 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGeM: Unifying Data Mixing and Selection via Geometric Exploration and Mining
Feb 03, 2026The scaling of Large Language Models (LLMs) is increasingly limited by data quality. Most methods handle data mixing and sample selection separately, which can break the structure in code corpora. We introduce \textbf{UniGeM}, a framework that unifies mixing and selection by treating data curation as a \textit{manifold approximation} problem without training proxy models or relying on external reference datasets. UniGeM operates hierarchically: \textbf{Macro-Exploration} learns mixing weights with stability-based clustering; \textbf{Micro-Mining} filters high-quality instances by their geometric distribution to ensure logical consistency. Validated by training 8B and 16B MoE models on 100B tokens, UniGeM achieves \textbf{2.0$\times$ data efficiency} over a random baseline and further improves overall performance compared to SOTA methods in reasoning-heavy evaluations and multilingual generalization.
OSMO: Open-Source Tactile Glove for Human-to-Robot Skill Transfer
Dec 09, 2025Human video demonstrations provide abundant training data for learning robot policies, but video alone cannot capture the rich contact signals critical for mastering manipulation. We introduce OSMO, an open-source wearable tactile glove designed for human-to-robot skill transfer. The glove features 12 three-axis tactile sensors across the fingertips and palm and is designed to be compatible with state-of-the-art hand-tracking methods for in-the-wild data collection. We demonstrate that a robot policy trained exclusively on human demonstrations collected with OSMO, without any real robot data, is capable of executing a challenging contact-rich manipulation task. By equipping both the human and the robot with the same glove, OSMO minimizes the visual and tactile embodiment gap, enabling the transfer of continuous shear and normal force feedback while avoiding the need for image inpainting or other vision-based force inference. On a real-world wiping task requiring sustained contact pressure, our tactile-aware policy achieves a 72% success rate, outperforming vision-only baselines by eliminating contact-related failure modes. We release complete hardware designs, firmware, and assembly instructions to support community adoption.
SPIDER: Scalable Physics-Informed Dexterous Retargeting
Nov 12, 2025Learning dexterous and agile policy for humanoid and dexterous hand control requires large-scale demonstrations, but collecting robot-specific data is prohibitively expensive. In contrast, abundant human motion data is readily available from motion capture, videos, and virtual reality, which could help address the data scarcity problem. However, due to the embodiment gap and missing dynamic information like force and torque, these demonstrations cannot be directly executed on robots. To bridge this gap, we propose Scalable Physics-Informed DExterous Retargeting (SPIDER), a physics-based retargeting framework to transform and augment kinematic-only human demonstrations to dynamically feasible robot trajectories at scale. Our key insight is that human demonstrations should provide global task structure and objective, while large-scale physics-based sampling with curriculum-style virtual contact guidance should refine trajectories to ensure dynamical feasibility and correct contact sequences. SPIDER scales across diverse 9 humanoid/dexterous hand embodiments and 6 datasets, improving success rates by 18% compared to standard sampling, while being 10X faster than reinforcement learning (RL) baselines, and enabling the generation of a 2.4M frames dynamic-feasible robot dataset for policy learning. As a universal physics-based retargeting method, SPIDER can work with diverse quality data and generate diverse and high-quality data to enable efficient policy learning with methods like RL.
