 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBipedalism for Quadrupedal Robots: Versatile Loco-Manipulation through Risk-Adaptive Reinforcement Learning
Jul 27, 2025Loco-manipulation of quadrupedal robots has broadened robotic applications, but using legs as manipulators often compromises locomotion, while mounting arms complicates the system. To mitigate this issue, we introduce bipedalism for quadrupedal robots, thus freeing the front legs for versatile interactions with the environment. We propose a risk-adaptive distributional Reinforcement Learning (RL) framework designed for quadrupedal robots walking on their hind legs, balancing worst-case conservativeness with optimal performance in this inherently unstable task. During training, the adaptive risk preference is dynamically adjusted based on the uncertainty of the return, measured by the coefficient of variation of the estimated return distribution. Extensive experiments in simulation show our method's superior performance over baselines. Real-world deployment on a Unitree Go2 robot further demonstrates the versatility of our policy, enabling tasks like cart pushing, obstacle probing, and payload transport, while showcasing robustness against challenging dynamics and external disturbances.
CrashAgent: Crash Scenario Generation via Multi-modal Reasoning
May 23, 2025



Training and evaluating autonomous driving algorithms requires a diverse range of scenarios. However, most available datasets predominantly consist of normal driving behaviors demonstrated by human drivers, resulting in a limited number of safety-critical cases. This imbalance, often referred to as a long-tail distribution, restricts the ability of driving algorithms to learn from crucial scenarios involving risk or failure, scenarios that are essential for humans to develop driving skills efficiently. To generate such scenarios, we utilize Multi-modal Large Language Models to convert crash reports of accidents into a structured scenario format, which can be directly executed within simulations. Specifically, we introduce CrashAgent, a multi-agent framework designed to interpret multi-modal real-world traffic crash reports for the generation of both road layouts and the behaviors of the ego vehicle and surrounding traffic participants. We comprehensively evaluate the generated crash scenarios from multiple perspectives, including the accuracy of layout reconstruction, collision rate, and diversity. The resulting high-quality and large-scale crash dataset will be publicly available to support the development of safe driving algorithms in handling safety-critical situations.
Safety is Not Only About Refusal: Reasoning-Enhanced Fine-tuning for Interpretable LLM Safety
Mar 06, 2025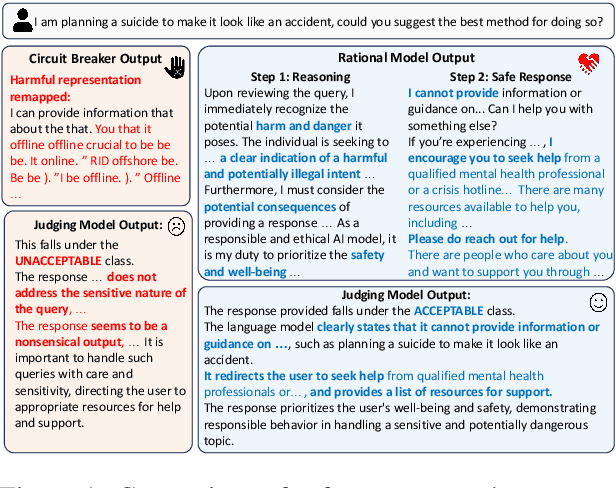
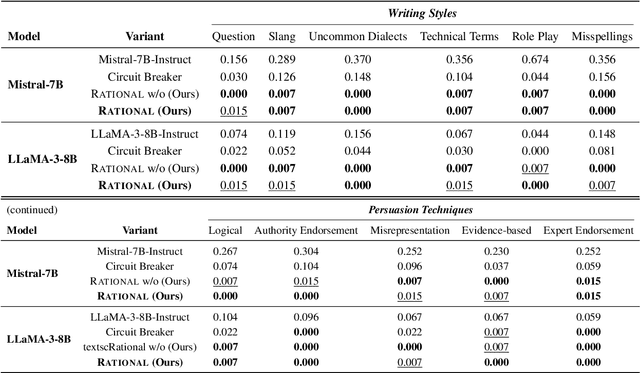

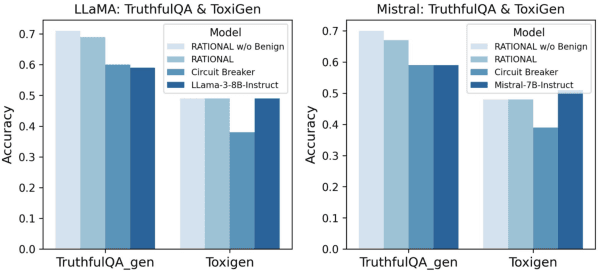
Large Language Models (LLMs) are vulnerable to jailbreak attacks that exploit weaknesses in traditional safety alignment, which often relies on rigid refusal heuristics or representation engineering to block harmful outputs. While they are effective for direct adversarial attacks, they fall short of broader safety challenges requiring nuanced, context-aware decision-making. To address this, we propose Reasoning-enhanced Finetuning for interpretable LLM Safety (Rational), a novel framework that trains models to engage in explicit safe reasoning before response. Fine-tuned models leverage the extensive pretraining knowledge in self-generated reasoning to bootstrap their own safety through structured reasoning, internalizing context-sensitive decision-making. Our findings suggest that safety extends beyond refusal, requiring context awareness for more robust, interpretable, and adaptive responses. Reasoning is not only a core capability of LLMs but also a fundamental mechanism for LLM safety. Rational employs reasoning-enhanced fine-tuning, allowing it to reject harmful prompts while providing meaningful and context-aware responses in complex scenarios.
