 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloRec: Holistic Encoding and Interleaved Reasoning for Generative Recommendation
Jun 13, 2026Generative recommendation models that formulate the task as sequence generation overcome the objective fragmentation problem of traditional cascade architectures, yet existing approaches still suffer from flat semantic representations lacking hierarchical structure for multi-step reasoning and an externally constructed chain-of-thought (CoT) that requires expensive annotations and remains disconnected from the generation objective. We propose HoloRec, an endogenous chain-of-thought recommendation mechanism that unifies representation, reasoning, and generation by constructing a hierarchical semantic encoding matrix via multi-granularity nested residual quantization optimized by a holistic reconstruction loss. HoloRec supports two inference modes: a non-thinking mode that uses lightweight multi-granularity supervised alignment for fast prediction, and a thinking mode that employs an interleaved reasoning scheme to generate CoT steps on the fly, directly embedding reasoning into the generation process without external data. Experiments on multiple public recommendation datasets demonstrate that HoloRec consistently outperforms baselines, with especially significant gains in sparse scenarios, and the thinking mode achieves better accuracy than the non-thinking mode with only modest inference overhead.
Multi-Camera View Scaling for Data-Efficient Robot Imitation Learning
Apr 01, 2026The generalization ability of imitation learning policies for robotic manipulation is fundamentally constrained by the diversity of expert demonstrations, while collecting demonstrations across varied environments is costly and difficult in practice. In this paper, we propose a practical framework that exploits inherent scene diversity without additional human effort by scaling camera views during demonstration collection. Instead of acquiring more trajectories, multiple synchronized camera perspectives are used to generate pseudo-demonstrations from each expert trajectory, which enriches the training distribution and improves viewpoint invariance in visual representations. We analyze how different action spaces interact with view scaling and show that camera-space representations further enhance diversity. In addition, we introduce a multiview action aggregation method that allows single-view policies to benefit from multiple cameras during deployment. Extensive experiments in simulation and real-world manipulation tasks demonstrate significant gains in data efficiency and generalization compared to single-view baselines. Our results suggest that scaling camera views provides a practical and scalable solution for imitation learning, which requires minimal additional hardware setup and integrates seamlessly with existing imitation learning algorithms. The website of our project is https://yichen928.github.io/robot_multiview.
Seeing to Act, Prompting to Specify: A Bayesian Factorization of Vision Language Action Policy
Dec 12, 2025The pursuit of out-of-distribution generalization in Vision-Language-Action (VLA) models is often hindered by catastrophic forgetting of the Vision-Language Model (VLM) backbone during fine-tuning. While co-training with external reasoning data helps, it requires experienced tuning and data-related overhead. Beyond such external dependencies, we identify an intrinsic cause within VLA datasets: modality imbalance, where language diversity is much lower than visual and action diversity. This imbalance biases the model toward visual shortcuts and language forgetting. To address this, we introduce BayesVLA, a Bayesian factorization that decomposes the policy into a visual-action prior, supporting seeing-to-act, and a language-conditioned likelihood, enabling prompt-to-specify. This inherently preserves generalization and promotes instruction following. We further incorporate pre- and post-contact phases to better leverage pre-trained foundation models. Information-theoretic analysis formally validates our effectiveness in mitigating shortcut learning. Extensive experiments show superior generalization to unseen instructions, objects, and environments compared to existing methods. Project page is available at: https://xukechun.github.io/papers/BayesVLA.
DexCtrl: Towards Sim-to-Real Dexterity with Adaptive Controller Learning
May 02, 2025


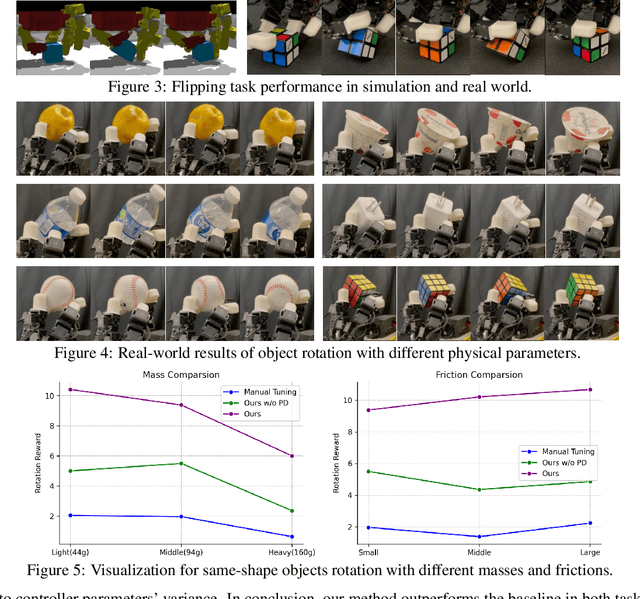
Dexterous manipulation has seen remarkable progress in recent years, with policies capable of executing many complex and contact-rich tasks in simulation. However, transferring these policies from simulation to real world remains a significant challenge. One important issue is the mismatch in low-level controller dynamics, where identical trajectories can lead to vastly different contact forces and behaviors when control parameters vary. Existing approaches often rely on manual tuning or controller randomization, which can be labor-intensive, task-specific, and introduce significant training difficulty. In this work, we propose a framework that jointly learns actions and controller parameters based on the historical information of both trajectory and controller. This adaptive controller adjustment mechanism allows the policy to automatically tune control parameters during execution, thereby mitigating the sim-to-real gap without extensive manual tuning or excessive randomization. Moreover, by explicitly providing controller parameters as part of the observation, our approach facilitates better reasoning over force interactions and improves robustness in real-world scenarios. Experimental results demonstrate that our method achieves improved transfer performance across a variety of dexterous tasks involving variable force conditions.
