 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Structured Chain-of-Thought in Autonomous Vehicles
Feb 02, 2026Chain-of-Thought (CoT) reasoning enhances the decision-making capabilities of vision-language-action models in autonomous driving, but its autoregressive nature introduces significant inference latency, making it impractical for real-time applications. To address this, we introduce FastDriveCoT, a novel parallel decoding method that accelerates template-structured CoT. Our approach decomposes the reasoning process into a dependency graph of distinct sub-tasks, such as identifying critical objects and summarizing traffic rules, some of which can be generated in parallel. By generating multiple independent reasoning steps concurrently within a single forward pass, we significantly reduce the number of sequential computations. Experiments demonstrate a 3-4$\times$ speedup in CoT generation and a substantial reduction in end-to-end latency across various model architectures, all while preserving the original downstream task improvements brought by incorporating CoT reasoning.
Real-Time Pulsatile Flow Prediction for Realistic, Diverse Intracranial Aneurysm Morphologies using a Graph Transformer and Steady-Flow Data Augmentation
Jan 29, 2026Extensive studies suggested that fluid mechanical markers of intracranial aneurysms (IAs) derived from Computational Fluid Dynamics (CFD) can indicate disease progression risks, but to date this has not been translated clinically. This is because CFD requires specialized expertise and is time-consuming and low throughput, making it difficult to support clinical trials. A deep learning model that maps IA morphology to biomechanical markers can address this, enabling physicians to obtain these markers in real time without performing CFD. Here, we show that a Graph Transformer model that incorporates temporal information, which is supervised by large CFD data, can accurately predict Wall Shear Stress (WSS) across the cardiac cycle from IA surface meshes. The model effectively captures the temporal variations of the WSS pattern, achieving a Structural Similarity Index (SSIM) of up to 0.981 and a maximum-based relative L2 error of 2.8%. Ablation studies and SOTA comparison confirmed its optimality. Further, as pulsatile CFD data is computationally expensive to generate and sample sizes are limited, we engaged a strategy of injecting a large amount of steady-state CFD data, which are extremely low-cost to generate, as augmentation. This approach enhances network performance substantially when pulsatile CFD data sample size is small. Our study provides a proof of concept that temporal sequences cardiovascular fluid mechanical parameters can be computed in real time using a deep learning model from the geometric mesh, and this is achievable even with small pulsatile CFD sample size. Our approach is likely applicable to other cardiovascular scenarios.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Safety Evaluation of Motion Plans Using Trajectory Predictors as Forward Reachable Set Estimators
Jul 30, 2025

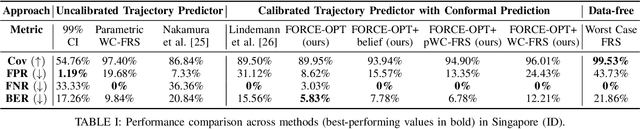

The advent of end-to-end autonomy stacks - often lacking interpretable intermediate modules - has placed an increased burden on ensuring that the final output, i.e., the motion plan, is safe in order to validate the safety of the entire stack. This requires a safety monitor that is both complete (able to detect all unsafe plans) and sound (does not flag safe plans). In this work, we propose a principled safety monitor that leverages modern multi-modal trajectory predictors to approximate forward reachable sets (FRS) of surrounding agents. By formulating a convex program, we efficiently extract these data-driven FRSs directly from the predicted state distributions, conditioned on scene context such as lane topology and agent history. To ensure completeness, we leverage conformal prediction to calibrate the FRS and guarantee coverage of ground-truth trajectories with high probability. To preserve soundness in out-of-distribution (OOD) scenarios or under predictor failure, we introduce a Bayesian filter that dynamically adjusts the FRS conservativeness based on the predictor's observed performance. We then assess the safety of the ego vehicle's motion plan by checking for intersections with these calibrated FRSs, ensuring the plan remains collision-free under plausible future behaviors of others. Extensive experiments on the nuScenes dataset show our approach significantly improves soundness while maintaining completeness, offering a practical and reliable safety monitor for learned autonomy stacks.
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
May 30, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model's accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
RealDrive: Retrieval-Augmented Driving with Diffusion Models
May 30, 2025



