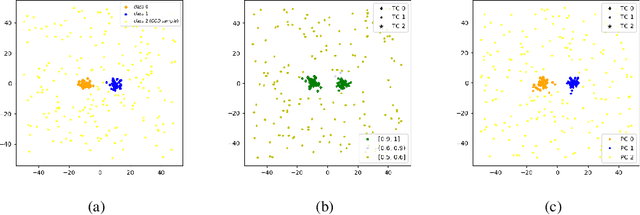
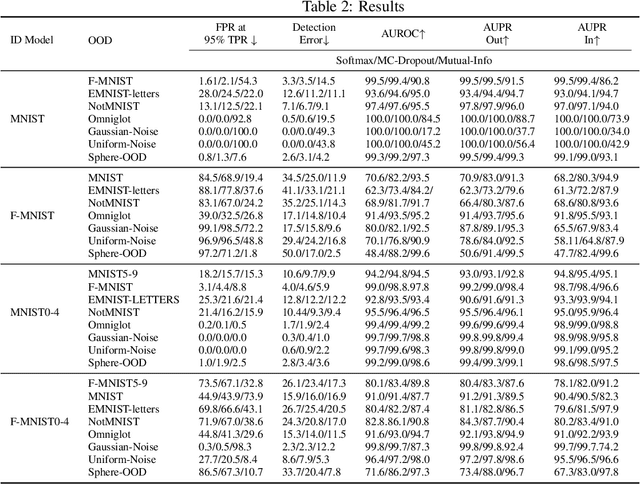
Discriminatively trained neural classifiers can be trusted, only when the input data comes from the training distribution (in-distribution). Therefore, detecting out-of-distribution (OOD) samples is very important to avoid classification errors. In the context of OOD detection for image classification, one of the recent approaches proposes training a classifier called "confident-classifier" by minimizing the standard cross-entropy loss on in-distribution samples and minimizing the KL divergence between the predictive distribution of OOD samples in the low-density regions of in-distribution and the uniform distribution (maximizing the entropy of the outputs). Thus, the samples could be detected as OOD if they have low confidence or high entropy. In this paper, we analyze this setting both theoretically and experimentally. We conclude that the resulting confident-classifier still yields arbitrarily high confidence for OOD samples far away from the in-distribution. We instead suggest training a classifier by adding an explicit "reject" class for OOD samples.
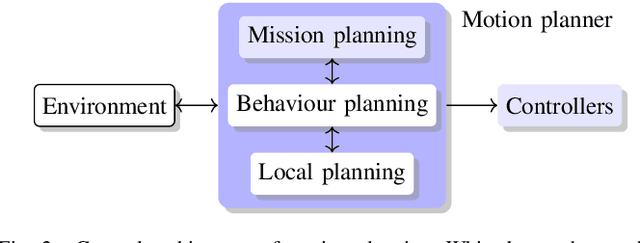
WiseMove: A Framework for Safe Deep Reinforcement Learning for Autonomous Driving
Feb 11, 2019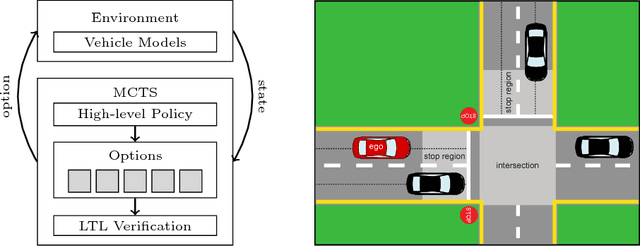
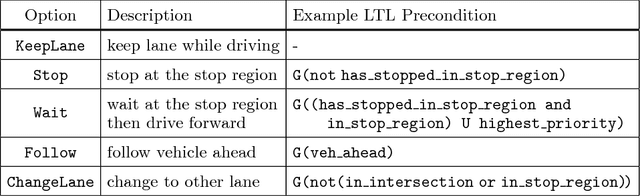


Machine learning can provide efficient solutions to the complex problems encountered in autonomous driving, but ensuring their safety remains a challenge. A number of authors have attempted to address this issue, but there are few publicly-available tools to adequately explore the trade-offs between functionality, scalability, and safety. We thus present WiseMove, a software framework to investigate safe deep reinforcement learning in the context of motion planning for autonomous driving. WiseMove adopts a modular learning architecture that suits our current research questions and can be adapted to new technologies and new questions. We present the details of WiseMove, demonstrate its use on a common traffic scenario, and describe how we use it in our ongoing safe learning research.