DexH2R: Task-oriented Dexterous Manipulation from Human to Robots
Nov 07, 2024Dexterous manipulation is a critical aspect of human capability, enabling interaction with a wide variety of objects. Recent advancements in learning from human demonstrations and teleoperation have enabled progress for robots in such ability. However, these approaches either require complex data collection such as costly human effort for eye-robot contact, or suffer from poor generalization when faced with novel scenarios. To solve both challenges, we propose a framework, DexH2R, that combines human hand motion retargeting with a task-oriented residual action policy, improving task performance by bridging the embodiment gap between human and robotic dexterous hands. Specifically, DexH2R learns the residual policy directly from retargeted primitive actions and task-oriented rewards, eliminating the need for labor-intensive teleoperation systems. Moreover, we incorporate test-time guidance for novel scenarios by taking in desired trajectories of human hands and objects, allowing the dexterous hand to acquire new skills with high generalizability. Extensive experiments in both simulation and real-world environments demonstrate the effectiveness of our work, outperforming prior state-of-the-arts by 40% across various settings.
X-Drive: Cross-modality consistent multi-sensor data synthesis for driving scenarios
Nov 02, 2024



Recent advancements have exploited diffusion models for the synthesis of either LiDAR point clouds or camera image data in driving scenarios. Despite their success in modeling single-modality data marginal distribution, there is an under-exploration in the mutual reliance between different modalities to describe complex driving scenes. To fill in this gap, we propose a novel framework, X-DRIVE, to model the joint distribution of point clouds and multi-view images via a dual-branch latent diffusion model architecture. Considering the distinct geometrical spaces of the two modalities, X-DRIVE conditions the synthesis of each modality on the corresponding local regions from the other modality, ensuring better alignment and realism. To further handle the spatial ambiguity during denoising, we design the cross-modality condition module based on epipolar lines to adaptively learn the cross-modality local correspondence. Besides, X-DRIVE allows for controllable generation through multi-level input conditions, including text, bounding box, image, and point clouds. Extensive results demonstrate the high-fidelity synthetic results of X-DRIVE for both point clouds and multi-view images, adhering to input conditions while ensuring reliable cross-modality consistency. Our code will be made publicly available at https://github.com/yichen928/X-Drive.
PhyGrasp: Generalizing Robotic Grasping with Physics-informed Large Multimodal Models
Feb 26, 2024



Robotic grasping is a fundamental aspect of robot functionality, defining how robots interact with objects. Despite substantial progress, its generalizability to counter-intuitive or long-tailed scenarios, such as objects with uncommon materials or shapes, remains a challenge. In contrast, humans can easily apply their intuitive physics to grasp skillfully and change grasps efficiently, even for objects they have never seen before. This work delves into infusing such physical commonsense reasoning into robotic manipulation. We introduce PhyGrasp, a multimodal large model that leverages inputs from two modalities: natural language and 3D point clouds, seamlessly integrated through a bridge module. The language modality exhibits robust reasoning capabilities concerning the