 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinematics-Aware Diffusion Policy with Consistent 3D Observation and Action Space for Whole-Arm Robotic Manipulation
Dec 19, 2025



Whole-body control of robotic manipulators with awareness of full-arm kinematics is crucial for many manipulation scenarios involving body collision avoidance or body-object interactions, which makes it insufficient to consider only the end-effector poses in policy learning. The typical approach for whole-arm manipulation is to learn actions in the robot's joint space. However, the unalignment between the joint space and actual task space (i.e., 3D space) increases the complexity of policy learning, as generalization in task space requires the policy to intrinsically understand the non-linear arm kinematics, which is difficult to learn from limited demonstrations. To address this issue, this letter proposes a kinematics-aware imitation learning framework with consistent task, observation, and action spaces, all represented in the same 3D space. Specifically, we represent both robot states and actions using a set of 3D points on the arm body, naturally aligned with the 3D point cloud observations. This spatially consistent representation improves the policy's sample efficiency and spatial generalizability while enabling full-body control. Built upon the diffusion policy, we further incorporate kinematics priors into the diffusion processes to guarantee the kinematic feasibility of output actions. The joint angle commands are finally calculated through an optimization-based whole-body inverse kinematics solver for execution. Simulation and real-world experimental results demonstrate higher success rates and stronger spatial generalizability of our approach compared to existing methods in body-aware manipulation policy learning.
UniStateDLO: Unified Generative State Estimation and Tracking of Deformable Linear Objects Under Occlusion for Constrained Manipulation
Dec 19, 2025Perception of deformable linear objects (DLOs), such as cables, ropes, and wires, is the cornerstone for successful downstream manipulation. Although vision-based methods have been extensively explored, they remain highly vulnerable to occlusions that commonly arise in constrained manipulation environments due to surrounding obstacles, large and varying deformations, and limited viewpoints. Moreover, the high dimensionality of the state space, the lack of distinctive visual features, and the presence of sensor noises further compound the challenges of reliable DLO perception. To address these open issues, this paper presents UniStateDLO, the first complete DLO perception pipeline with deep-learning methods that achieves robust performance under severe occlusion, covering both single-frame state estimation and cross-frame state tracking from partial point clouds. Both tasks are formulated as conditional generative problems, leveraging the strong capability of diffusion models to capture the complex mapping between highly partial observations and high-dimensional DLO states. UniStateDLO effectively handles a wide range of occlusion patterns, including initial occlusion, self-occlusion, and occlusion caused by multiple objects. In addition, it exhibits strong data efficiency as the entire network is trained solely on a large-scale synthetic dataset, enabling zero-shot sim-to-real generalization without any real-world training data. Comprehensive simulation and real-world experiments demonstrate that UniStateDLO outperforms all state-of-the-art baselines in both estimation and tracking, producing globally smooth yet locally precise DLO state predictions in real time, even under substantial occlusions. Its integration as the front-end module in a closed-loop DLO manipulation system further demonstrates its ability to support stable feedback control in complex, constrained 3-D environments.