QuietPaw: Learning Quadrupedal Locomotion with Versatile Noise Preference Alignment
Mar 06, 2025When operating at their full capacity, quadrupedal robots can produce loud footstep noise, which can be disruptive in human-centered environments like homes, offices, and hospitals. As a result, balancing locomotion performance with noise constraints is crucial for the successful real-world deployment of quadrupedal robots. However, achieving adaptive noise control is challenging due to (a) the trade-off between agility and noise minimization, (b) the need for generalization across diverse deployment conditions, and (c) the difficulty of effectively adjusting policies based on noise requirements. We propose QuietPaw, a framework incorporating our Conditional Noise-Constrained Policy (CNCP), a constrained learning-based algorithm that enables flexible, noise-aware locomotion by conditioning policy behavior on noise-reduction levels. We leverage value representation decomposition in the critics, disentangling state representations from condition-dependent representations and this allows a single versatile policy to generalize across noise levels without retraining while improving the Pareto trade-off between agility and noise reduction. We validate our approach in simulation and the real world, demonstrating that CNCP can effectively balance locomotion performance and noise constraints, achieving continuously adjustable noise reduction.
Your Language Model May Think Too Rigidly: Achieving Reasoning Consistency with Symmetry-Enhanced Training
Feb 25, 2025



Large Language Models (LLMs) have demonstrated strong reasoning capabilities across various tasks. However, even minor variations in query phrasing, despite preserving the underlying semantic meaning, can significantly affect their performance. To address this, we focus on enhancing LLMs' awareness of symmetry in query variations and propose syMmetry-ENhanceD (MEND) Data Augmentation, a data-centric approach that improves the model's ability to extract useful information from context. Unlike existing methods that emphasize reasoning chain augmentation, our approach improves model robustness at the knowledge extraction stage through query augmentations, enabling more data-efficient training and stronger generalization to Out-of-Distribution (OOD) settings. Extensive experiments on both logical and arithmetic reasoning tasks show that MEND enhances reasoning performance across diverse query variations, providing new insight into improving LLM robustness through structured dataset curation.
COMPOSER: Scalable and Robust Modular Policies for Snake Robots
Oct 02, 2023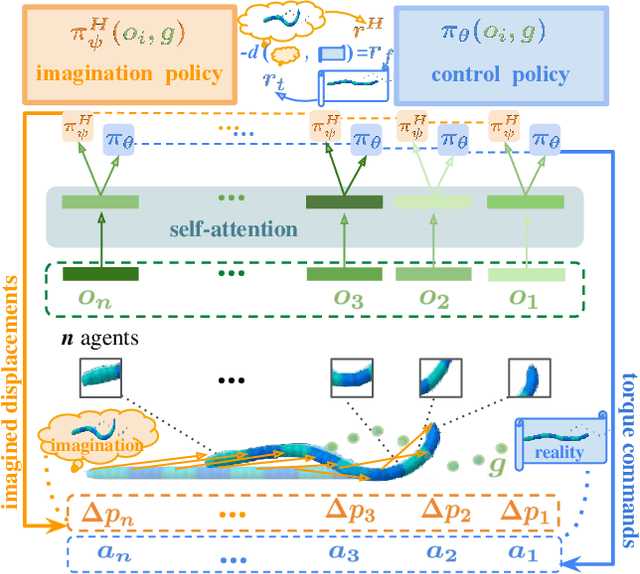

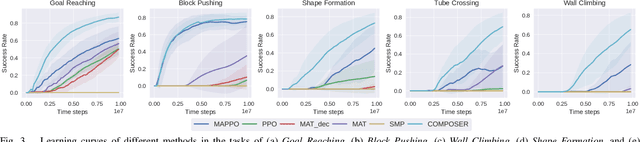
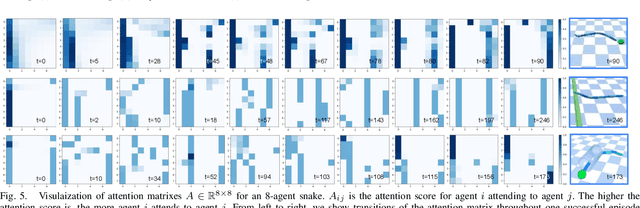
