 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWestWorld: A Knowledge-Encoded Scalable Trajectory World Model for Diverse Robotic Systems
Mar 15, 2026Trajectory world models play a crucial role in robotic dynamics learning, planning, and control. While recent works have explored trajectory world models for diverse robotic systems, they struggle to scale to a large number of distinct system dynamics and overlook domain knowledge of physical structures. To address these limitations, we introduce WestWorld, a knoWledge-Encoded Scalable Trajectory World model for diverse robotic systems. To tackle the scalability challenge, we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding. To further enhance zero-shot generalization, we incorporate domain knowledge of robot physical structures by introducing a structural embedding that aligns trajectory representations with morphological information. After pretraining on 89 complex environments spanning diverse morphologies across both simulation and real-world settings, WestWorld achieves significant improvements over competitive baselines in zero- and few-shot trajectory prediction. Additionally, it shows strong scalability across a wide range of robotic environments and significantly improves performance on downstream model-based control for different robots. Finally, we deploy our model on a real-world Unitree Go1, where it demonstrates stable locomotion performance (see our demo on the website: https://westworldrobot.github.io/). The code will be available upon publication.
A Generalizable Physics-guided Causal Model for Trajectory Prediction in Autonomous Driving
Feb 15, 2026Trajectory prediction for traffic agents is critical for safe autonomous driving. However, achieving effective zero-shot generalization in previously unseen domains remains a significant challenge. Motivated by the consistent nature of kinematics across diverse domains, we aim to incorporate domain-invariant knowledge to enhance zero-shot trajectory prediction capabilities. The key challenges include: 1) effectively extracting domain-invariant scene representations, and 2) integrating invariant features with kinematic models to enable generalized predictions. To address these challenges, we propose a novel generalizable Physics-guided Causal Model (PCM), which comprises two core components: a Disentangled Scene Encoder, which adopts intervention-based disentanglement to extract domain-invariant features from scenes, and a CausalODE Decoder, which employs a causal attention mechanism to effectively integrate kinematic models with meaningful contextual information. Extensive experiments on real-world autonomous driving datasets demonstrate our method's superior zero-shot generalization performance in unseen cities, significantly outperforming competitive baselines. The source code is released at https://github.com/ZY-Zong/Physics-guided-Causal-Model.
Pushing Forward Pareto Frontiers of Proactive Agents with Behavioral Agentic Optimization
Feb 11, 2026Proactive large language model (LLM) agents aim to actively plan, query, and interact over multiple turns, enabling efficient task completion beyond passive instruction following and making them essential for real-world, user-centric applications. Agentic reinforcement learning (RL) has recently emerged as a promising solution for training such agents in multi-turn settings, allowing interaction strategies to be learned from feedback. However, existing pipelines face a critical challenge in balancing task performance with user engagement, as passive agents can not efficiently adapt to users' intentions while overuse of human feedback reduces their satisfaction. To address this trade-off, we propose BAO, an agentic RL framework that combines behavior enhancement to enrich proactive reasoning and information-gathering capabilities with behavior regularization to suppress inefficient or redundant interactions and align agent behavior with user expectations. We evaluate BAO on multiple tasks from the UserRL benchmark suite, and demonstrate that it substantially outperforms proactive agentic RL baselines while achieving comparable or even superior performance to commercial LLM agents, highlighting its effectiveness for training proactive, user-aligned LLM agents in complex multi-turn scenarios. Our website: https://proactive-agentic-rl.github.io/.
CrashAgent: Crash Scenario Generation via Multi-modal Reasoning
May 23, 2025



