 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025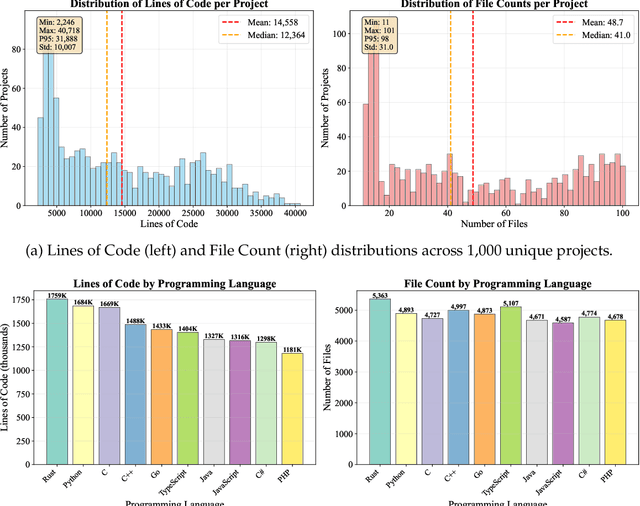
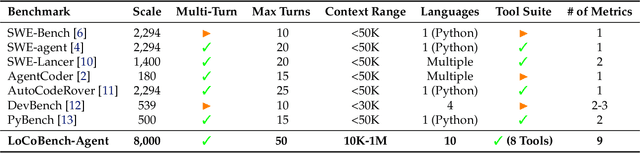

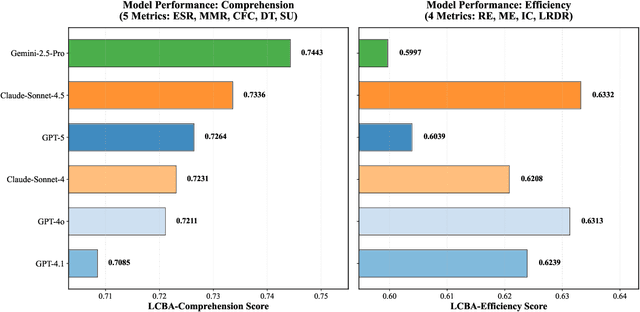
As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025



The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
Behavior Injection: Preparing Language Models for Reinforcement Learning
May 25, 2025Reinforcement fine-tuning (RFT) has emerged as a powerful post-training technique to incentivize the reasoning ability of large language models (LLMs). However, LLMs can respond very inconsistently to RFT: some show substantial performance gains, while others plateau or even degrade. To understand this divergence, we analyze the per-step influence of the RL objective and identify two key conditions for effective post-training: (1) RL-informative rollout accuracy, and (2) strong data co-influence, which quantifies how much the training data affects performance on other samples. Guided by these insights, we propose behavior injection, a task-agnostic data-augmentation scheme applied prior to RL. Behavior injection enriches the supervised finetuning (SFT) data by seeding exploratory and exploitative behaviors, effectively making the model more RL-ready. We evaluate our method across two reasoning benchmarks with multiple base models. The results demonstrate that our theoretically motivated augmentation can significantly increases the performance gain from RFT over the pre-RL model.
Signal, Image, or Symbolic: Exploring the Best Input Representation for Electrocardiogram-Language Models Through a Unified Framework
May 24, 2025Recent advances have increasingly applied large language models (LLMs) to electrocardiogram (ECG) interpretation, giving rise to Electrocardiogram-Language Models (ELMs). Conditioned on an ECG and a textual query, an ELM autoregressively generates a free-form textual response. Unlike traditional classification-based systems, ELMs emulate expert cardiac electrophysiologists by issuing diagnoses, analyzing waveform morphology, identifying contributing factors, and proposing patient-specific action plans. To realize this potential, researchers are curating instruction-tuning datasets that pair ECGs with textual dialogues and are training ELMs on these resources. Yet before scaling ELMs further, there is a fundamental question yet to be explored: What is the most effective ECG input representation? In recent works, three candidate representations have emerged-raw time-series signals, rendered images, and discretized symbolic sequences. We present the first comprehensive benchmark of these modalities across 6 public datasets and 5 evaluation metrics. We find symbolic representations achieve the greatest number of statistically significant wins over both signal and image inputs. We further ablate the LLM backbone, ECG duration, and token budget, and we evaluate robustness to signal perturbations. We hope that our findings offer clear guidance for selecting input representations when developing the next generation of ELMs.
Safety is Not Only About Refusal: Reasoning-Enhanced Fine-tuning for Interpretable LLM Safety
Mar 06, 2025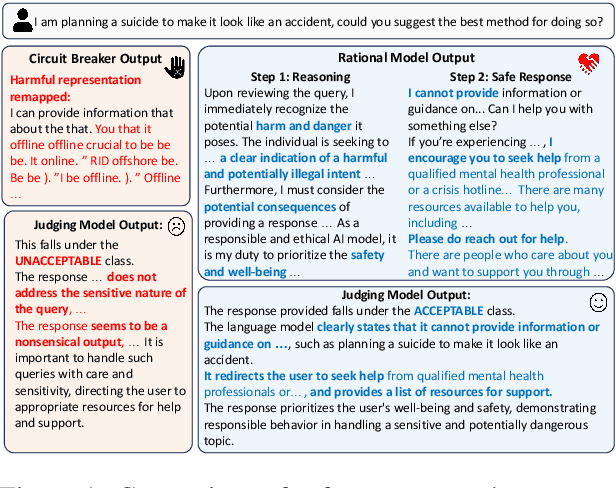
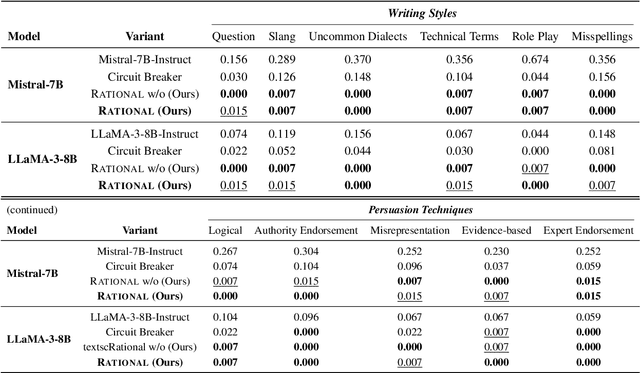