Learning-based planners generate natural human-like driving behaviors by learning to reason about nuanced interactions from data, overcoming the rigid behaviors that arise from rule-based planners. Nonetheless, data-driven approaches often struggle with rare, safety-critical scenarios and offer limited controllability over the generated trajectories. To address these challenges, we propose RealDrive, a Retrieval-Augmented Generation (RAG) framework that initializes a diffusion-based planning policy by retrieving the most relevant expert demonstrations from the training dataset. By interpolating between current observations and retrieved examples through a denoising process, our approach enables fine-grained control and safe behavior across diverse scenarios, leveraging the strong prior provided by the retrieved scenario. Another key insight we produce is that a task-relevant retrieval model trained with planning-based objectives results in superior planning performance in our framework compared to a task-agnostic retriever. Experimental results demonstrate improved generalization to long-tail events and enhanced trajectory diversity compared to standard learning-based planners -- we observe a 40% reduction in collision rate on the Waymo Open Motion dataset with RAG.
CrashAgent: Crash Scenario Generation via Multi-modal Reasoning
May 23, 2025



Training and evaluating autonomous driving algorithms requires a diverse range of scenarios. However, most available datasets predominantly consist of normal driving behaviors demonstrated by human drivers, resulting in a limited number of safety-critical cases. This imbalance, often referred to as a long-tail distribution, restricts the ability of driving algorithms to learn from crucial scenarios involving risk or failure, scenarios that are essential for humans to develop driving skills efficiently. To generate such scenarios, we utilize Multi-modal Large Language Models to convert crash reports of accidents into a structured scenario format, which can be directly executed within simulations. Specifically, we introduce CrashAgent, a multi-agent framework designed to interpret multi-modal real-world traffic crash reports for the generation of both road layouts and the behaviors of the ego vehicle and surrounding traffic participants. We comprehensively evaluate the generated crash scenarios from multiple perspectives, including the accuracy of layout reconstruction, collision rate, and diversity. The resulting high-quality and large-scale crash dataset will be publicly available to support the development of safe driving algorithms in handling safety-critical situations.
Two-Stage Generative Model for Intracranial Aneurysm Meshes with Morphological Marker Conditioning
May 15, 2025



A generative model for the mesh geometry of intracranial aneurysms (IA) is crucial for training networks to predict blood flow forces in real time, which is a key factor affecting disease progression. This need is necessitated by the absence of a large IA image datasets. Existing shape generation methods struggle to capture realistic IA features and ignore the relationship between IA pouches and parent vessels, limiting physiological realism and their generation cannot be controlled to have specific morphological measurements. We propose AneuG, a two-stage Variational Autoencoder (VAE)-based IA mesh generator. In the first stage, AneuG generates low-dimensional Graph Harmonic Deformation (GHD) tokens to encode and reconstruct aneurysm pouch shapes, constrained to morphing energy statistics truths. GHD enables more accurate shape encoding than alternatives. In the second stage, AneuG generates parent vessels conditioned on GHD tokens, by generating vascular centreline and propagating the cross-section. AneuG's IA shape generation can further be conditioned to have specific clinically relevant morphological measurements. This is useful for studies to understand shape variations represented by clinical measurements, and for flow simulation studies to understand effects of specific clinical shape parameters on fluid dynamics. Source code and implementation details are available at https://github.com/anonymousaneug/AneuG.
Deployable and Generalizable Motion Prediction: Taxonomy, Open Challenges and Future Directions
May 14, 2025



Motion prediction, the anticipation of future agent states or scene evolution, is rooted in human cognition, bridging perception and decision-making. It enables intelligent systems, such as robots and self-driving cars, to act safely in dynamic, human-involved environments, and informs broader time-series reasoning challenges. With advances in methods, representations, and datasets, the field has seen rapid progress, reflected in quickly evolving benchmark results. Yet, when state-of-the-art methods are deployed in the real world, they often struggle to generalize to open-world conditions and fall short of deployment standards. This reveals a gap between research benchmarks, which are often idealized or ill-posed, and real-world complexity. To address this gap, this survey revisits the generalization and deployability of motion prediction models, with an emphasis on the applications of robotics, autonomous driving, and human motion. We first offer a comprehensive taxonomy of motion prediction methods, covering representations, modeling strategies, application domains, and evaluation protocols. We then study two key challenges: (1) how to push motion prediction models to be deployable to realistic deployment standards, where motion prediction does not act in a vacuum, but functions as one module of closed-loop autonomy stacks - it takes input from the localization and perception, and informs downstream planning and control. 2) how to generalize motion prediction models from limited seen scenarios/datasets to the open-world settings. Throughout the paper, we highlight critical open challenges to guide future work, aiming to recalibrate the community's efforts, fostering progress that is not only measurable but also meaningful for real-world applications.