Training and evaluating autonomous driving algorithms requires a diverse range of scenarios. However, most available datasets predominantly consist of normal driving behaviors demonstrated by human drivers, resulting in a limited number of safety-critical cases. This imbalance, often referred to as a long-tail distribution, restricts the ability of driving algorithms to learn from crucial scenarios involving risk or failure, scenarios that are essential for humans to develop driving skills efficiently. To generate such scenarios, we utilize Multi-modal Large Language Models to convert crash reports of accidents into a structured scenario format, which can be directly executed within simulations. Specifically, we introduce CrashAgent, a multi-agent framework designed to interpret multi-modal real-world traffic crash reports for the generation of both road layouts and the behaviors of the ego vehicle and surrounding traffic participants. We comprehensively evaluate the generated crash scenarios from multiple perspectives, including the accuracy of layout reconstruction, collision rate, and diversity. The resulting high-quality and large-scale crash dataset will be publicly available to support the development of safe driving algorithms in handling safety-critical situations.
Causal Composition Diffusion Model for Closed-loop Traffic Generation
Dec 23, 2024Simulation is critical for safety evaluation in autonomous driving, particularly in capturing complex interactive behaviors. However, generating realistic and controllable traffic scenarios in long-tail situations remains a significant challenge. Existing generative models suffer from the conflicting objective between user-defined controllability and realism constraints, which is amplified in safety-critical contexts. In this work, we introduce the Causal Compositional Diffusion Model (CCDiff), a structure-guided diffusion framework to address these challenges. We first formulate the learning of controllable and realistic closed-loop simulation as a constrained optimization problem. Then, CCDiff maximizes controllability while adhering to realism by automatically identifying and injecting causal structures directly into the diffusion process, providing structured guidance to enhance both realism and controllability. Through rigorous evaluations on benchmark datasets and in a closed-loop simulator, CCDiff demonstrates substantial gains over state-of-the-art approaches in generating realistic and user-preferred trajectories. Our results show CCDiff's effectiveness in extracting and leveraging causal structures, showing improved closed-loop performance based on key metrics such as collision rate, off-road rate, FDE, and comfort.
OASIS: Conditional Distribution Shaping for Offline Safe Reinforcement Learning
Jul 19, 2024



Offline safe reinforcement learning (RL) aims to train a policy that satisfies constraints using a pre-collected dataset. Most current methods struggle with the mismatch between imperfect demonstrations and the desired safe and rewarding performance. In this paper, we introduce OASIS (cOnditionAl diStributIon Shaping), a new paradigm in offline safe RL designed to overcome these critical limitations. OASIS utilizes a conditional diffusion model to synthesize offline datasets, thus shaping the data distribution toward a beneficial target domain. Our approach makes compliance with safety constraints through effective data utilization and regularization techniques to benefit offline safe RL training. Comprehensive evaluations on public benchmarks and varying datasets showcase OASIS's superiority in benefiting offline safe RL agents to achieve high-reward behavior while satisfying the safety constraints, outperforming established baselines. Furthermore, OASIS exhibits high data efficiency and robustness, making it suitable for real-world applications, particularly in tasks where safety is imperative and high-quality demonstrations are scarce.
BECAUSE: Bilinear Causal Representation for Generalizable Offline Model-based Reinforcement Learning
Jul 15, 2024



Offline model-based reinforcement learning (MBRL) enhances data efficiency by utilizing pre-collected datasets to learn models and policies, especially in scenarios where exploration is costly or infeasible. Nevertheless, its performance often suffers from the objective mismatch between model and policy learning, resulting in inferior performance despite accurate model predictions. This paper first identifies the primary source of this mismatch comes from the underlying confounders present in offline data for MBRL. Subsequently, we introduce \textbf{B}ilin\textbf{E}ar \textbf{CAUS}al r\textbf{E}presentation~(BECAUSE), an algorithm to capture causal representation for both states and actions to reduce the influence of the distribution shift, thus mitigating the objective mismatch problem. Comprehensive evaluations on 18 tasks that vary in data quality and environment context demonstrate the superior performance of BECAUSE over existing offline RL algorithms. We show the generalizability and robustness of BECAUSE under fewer samples or larger numbers of confounders. Additionally, we offer theoretical analysis of BECAUSE to prove its error bound and sample efficiency when integrating causal representation into offline MBRL.
Generalize by Touching: Tactile Ensemble Skill Transfer for Robotic Furniture Assembly
Apr 26, 2024Furniture assembly remains an unsolved problem in robotic manipulation due to its long task horizon and nongeneralizable operations plan. This paper presents the Tactile Ensemble Skill Transfer (TEST) framework, a pioneering offline reinforcement learning (RL) approach that incorporates tactile feedback in the control loop. TEST's core design is to learn a skill transition model for high-level planning, along with a set of adaptive intra-skill goal-reaching policies. Such design aims to solve the robotic furniture assembly problem in a more generalizable way, facilitating seamless chaining of skills for this long-horizon task. We first sample demonstration from a set of heuristic policies and trajectories consisting of a set of randomized sub-skill segments, enabling the acquisition of rich robot trajectories that capture skill stages, robot states, visual indicators, and crucially, tactile signals. Leveraging these trajectories, our offline RL method discerns skill termination conditions and coordinates skill transitions. Our evaluations highlight the proficiency of TEST on the in-distribution furniture assemblies, its adaptability to unseen furniture configurations, and its robustness against visual disturbances. Ablation studies further accentuate the pivotal role of two algorithmic components: the skill transition model and tactile ensemble policies. Results indicate that TEST can achieve a success rate of 90\% and is over 4 times more efficient than the heuristic policy in both in-distribution and generalization settings, suggesting a scalable skill transfer approach for contact-rich manipulation.
Safety-aware Causal Representation for Trustworthy Reinforcement Learning in Autonomous Driving
Oct 31, 2023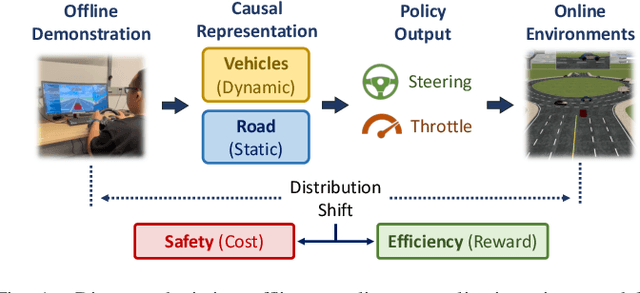
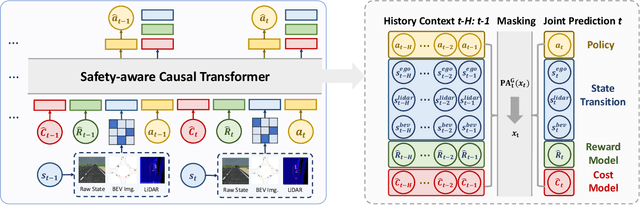
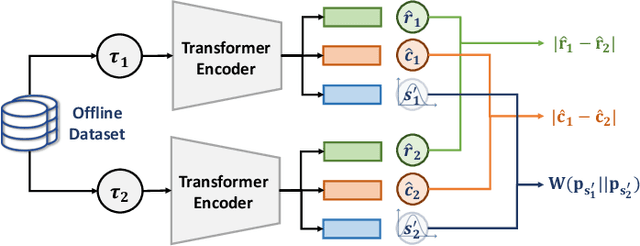