DexCtrl: Towards Sim-to-Real Dexterity with Adaptive Controller Learning
May 02, 2025


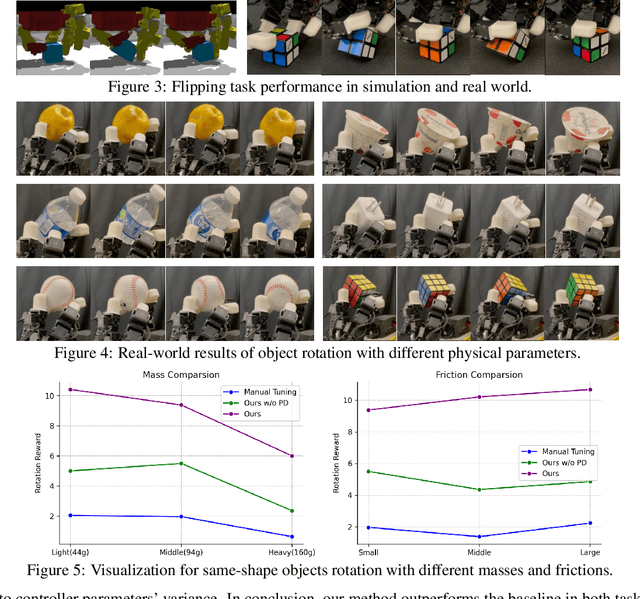
Dexterous manipulation has seen remarkable progress in recent years, with policies capable of executing many complex and contact-rich tasks in simulation. However, transferring these policies from simulation to real world remains a significant challenge. One important issue is the mismatch in low-level controller dynamics, where identical trajectories can lead to vastly different contact forces and behaviors when control parameters vary. Existing approaches often rely on manual tuning or controller randomization, which can be labor-intensive, task-specific, and introduce significant training difficulty. In this work, we propose a framework that jointly learns actions and controller parameters based on the historical information of both trajectory and controller. This adaptive controller adjustment mechanism allows the policy to automatically tune control parameters during execution, thereby mitigating the sim-to-real gap without extensive manual tuning or excessive randomization. Moreover, by explicitly providing controller parameters as part of the observation, our approach facilitates better reasoning over force interactions and improves robustness in real-world scenarios. Experimental results demonstrate that our method achieves improved transfer performance across a variety of dexterous tasks involving variable force conditions.
Geometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm
Mar 10, 2025We introduce Geometric Retargeting (GeoRT), an ultrafast, and principled neural hand retargeting algorithm for teleoperation, developed as part of our recent Dexterity Gen (DexGen) system. GeoRT converts human finger keypoints to robot hand keypoints at 1KHz, achieving state-of-the-art speed and accuracy with significantly fewer hyperparameters. This high-speed capability enables flexible postprocessing, such as leveraging a foundational controller for action correction like DexGen. GeoRT is trained in an unsupervised manner, eliminating the need for manual annotation of hand pairs. The core of GeoRT lies in novel geometric objective functions that capture the essence of retargeting: preserving motion fidelity, ensuring configuration space (C-space) coverage, maintaining uniform response through high flatness, pinch correspondence and preventing self-collisions. This approach is free from intensive test-time optimization, offering a more scalable and practical solution for real-time hand retargeting.
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
PromptMono: Cross Prompting Attention for Self-Supervised Monocular Depth Estimation in Challenging Environments
Jan 23, 2025



Considerable efforts have been made to improve monocular depth estimation under ideal conditions. However, in challenging environments, monocular depth estimation still faces difficulties. In this paper, we introduce visual prompt learning for predicting depth across different environments within a unified model, and present a self-supervised learning framework called PromptMono. It employs a set of learnable parameters as visual prompts to capture domain-specific knowledge. To integrate prompting information into image representations, a novel gated cross prompting attention (GCPA) module is proposed, which enhances the depth estimation in diverse conditions. We evaluate the proposed PromptMono on the Oxford Robotcar dataset and the nuScenes dataset. Experimental results demonstrate the superior performance of the proposed method.