UltraDP: Generalizable Carotid Ultrasound Scanning with Force-Aware Diffusion Policy
Nov 19, 2025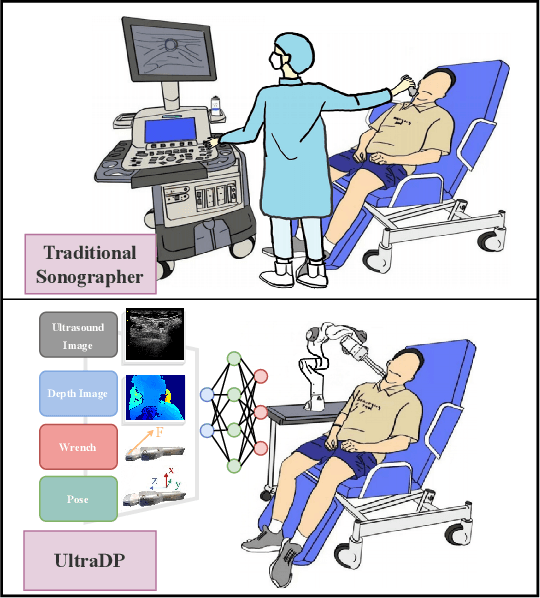
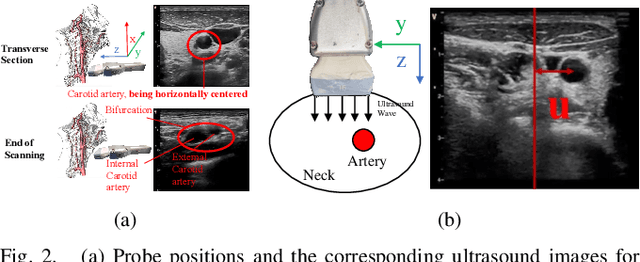
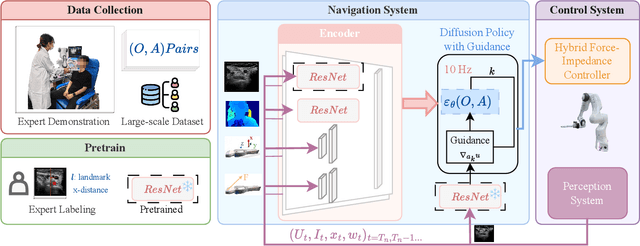

Ultrasound scanning is a critical imaging technique for real-time, non-invasive diagnostics. However, variations in patient anatomy and complex human-in-the-loop interactions pose significant challenges for autonomous robotic scanning. Existing ultrasound scanning robots are commonly limited to relatively low generalization and inefficient data utilization. To overcome these limitations, we present UltraDP, a Diffusion-Policy-based method that receives multi-sensory inputs (ultrasound images, wrist camera images, contact wrench, and probe pose) and generates actions that are fit for multi-modal action distributions in autonomous ultrasound scanning of carotid artery. We propose a specialized guidance module to enable the policy to output actions that center the artery in ultrasound images. To ensure stable contact and safe interaction between the robot and the human subject, a hybrid force-impedance controller is utilized to drive the robot to track such trajectories. Also, we have built a large-scale training dataset for carotid scanning comprising 210 scans with 460k sample pairs from 21 volunteers of both genders. By exploring our guidance module and DP's strong generalization ability, UltraDP achieves a 95% success rate in transverse scanning on previously unseen subjects, demonstrating its effectiveness.
Generalizable whole-body global manipulation of deformable linear objects by dual-arm robot in 3-D constrained environments
Oct 15, 2023Constrained environments are common in practical applications of manipulating deformable linear objects (DLOs), where movements of both DLOs and robots should be constrained. This task is high-dimensional and highly constrained owing to the highly deformable DLOs, dual-arm robots with high degrees of freedom, and 3-D complex environments, which render global planning challenging. Furthermore, accurate DLO models needed by planning are often unavailable owing to their strong nonlinearity and diversity, resulting in unreliable planned paths. This article focuses on the global moving and shaping of DLOs in constrained environments by dual-arm robots. The main objectives are 1) to efficiently and accurately accomplish this task, and 2) to achieve generalizable and robust manipulation of various DLOs. To this end, we propose a complementary framework with whole-body planning and control using appropriate DLO model representations. First, a global planner is proposed to efficiently find feasible solutions based on a simplified DLO energy model, which considers the full system states and all constraints to plan more reliable paths. Then, a closed-loop manipulation scheme is proposed to compensate for the modeling errors and enhance the robustness and accuracy, which incorporates a model predictive controller that real-time adjusts the robot motion based on an adaptive DLO motion model. The key novelty is that our framework can efficiently solve the high-dimensional problem subject to multiple constraints and generalize to various DLOs without elaborate model identifications. Experiments demonstrate that our framework can accomplish considerably more complicated tasks than existing works, with significantly higher efficiency, generalizability, and reliability.