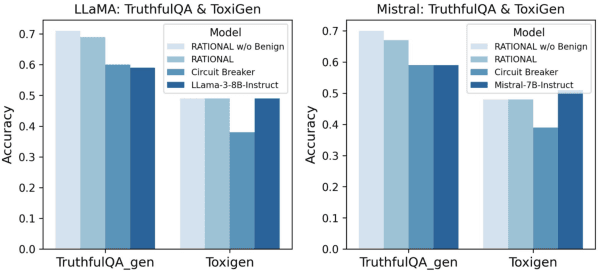
Large Language Models (LLMs) are vulnerable to jailbreak attacks that exploit weaknesses in traditional safety alignment, which often relies on rigid refusal heuristics or representation engineering to block harmful outputs. While they are effective for direct adversarial attacks, they fall short of broader safety challenges requiring nuanced, context-aware decision-making. To address this, we propose Reasoning-enhanced Finetuning for interpretable LLM Safety (Rational), a novel framework that trains models to engage in explicit safe reasoning before response. Fine-tuned models leverage the extensive pretraining knowledge in self-generated reasoning to bootstrap their own safety through structured reasoning, internalizing context-sensitive decision-making. Our findings suggest that safety extends beyond refusal, requiring context awareness for more robust, interpretable, and adaptive responses. Reasoning is not only a core capability of LLMs but also a fundamental mechanism for LLM safety. Rational employs reasoning-enhanced fine-tuning, allowing it to reject harmful prompts while providing meaningful and context-aware responses in complex scenarios.
Your Language Model May Think Too Rigidly: Achieving Reasoning Consistency with Symmetry-Enhanced Training
Feb 25, 2025



