 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNS: Correspondence Encoded Neural Image Servo Policy
Sep 16, 2023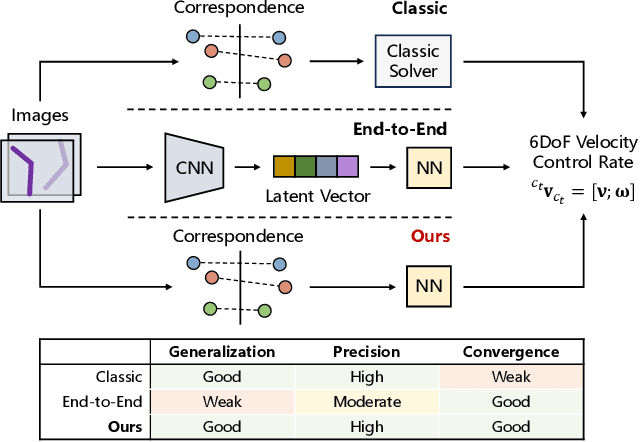
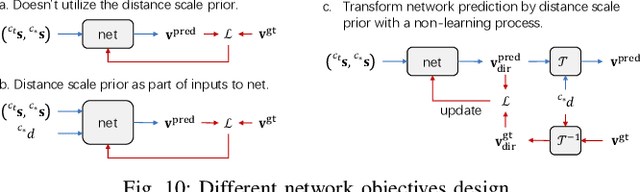
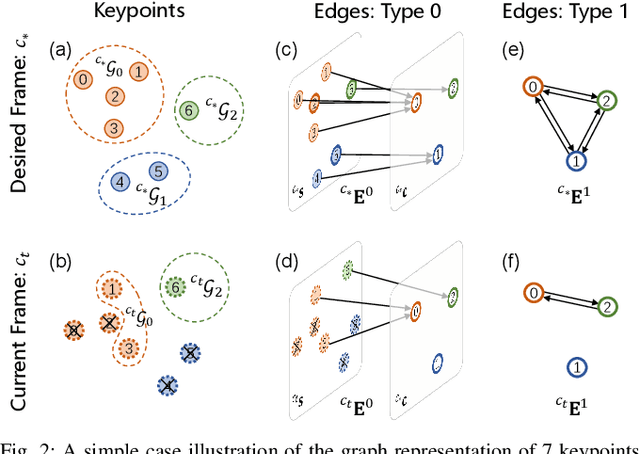
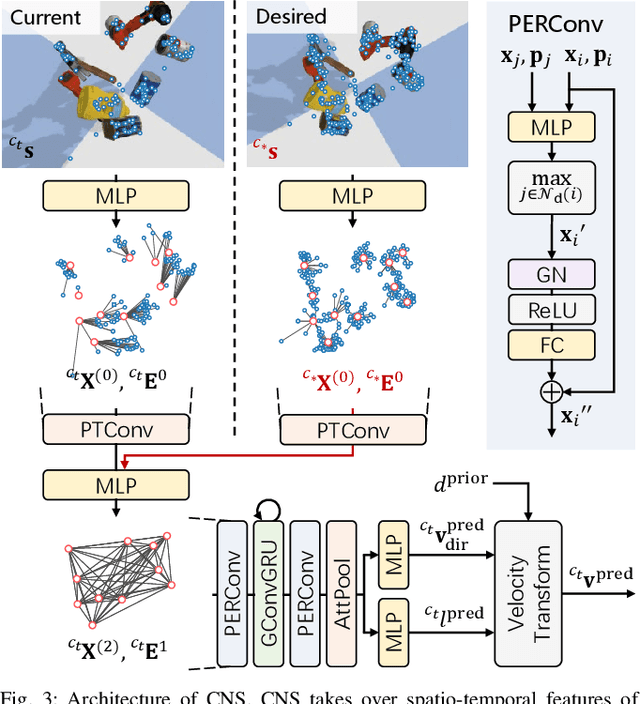
Image servo is an indispensable technique in robotic applications that helps to achieve high precision positioning. The intermediate representation of image servo policy is important to sensor input abstraction and policy output guidance. Classical approaches achieve high precision but require clean keypoint correspondence, and suffer from limited convergence basin or weak feature error robustness. Recent learning-based methods achieve moderate precision and large convergence basin on specific scenes but face issues when generalizing to novel environments. In this paper, we encode keypoints and correspondence into a graph and use graph neural network as architecture of controller. This design utilizes both advantages: generalizable intermediate representation from keypoint correspondence and strong modeling ability from neural network. Other techniques including realistic data generation, feature clustering and distance decoupling are proposed to further improve efficiency, precision and generalization. Experiments