In the domain of autonomous driving, the Learning from Demonstration (LfD) paradigm has exhibited notable efficacy in addressing sequential decision-making problems. However, consistently achieving safety in varying traffic contexts, especially in safety-critical scenarios, poses a significant challenge due to the long-tailed and unforeseen scenarios absent from offline datasets. In this paper, we introduce the saFety-aware strUctured Scenario representatION (FUSION), a pioneering methodology conceived to facilitate the learning of an adaptive end-to-end driving policy by leveraging structured scenario information. FUSION capitalizes on the causal relationships between decomposed reward, cost, state, and action space, constructing a framework for structured sequential reasoning under dynamic traffic environments. We conduct rigorous evaluations in two typical real-world settings of distribution shift in autonomous vehicles, demonstrating the good balance between safety cost and utility reward of FUSION compared to contemporary state-of-the-art safety-aware LfD baselines. Empirical evidence under diverse driving scenarios attests that FUSION significantly enhances the safety and generalizability of autonomous driving agents, even in the face of challenging and unseen environments. Furthermore, our ablation studies reveal noticeable improvements in the integration of causal representation into the safe offline RL problem.
Datasets and Benchmarks for Offline Safe Reinforcement Learning
Jun 16, 2023



This paper presents a comprehensive benchmarking suite tailored to offline safe reinforcement learning (RL) challenges, aiming to foster progress in the development and evaluation of safe learning algorithms in both the training and deployment phases. Our benchmark suite contains three packages: 1) expertly crafted safe policies, 2) D4RL-styled datasets along with environment wrappers, and 3) high-quality offline safe RL baseline implementations. We feature a methodical data collection pipeline powered by advanced safe RL algorithms, which facilitates the generation of diverse datasets across 38 popular safe RL tasks, from robot control to autonomous driving. We further introduce an array of data post-processing filters, capable of modifying each dataset's diversity, thereby simulating various data collection conditions. Additionally, we provide elegant and extensible implementations of prevalent offline safe RL algorithms to accelerate research in this area. Through extensive experiments with over 50000 CPU and 800 GPU hours of computations, we evaluate and compare the performance of these baseline algorithms on the collected datasets, offering insights into their strengths, limitations, and potential areas of improvement. Our benchmarking framework serves as a valuable resource for researchers and practitioners, facilitating the development of more robust and reliable offline safe RL solutions in safety-critical applications. The benchmark website is available at \url{www.offline-saferl.org}.