Learning to Occlusion-Robustly Estimate 3-D States of Deformable Linear Objects from Single-Frame Point Clouds
Oct 04, 2022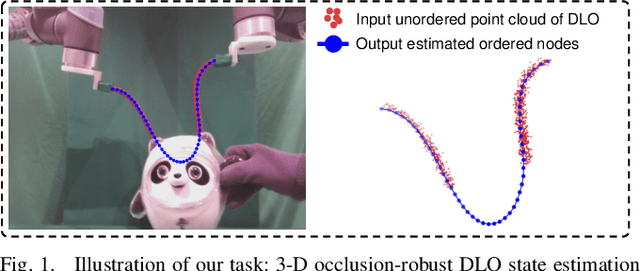
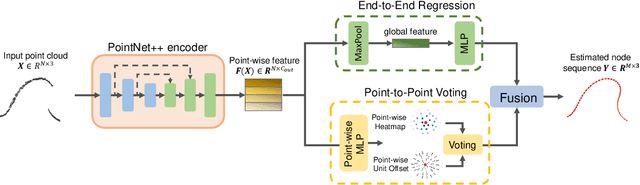
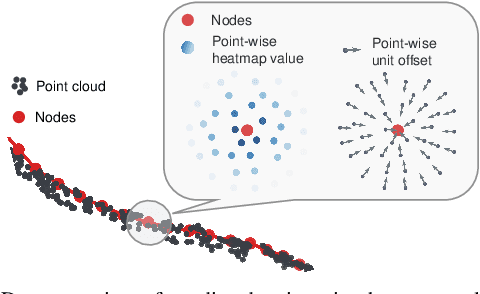
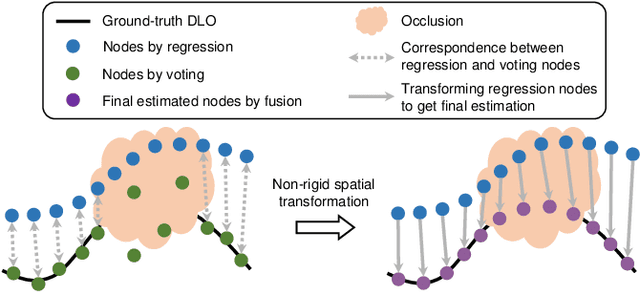
Accurately and robustly estimating the state of deformable linear objects (DLOs), such as ropes and wires, is crucial for DLO manipulation and other applications. However, it remains a challenging open issue due to the high dimensionality of the state space, frequent occlusion, and noises. This paper focuses on learning to robustly estimate the states of DLOs from single-frame point clouds in the presence of occlusions using a data-driven method. We propose a novel two-branch network architecture to exploit global and local information of input point cloud respectively and design a fusion module to effectively leverage both the advantages. Simulation and real-world experimental results demonstrate that our method can generate globally smooth and locally precise DLO state estimation results even with heavily occluded point clouds, which can be directly applied to real-world robotic manipulation of DLOs in 3-D space.
A Coarse-to-Fine Framework for Dual-Arm Manipulation of Deformable Linear Objects with Whole-Body Obstacle Avoidance
Sep 22, 2022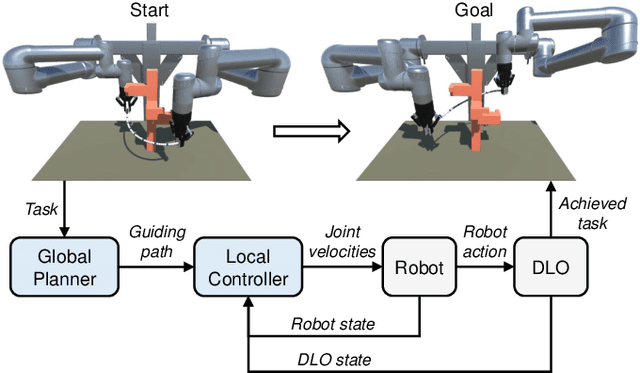



Manipulating deformable linear objects (DLOs) to achieve desired shapes in constrained environments with obstacles is a meaningful but challenging tasks. Global planning is necessary for such a highly-constrained task; however, accurate models of DLOs required by planners are difficult to obtain owing to their deformable nature, and the inevitable modeling errors significantly affect the planning results, probably resulting in task failure if the robot simply executes the planned path in an open-loop manner. In this paper, we propose a coarse-to-fine framework to combine global planning and local control for dual-arm manipulation of DLOs, capable of precisely achieving desired configurations and avoiding potential collisions between the DLO, robot, and obstacles. Specifically, the global planner refers to a simple yet effective DLO energy model and computes a coarse path to guarantee the feasibility of the task; then the local controller follows that path as guidance and further shapes it with closed-loop feedback to compensate for the planning errors and guarantee the accuracy of the task. Both simulations and real-world experiments demonstrate that our framework can robustly achieve desired DLO configurations in constrained environments with imprecise DLO models. which may not be reliably achieved by only planning or control.