in simulation and real-world verify the effectiveness of our method in speed (maximum 40fps along with observer), precision (<0.3{\deg} and sub-millimeter accuracy) and generalization (sim-to-real without fine-tuning). Project homepage (full paper with supplementary text, video and code): https://hhcaz.github.io/CNS-home
Learning adaptive manipulation of objects with revolute joint: A case study on varied cabinet doors opening
Apr 28, 2023



This paper introduces a learning-based framework for robot adaptive manipulating the object with a revolute joint in unstructured environments. We concentrate our discussion on various cabinet door opening tasks. To improve the performance of Deep Reinforcement Learning in this scene, we analytically provide an efficient sampling manner utilizing the constraints of the objects. To open various kinds of doors, we add encoded environment parameters that define the various environments to the input of out policy. To transfer the policy into the real world, we train an adaptation module in simulation and fine-tune the adaptation module to cut down the impact of the policy-unaware environment parameters. We design a series of experiments to validate the efficacy of our framework. Additionally, we testify to the model's performance in the real world compared to the traditional door opening method.
A Hyper-network Based End-to-end Visual Servoing with Arbitrary Desired Poses
Apr 18, 2023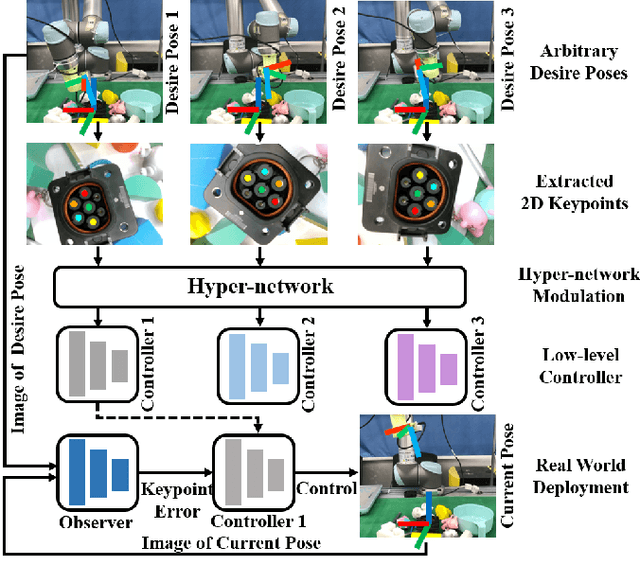
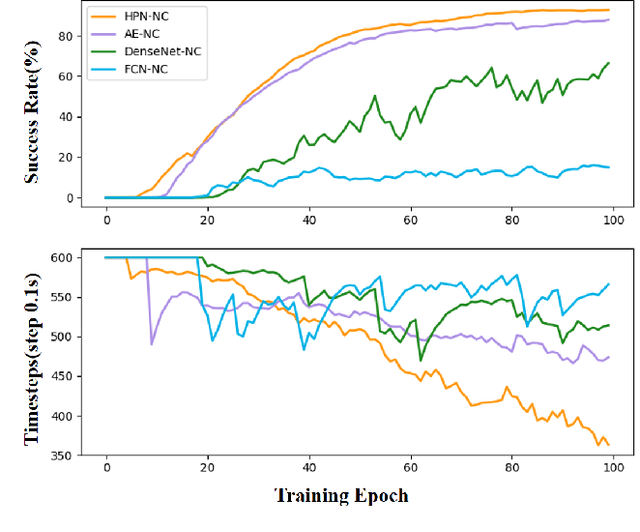
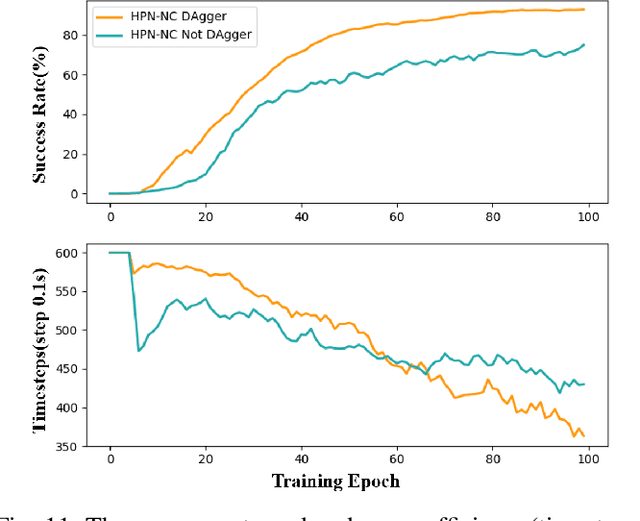
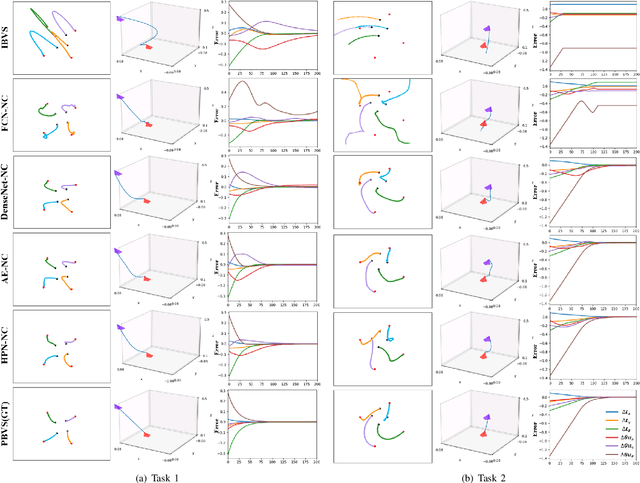
Recently, several works achieve end-to-end visual servoing (VS) for robotic manipulation by replacing traditional controller with differentiable neural networks, but lose the ability to servo arbitrary desired poses. This letter proposes a differentiable architecture for arbitrary pose servoing: a hyper-network based neural controller (HPN-NC). To achieve this, HPN-NC consists of a hyper net and a low-level controller, where the hyper net learns to generate the parameters of the low-level controller and the controller uses the 2D keypoints error for control like traditional image-based visual servoing (IBVS). HPN-NC can complete 6 degree of freedom visual servoing with large initial offset. Taking advantage of the fully differentiable nature of HPN-NC, we provide a three-stage training procedure to servo real world objects. With self-supervised end-to-end training, the performance of the integrated model can be further improved in unseen scenes and the amount of manual annotations can be significantly reduced.