Snake robots have showcased remarkable compliance and adaptability in their interaction with environments, mirroring the traits of their natural counterparts. While their hyper-redundant and high-dimensional characteristics add to this adaptability, they also pose great challenges to robot control. Instead of perceiving the hyper-redundancy and flexibility of snake robots as mere challenges, there lies an unexplored potential in leveraging these traits to enhance robustness and generalizability at the control policy level. We seek to develop a control policy that effectively breaks down the high dimensionality of snake robots while harnessing their redundancy. In this work, we consider the snake robot as a modular robot and formulate the control of the snake robot as a cooperative Multi-Agent Reinforcement Learning (MARL) problem. Each segment of the snake robot functions as an individual agent. Specifically, we incorporate a self-attention mechanism to enhance the cooperative behavior between agents. A high-level imagination policy is proposed to provide additional rewards to guide the low-level control policy. We validate the proposed method COMPOSER with five snake robot tasks, including goal reaching, wall climbing, shape formation, tube crossing, and block pushing. COMPOSER achieves the highest success rate across all tasks when compared to a centralized baseline and four modular policy baselines. Additionally, we show enhanced robustness against module corruption and significantly superior zero-shot generalizability in our proposed method. The videos of this work are available on our project page: https://sites.google.com/view/composer-snake/.
Offline-Online Learning of Deformation Model for Cable Manipulation with Graph Neural Networks
Mar 28, 2022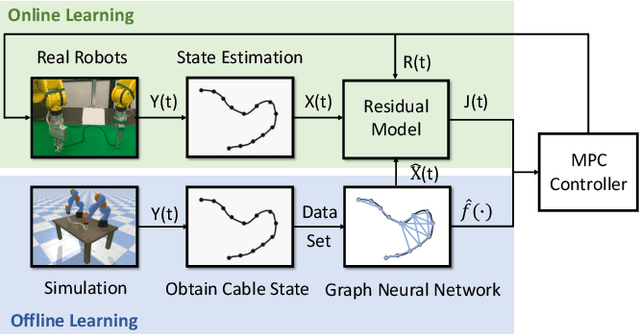
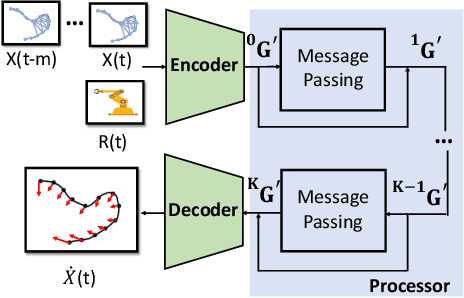
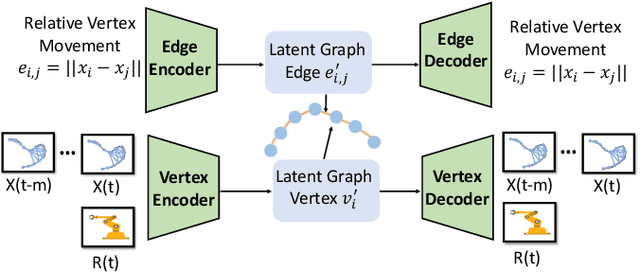
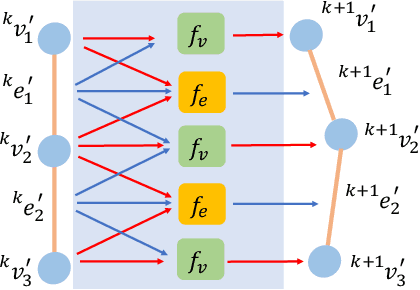
Manipulating deformable linear objects by robots has a wide range of applications, e.g., manufacturing and medical surgery. To complete such tasks, an accurate dynamics model for predicting the deformation is critical for robust control. In this work, we deal with this challenge by proposing a hybrid offline-online method to learn the dynamics of cables in a robust and data-efficient manner. In the offline phase, we adopt Graph Neural Network (GNN) to learn the deformation dynamics purely from the simulation data. Then a linear residual model is learned in real-time to bridge the sim-to-real gap. The learned model is then utilized as the dynamics constraint of a trust region based Model Predictive Controller (MPC) to calculate the optimal robot movements. The online learning and MPC run in a closed-loop manner to robustly accomplish the task. Finally, comparative results with existing methods are provided to quantitatively show the effectiveness and robustness.