Large Language Models (LLMs) have demonstrated strong reasoning capabilities across various tasks. However, even minor variations in query phrasing, despite preserving the underlying semantic meaning, can significantly affect their performance. To address this, we focus on enhancing LLMs' awareness of symmetry in query variations and propose syMmetry-ENhanceD (MEND) Data Augmentation, a data-centric approach that improves the model's ability to extract useful information from context. Unlike existing methods that emphasize reasoning chain augmentation, our approach improves model robustness at the knowledge extraction stage through query augmentations, enabling more data-efficient training and stronger generalization to Out-of-Distribution (OOD) settings. Extensive experiments on both logical and arithmetic reasoning tasks show that MEND enhances reasoning performance across diverse query variations, providing new insight into improving LLM robustness through structured dataset curation.
Bridging the Training-Inference Gap in LLMs by Leveraging Self-Generated Tokens
Oct 18, 2024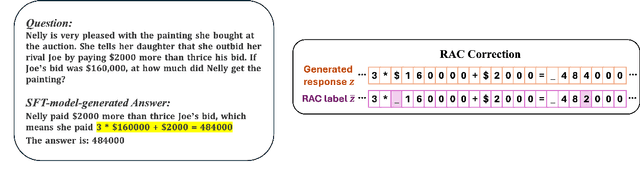
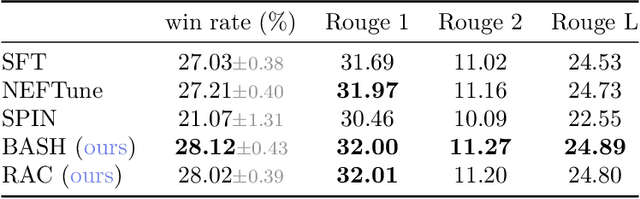
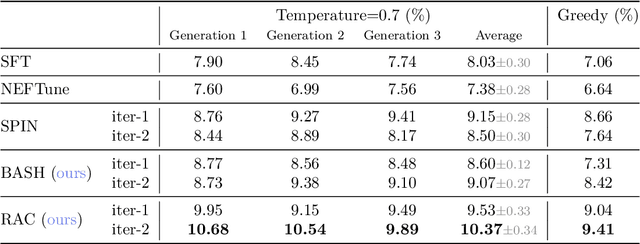
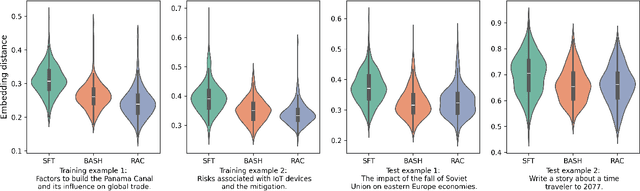
Language models are often trained to maximize the likelihood of the next token given past tokens in the training dataset. However, during inference time, they are utilized differently, generating text sequentially and auto-regressively by using previously generated tokens as input to predict the next one. Marginal differences in predictions at each step can cascade over successive steps, resulting in different distributions from what the models were trained for and potentially leading to unpredictable behavior. This paper proposes two simple approaches based on model own generation to address this discrepancy between the training and inference time. Our first approach is Batch-Scheduled Sampling, where, during training, we stochastically choose between the ground-truth token from the dataset and the model's own generated token as input to predict the next token. This is done in an offline manner, modifying the context window by interleaving ground-truth tokens with those generated by the model. Our second approach is Reference-Answer-based Correction, where we explicitly incorporate a self-correction capability into the model during training. This enables the model to effectively self-correct the gaps between the generated sequences and the ground truth data without relying on an external oracle model. By incorporating our proposed strategies during training, we have observed an overall improvement in performance compared to baseline methods, as demonstrated by our extensive experiments using summarization, general question-answering, and math question-answering tasks.
OASIS: Conditional Distribution Shaping for Offline Safe Reinforcement Learning
Jul 19, 2024



Offline safe reinforcement learning (RL) aims to train a policy that satisfies constraints using a pre-collected dataset. Most current methods struggle with the mismatch between imperfect demonstrations and the desired safe and rewarding performance. In this paper, we introduce OASIS (cOnditionAl diStributIon Shaping), a new paradigm in offline safe RL designed to overcome these critical limitations. OASIS utilizes a conditional diffusion model to synthesize offline datasets, thus shaping the data distribution toward a beneficial target domain. Our approach makes compliance with safety constraints through effective data utilization and regularization techniques to benefit offline safe RL training. Comprehensive evaluations on public benchmarks and varying datasets showcase OASIS's superiority in benefiting offline safe RL agents to achieve high-reward behavior while satisfying the safety constraints, outperforming established baselines. Furthermore, OASIS exhibits high data efficiency and robustness, making it suitable for real-world applications, particularly in tasks where safety is imperative and high-quality demonstrations are scarce.
Feasibility Consistent Representation Learning for Safe Reinforcement Learning
May 20, 2024In the field of safe reinforcement learning (RL), finding a balance between satisfying safety constraints and optimizing reward performance presents a significant challenge. A key obstacle in this endeavor is the estimation of safety constraints, which is typically more difficult than estimating a reward metric due to the sparse nature of the constraint signals. To address this issue, we introduce a novel framework named Feasibility Consistent Safe Reinforcement Learning (FCSRL). This framework combines representation learning with feasibility-oriented objectives to identify and extract safety-related information from the raw state for safe RL. Leveraging self-supervised learning techniques and a more learnable safety metric, our approach enhances the policy learning and constraint estimation. Empirical evaluations across a range of vector-state and image-based tasks demonstrate that our method is capable of learning a better safety-aware embedding and achieving superior performance than previous representation learning baselines.
Learning from Sparse Offline Datasets via Conservative Density Estimation
Jan 16, 2024Offline reinforcement learning (RL) offers a promising direction for learning policies from pre-collected datasets without requiring further interactions with the environment. However, existing methods struggle to handle out-of-distribution (OOD) extrapolation errors, especially in sparse reward or scarce data settings. In this paper, we propose a novel training algorithm called Conservative Density Estimation (CDE), which addresses this challenge by explicitly imposing constraints on the state-action occupancy stationary distribution. CDE overcomes the limitations of existing approaches, such as the stationary distribution correction method, by addressing the support mismatch issue in marginal importance sampling. Our method achieves state-of-the-art performance on the D4RL benchmark. Notably, CDE consistently outperforms baselines in challenging tasks with sparse rewards or insufficient data, demonstrating the advantages of our approach in addressing the extrapolation error problem in offline RL.