Failure-aware Policy Learning for Self-assessable Robotics Tasks
Feb 25, 2023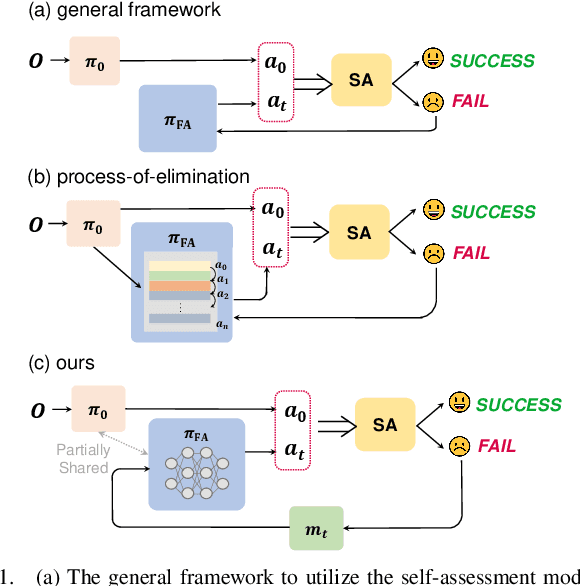
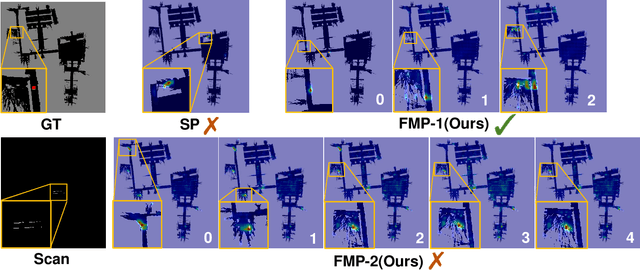
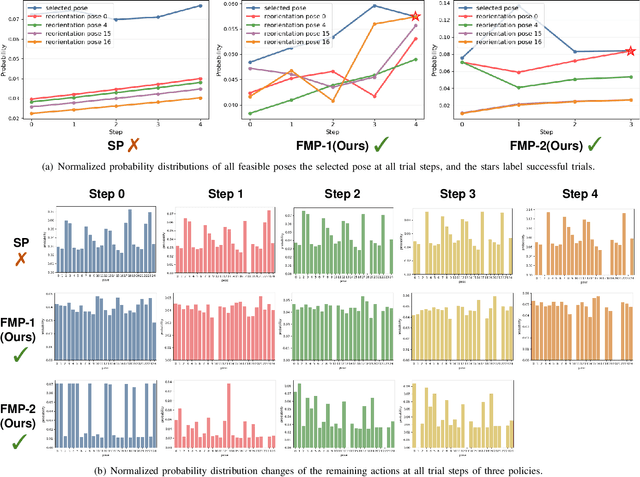
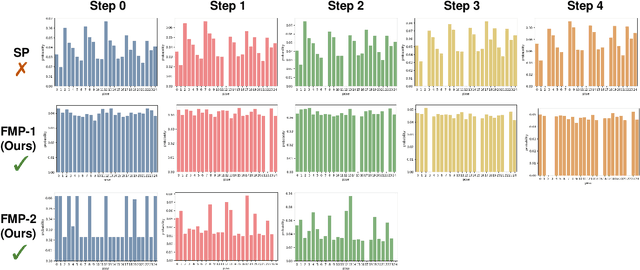
Self-assessment rules play an essential role in safe and effective real-world robotic applications, which verify the feasibility of the selected action before actual execution. But how to utilize the self-assessment results to re-choose actions remains a challenge. Previous methods eliminate the selected action evaluated as failed by the self-assessment rules, and re-choose one with the next-highest affordance~(i.e. process-of-elimination strategy [1]), which ignores the dependency between the self-assessment results and the remaining untried actions. However, this dependency is important since the previous failures might help trim the remaining over-estimated actions. In this paper, we set to investigate this dependency by learning a failure-aware policy. We propose two architectures for the failure-aware policy by representing the self-assessment results of previous failures as the variable state, and leveraging recurrent neural networks to implicitly memorize the previous failures. Experiments conducted on three tasks demonstrate that our method can achieve better performances with higher task success rates by less trials. Moreover, when the actions are correlated, learning a failure-aware policy can achieve better performance than the process-of-elimination strategy.