Global Model Learning for Large Deformation Control of Elastic Deformable Linear Objects: An Efficient and Adaptive Approach
May 09, 2022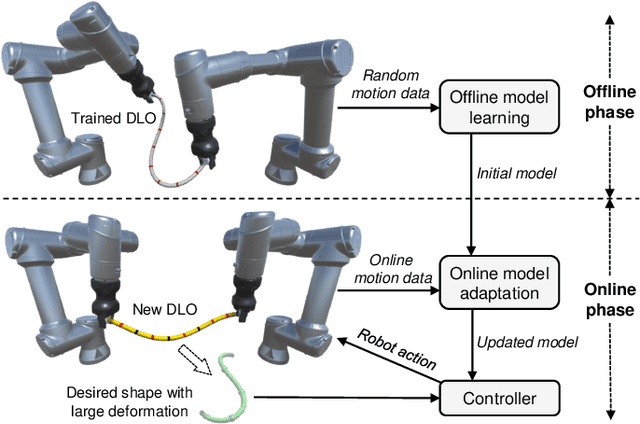
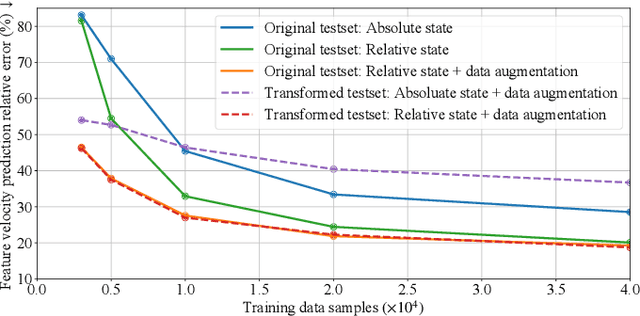
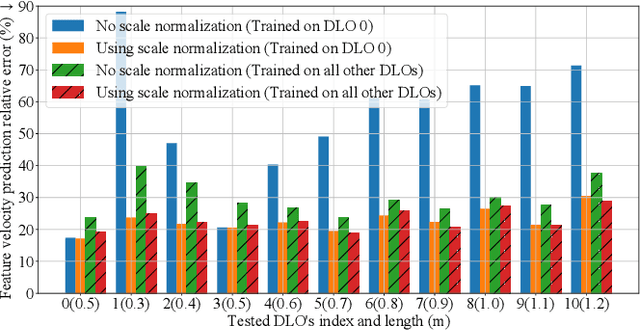

Robotic manipulation of deformable linear objects (DLOs) has broad application prospects in many fields. However, a key issue is to obtain the exact deformation models (i.e., how robot motion affects DLO deformation), which are hard to theoretically calculate and vary among different DLOs. Thus, shape control of DLOs is challenging, especially for large deformation control which requires global and more accurate models. In this paper, we propose a coupled offline and online data-driven method for efficiently learning a global deformation model, allowing for both accurate modeling through offline learning and further updating for new DLOs via online adaptation. Specifically, the model approximated by a neural network is first trained offline on random data, then seamlessly migrated to the online phase, and further updated online during actual manipulation. Several strategies are introduced to improve the model's efficiency and generalization ability. We propose a convex-optimization-based controller, and analyze the system's stability using the Lyapunov method. Detailed simulations and real-world experiments demonstrate that our method can efficiently and precisely estimate the deformation model, and achieve large deformation control of untrained DLOs in 2D and 3D dual-arm manipulation tasks better than the existing methods. It accomplishes all 24 tasks with different desired shapes on different DLOs in the real world, using only simulation data for the offline learning.