impacts of diverse physical properties on grasping, while the 3D modality comprehends object shapes and parts. With these two capabilities, PhyGrasp is able to accurately assess the physical properties of object parts and determine optimal grasping poses. Additionally, the model's language comprehension enables human instruction interpretation, generating grasping poses that align with human preferences. To train PhyGrasp, we construct a dataset PhyPartNet with 195K object instances with varying physical properties and human preferences, alongside their corresponding language descriptions. Extensive experiments conducted in the simulation and on the real robots demonstrate that PhyGrasp achieves state-of-the-art performance, particularly in long-tailed cases, e.g., about 10% improvement in success rate over GraspNet. Project page: https://sites.google.com/view/phygrasp
Failure-aware Policy Learning for Self-assessable Robotics Tasks
Feb 25, 2023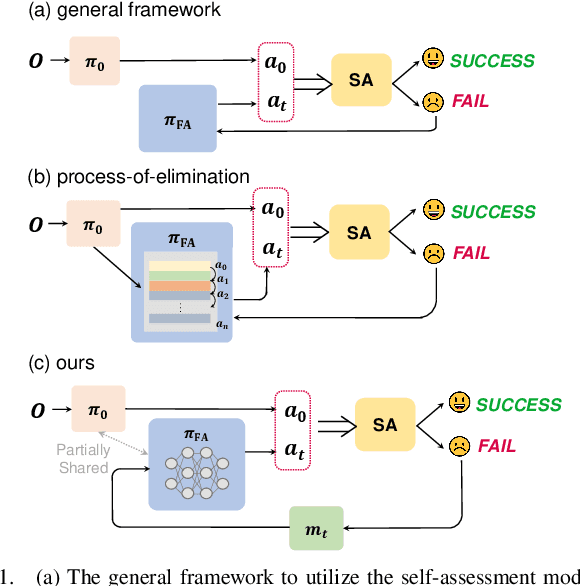
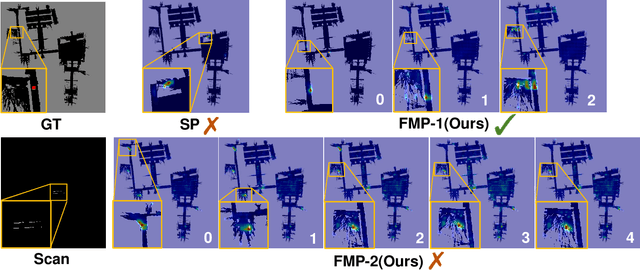
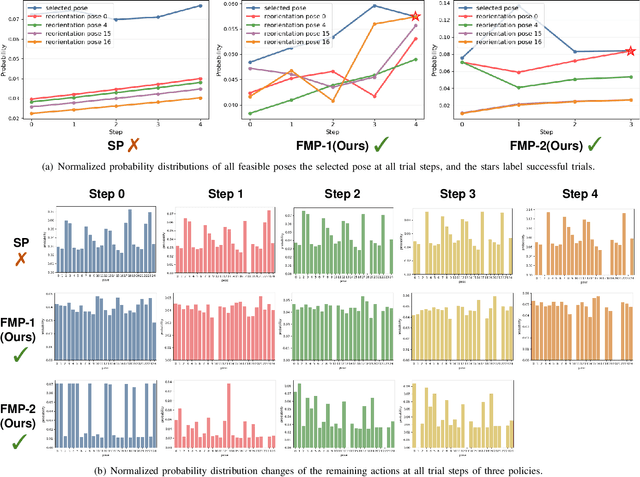
Self-assessment rules play an essential role in safe and effective real-world robotic applications, which verify the feasibility of the selected action before actual execution. But how to utilize the self-assessment results to re-choose actions remains a challenge. Previous methods eliminate the selected action evaluated as failed by the self-assessment rules, and re-choose one with the next-highest affordance~(i.e. process-of-elimination strategy [1]), which ignores the dependency between the self-assessment results and the remaining untried actions. However, this dependency is important since the previous failures might help trim the remaining over-estimated actions. In this paper, we set to investigate this dependency by learning a failure-aware policy. We propose two architectures for the failure-aware policy by representing the self-assessment results of previous failures as the variable state, and leveraging recurrent neural networks to implicitly memorize the previous failures. Experiments conducted on three tasks demonstrate that our method can achieve better performances with higher task success rates by less trials. Moreover, when the actions are correlated, learning a failure-aware policy can achieve better performance than the process-of-elimination strategy.
A Joint Modeling of Vision-Language-Action for Target-oriented Grasping in Clutter
Feb 24, 2023



We focus on the task of language-conditioned grasping in clutter, in which a robot is supposed to grasp the target object based on a language instruction. Previous works separately conduct visual grounding to localize the target object, and generate a grasp for that object. However, these works require object labels or visual attributes for grounding, which calls for handcrafted rules in planner and restricts the range of language instructions. In this paper, we propose to jointly model vision, language and action with object-centric representation. Our method is applicable under more flexible language instructions, and not limited by visual grounding error. Besides, by utilizing the powerful priors from the pre-trained multi-modal model and grasp model, sample efficiency is effectively improved and the sim2real problem is relived without additional data for transfer. A series of experiments carried out in simulation and real world indicate that our method can achieve better task success rate by less times of motion under more flexible language instructions. Moreover, our method is capable of generalizing better to scenarios with unseen objects and language instructions.