Learning A Simulation-based Visual Policy for Real-world Peg In Unseen Holes
May 09, 2022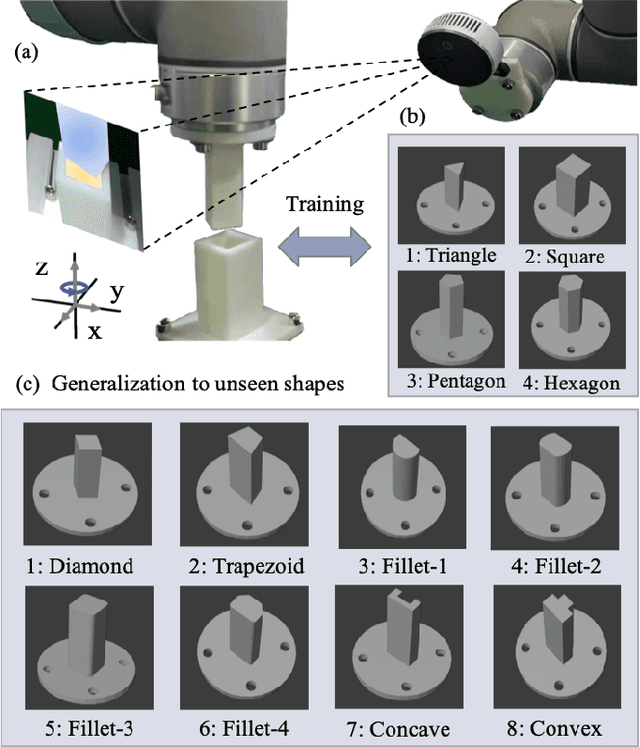

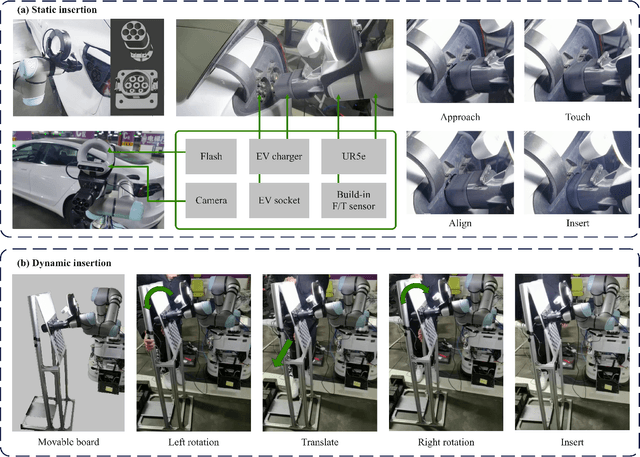
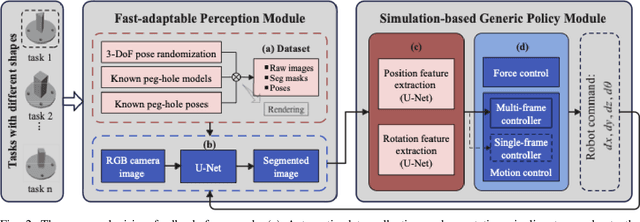
This paper proposes a learning-based visual peg-in-hole that enables training with several shapes in simulation, and adapting to arbitrary unseen shapes in real world with minimal sim-to-real cost. The core idea is to decouple the generalization of the sensory-motor policy to the design of a fast-adaptable perception module and a simulated generic policy module. The framework consists of a segmentation network (SN), a virtual sensor network (VSN), and a controller network (CN). Concretely, the VSN is trained to measure the pose of the unseen shape from a segmented image. After that, given the shape-agnostic pose measurement, the CN is trained to achieve generic peg-in-hole. Finally, when applying to real unseen holes, we only have to fine-tune the SN required by the simulated VSN+CN. To further minimize the transfer cost, we propose to automatically collect and annotate the data for the SN after one-minute human teaching. Simulated and real-world results are presented under the configurations of eye-to/in-hand. An electric vehicle charging system with the proposed policy inside achieves a 10/10 success rate in 2-3s, using only hundreds of auto-labeled samples for the SN transfer.