Glance and Focus Networks for Dynamic Visual Recognition
Jan 09, 2022
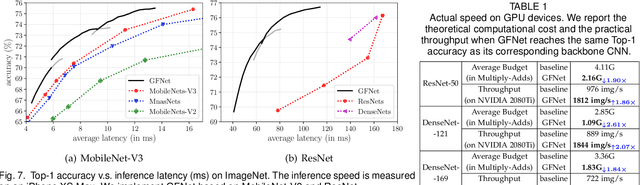
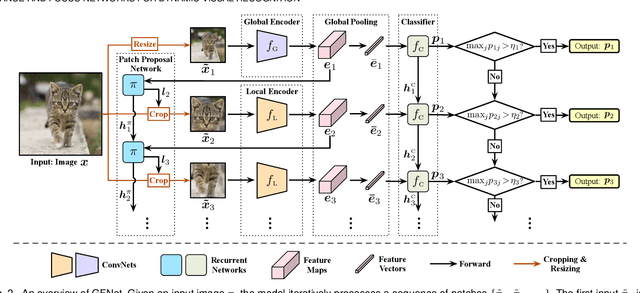

Spatial redundancy widely exists in visual recognition tasks, i.e., discriminative features in an image or video frame usually correspond to only a subset of pixels, while the remaining regions are irrelevant to the task at hand. Therefore, static models which process all the pixels with an equal amount of computation result in considerable redundancy in terms of time and space consumption. In this paper, we formulate the image recognition problem as a sequential coarse-to-fine feature learning process, mimicking the human visual system. Specifically, the proposed Glance and Focus Network (GFNet) first extracts a quick global representation of the input image at a low resolution scale, and then strategically attends to a series of salient (small) regions to learn finer features. The sequential process naturally facilitates adaptive inference at test time, as it can be terminated once the model is sufficiently confident about its prediction, avoiding further redundant computation. It is worth noting that the problem of locating discriminant regions in our model is formulated as a reinforcement learning task, thus requiring no additional manual annotations other than classification labels. GFNet is general and flexible as it is compatible with any off-the-shelf backbone models (such as MobileNets, EfficientNets and TSM), which can be conveniently deployed as the feature extractor. Extensive experiments on a variety of image classification and video recognition tasks and with various backbone models demonstrate the remarkable efficiency of our method. For example, it reduces the average latency of the highly efficient MobileNet-V3 on an iPhone XS Max by 1.3x without sacrificing accuracy. Code and pre-trained models are available at https://github.com/blackfeather-wang/GFNet-Pytorch.