Imagined Potential Games: A Framework for Simulating, Learning and Evaluating Interactive Behaviors
Nov 06, 2024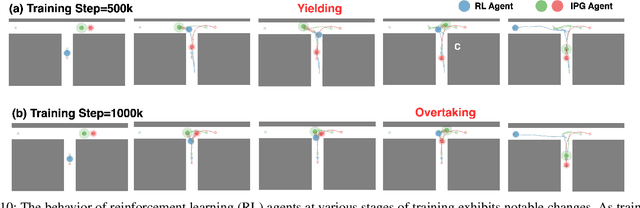


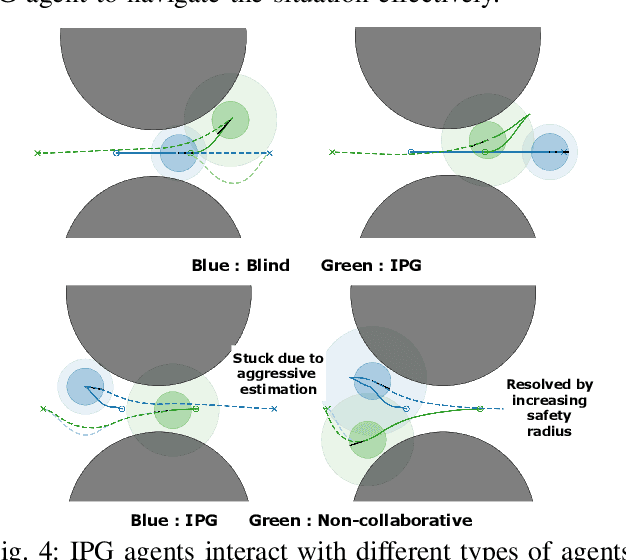
Interacting with human agents in complex scenarios presents a significant challenge for robotic navigation, particularly in environments that necessitate both collision avoidance and collaborative interaction, such as indoor spaces. Unlike static or predictably moving obstacles, human behavior is inherently complex and unpredictable, stemming from dynamic interactions with other agents. Existing simulation tools frequently fail to adequately model such reactive and collaborative behaviors, impeding the development and evaluation of robust social navigation strategies. This paper introduces a novel framework utilizing distributed potential games to simulate human-like interactions in highly interactive scenarios. Within this framework, each agent imagines a virtual cooperative game with others based on its estimation. We demonstrate this formulation can facilitate the generation of diverse and realistic interaction patterns in a configurable manner across various scenarios. Additionally, we have developed a gym-like environment leveraging our interactive agent model to facilitate the learning and evaluation of interactive navigation algorithms.
Efficient Sim-to-real Transfer of Contact-Rich Manipulation Skills with Online Admittance Residual Learning
Oct 16, 2023Learning contact-rich manipulation skills is essential. Such skills require the robots to interact with the environment with feasible manipulation trajectories and suitable compliance control parameters to enable safe and stable contact. However, learning these skills is challenging due to data inefficiency in the real world and the sim-to-real gap in simulation. In this paper, we introduce a hybrid offline-online framework to learn robust manipulation skills. We employ model-free reinforcement learning for the offline phase to obtain the robot motion and compliance control parameters in simulation \RV{with domain randomization}. Subsequently, in the online phase, we learn the residual of the compliance control parameters to maximize robot performance-related criteria with force sensor measurements in real time. To demonstrate the effectiveness and robustness of our approach, we provide comparative results against existing methods for assembly, pivoting, and screwing tasks.
Generalizable whole-body global manipulation of deformable linear objects by dual-arm robot in 3-D constrained environments
Oct 15, 2023Constrained environments are common in practical applications of manipulating deformable linear objects (DLOs), where movements of both DLOs and robots should be constrained. This task is high-dimensional and highly constrained owing to the highly deformable DLOs, dual-arm robots with high degrees of freedom, and 3-D complex environments, which render global planning challenging. Furthermore, accurate DLO models needed by planning are often unavailable owing to their strong nonlinearity and diversity, resulting in unreliable planned paths. This article focuses on the global moving and shaping of DLOs in constrained environments by dual-arm robots. The main objectives are 1) to efficiently and accurately accomplish this task, and 2) to achieve generalizable and robust manipulation of various DLOs. To this end, we propose a complementary framework with whole-body planning and control using appropriate DLO model representations. First, a global planner is proposed to efficiently find feasible solutions based on a simplified DLO energy model, which considers the full system states and all constraints to plan more reliable paths. Then, a closed-loop manipulation scheme is proposed to compensate for the modeling errors and enhance the robustness and accuracy, which incorporates a model predictive controller that real-time adjusts the robot motion based on an adaptive DLO motion model. The key novelty is that our framework can efficiently solve the high-dimensional problem subject to multiple constraints and generalize to various DLOs without elaborate model identifications. Experiments demonstrate that our framework can accomplish considerably more complicated tasks than existing works, with significantly higher efficiency, generalizability, and reliability.