Learning to Fill the Seam by Vision: Sub-millimeter Peg-in-hole on Unseen Shapes in Real World
Apr 20, 2022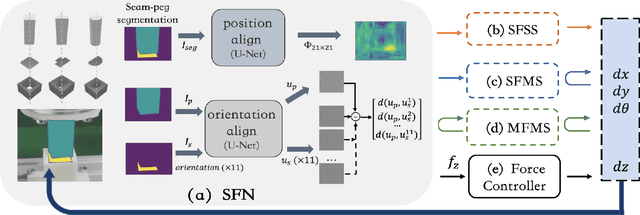
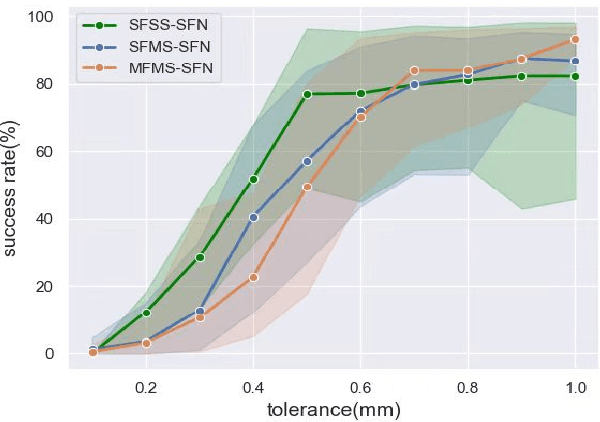
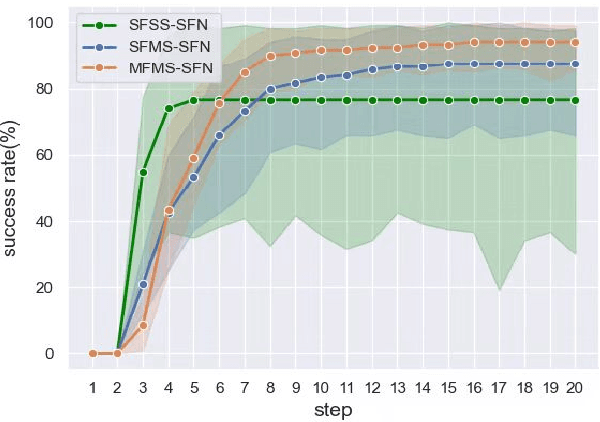

In the peg insertion task, human pays attention to the seam between the peg and the hole and tries to fill it continuously with visual feedback. By imitating the human behavior, we design architectures with position and orientation estimators based on the seam representation for pose alignment, which proves to be general to the unseen peg geometries. By putting the estimators into the closed-loop control with reinforcement learning, we further achieve a higher or comparable success rate, efficiency, and robustness compared with the baseline methods. The policy is trained totally in simulation without any manual intervention. To achieve sim-to-real, a learnable segmentation module with automatic data collecting and labeling can be easily trained to decouple the perception and the policy, which helps the model trained in simulation quickly adapt to the real world with negligible effort. Results are presented in simulation and on a physical robot. Code, videos, and supplemental material are available at https://github.com/xieliang555/SFN.git
Electric Vehicle Automatic Charging System Based on Vision-force Fusion
Oct 18, 2021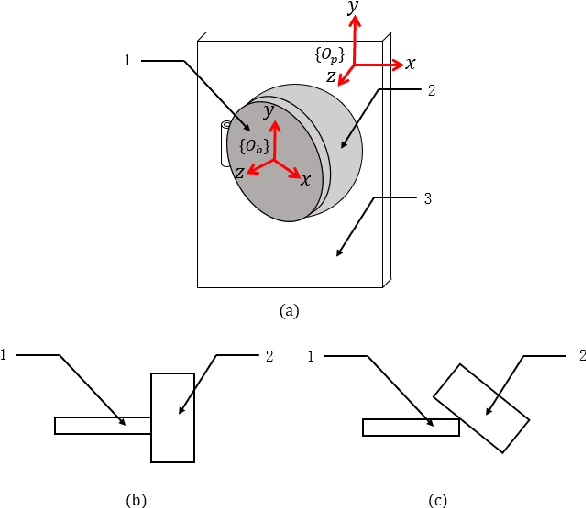
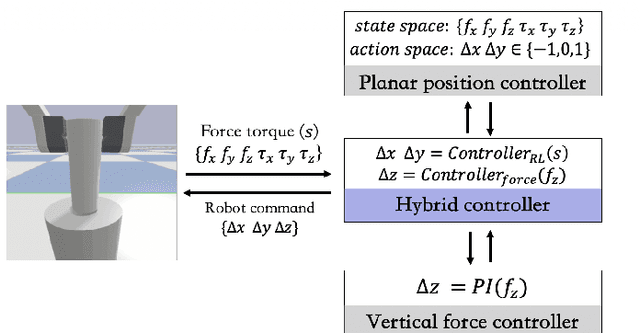
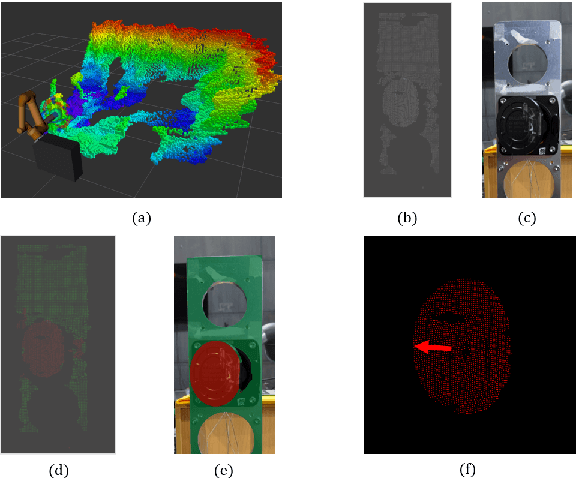