Glance and Focus: a Dynamic Approach to Reducing Spatial Redundancy in Image Classification
Oct 11, 2020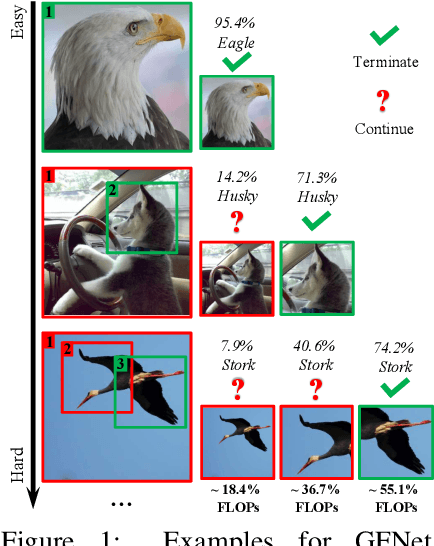
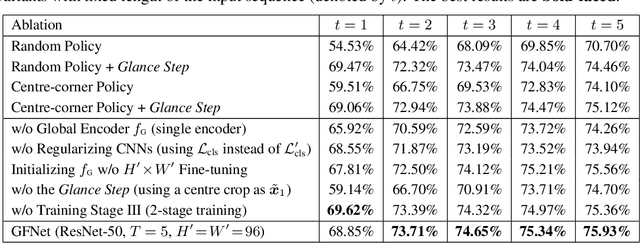


The accuracy of deep convolutional neural networks (CNNs) generally improves when fueled with high resolution images. However, this often comes at a high computational cost and high memory footprint. Inspired by the fact that not all regions in an image are task-relevant, we propose a novel framework that performs efficient image classification by processing a sequence of relatively small inputs, which are strategically selected from the original image with reinforcement learning. Such a dynamic decision process naturally facilitates adaptive inference at test time, i.e., it can be terminated once the model is sufficiently confident about its prediction and thus avoids further redundant computation. Notably, our framework is general and flexible as it is compatible with most of the state-of-the-art light-weighted CNNs (such as MobileNets, EfficientNets and RegNets), which can be conveniently deployed as the backbone feature extractor. Experiments on ImageNet show that our method consistently improves the computational efficiency of a wide variety of deep models. For example, it further reduces the average latency of the highly efficient MobileNet-V3 on an iPhone XS Max by 20% without sacrificing accuracy. Code and pre-trained models are available at https://github.com/blackfeather-wang/GFNet-Pytorch.
Graph-based Kinship Reasoning Network
Apr 22, 2020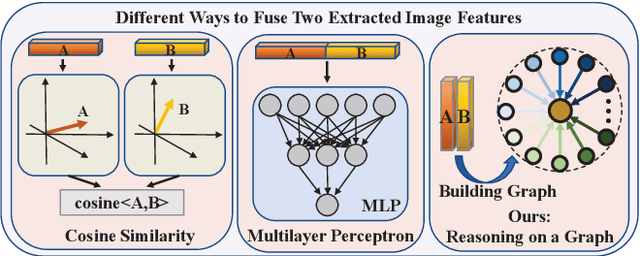
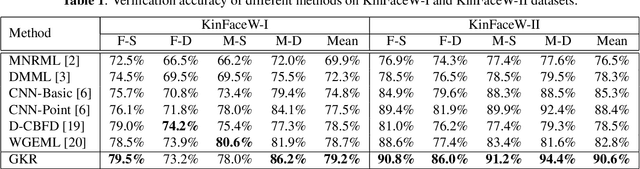
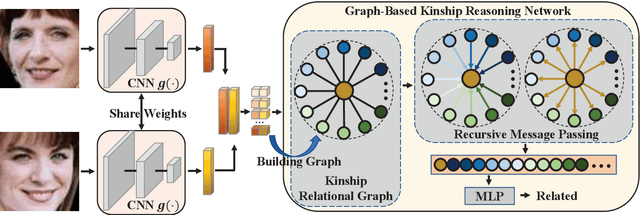
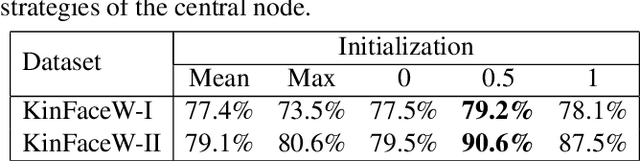
In this paper, we propose a graph-based kinship reasoning (GKR) network for kinship verification, which aims to effectively perform relational reasoning on the extracted features of an image pair. Unlike most existing methods which mainly focus on how to learn discriminative features, our method considers how to compare and fuse the extracted feature pair to reason about the kin relations. The proposed GKR constructs a star graph called kinship relational graph where each peripheral node represents the information comparison in one feature dimension and the central node is used as a bridge for information communication among peripheral nodes. Then the GKR performs relational reasoning on this graph with recursive message passing. Extensive experimental results on the KinFaceW-I and KinFaceW-II datasets show that the proposed GKR outperforms the state-of-the-art methods.