Electric vehicles are an emerging means of transportation with environmental friendliness. The automatic charging is a hot topic in this field that is full of challenges. We introduce a complete automatic charging system based on vision-force fusion, which includes perception, planning and control for robot manipulations of the system. We design the whole system in simulation and transfer it to the real world. The experimental results prove the effectiveness of our system.
Efficient Object Manipulation to an Arbitrary Goal Pose: Learning-based Anytime Prioritized Planning
Sep 22, 2021
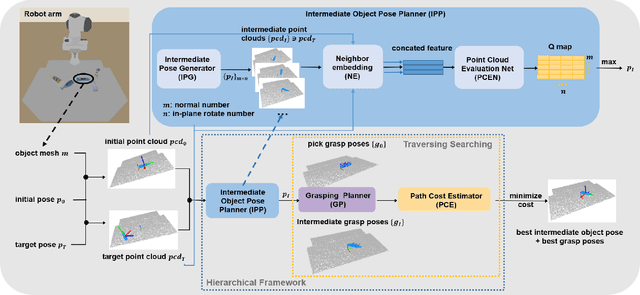
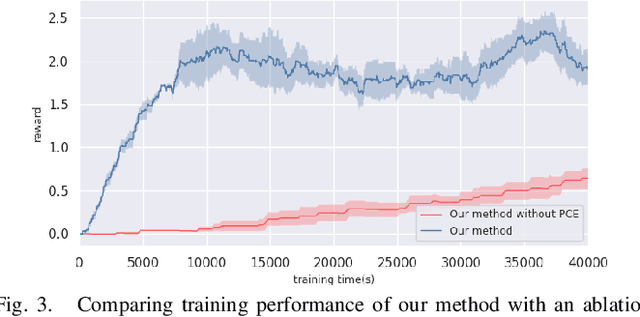
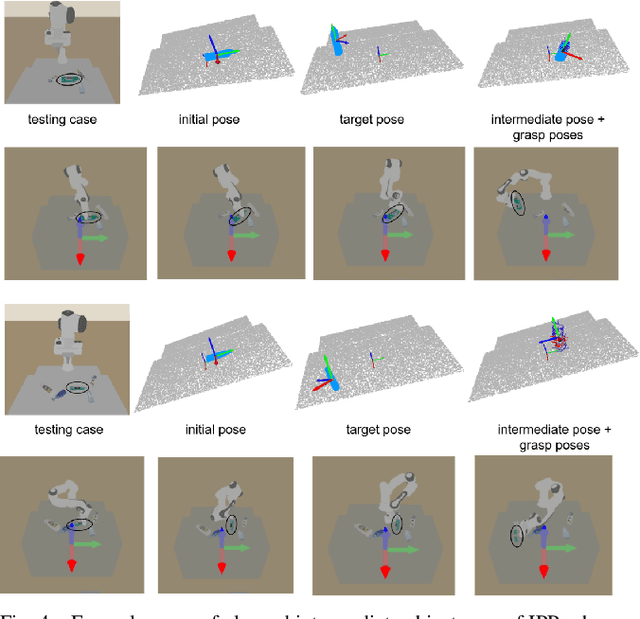
We focus on the task of object manipulation to an arbitrary goal pose, in which a robot is supposed to pick an assigned object to place at the goal position with a specific pose. However, limited by the execution space of the manipulator with gripper, one-step picking, moving and releasing might be failed, where an intermediate object pose is required as a transition. In this paper, we propose a learning-driven anytime prioritized search-based solver to find a feasible solution with low path cost in a short time. In our work, the problem is formulated as a hierarchical learning problem, with the high level aiming at finding an intermediate object pose, and the low-level manipulator path planning between adjacent grasps. We learn an off-line training path cost estimator to predict approximate path planning costs, which serve as pseudo rewards to allow for pre-training the high-level planner without interacting with the simulator. To deal with the problem of distribution mismatch of the cost net and the actual execution cost space, a refined training stage is conducted with simulation interaction. A series of experiments carried out in simulation and real world indicate that our system can achieve better performances in the object manipulation task with less time and less cost.
Neural Motion Prediction for In-flight Uneven Object Catching
Mar 15, 2021
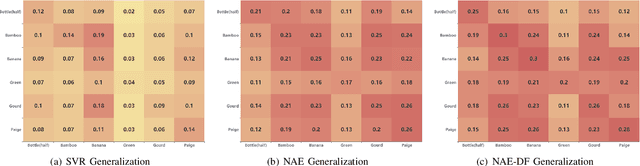


In-flight objects capture is extremely challenging. The robot is required to complete trajectory prediction, interception position calculation and motion planning in sequence within tens of milliseconds. As in-flight uneven objects are affected by various kinds of forces, motion prediction is difficult for a time-varying acceleration. In order to compensate the system's non-linearity, we introduce the Neural Acceleration Estimator (NAE) that estimates the varying acceleration by observing a small fragment of previous deflected trajectory. Moreover, end-to-end training with Differantiable Filter (NAE-DF) gives a supervision for measurement uncertainty and further improves the prediction accuracy. Experimental results show that motion prediction with NAE and NAE-DF is superior to other methods and has a good generalization performance on unseen objects. We test our methods on a robot, performing velocity control in real world and respectively achieve 83.3% and 86.7% success rate on a ploy urethane banana and a gourd. We also release an object in-flight dataset containing 1,500 trajectorys for uneven objects.
Efficient learning of goal-oriented push-grasping synergy in clutter
Mar 09, 2021

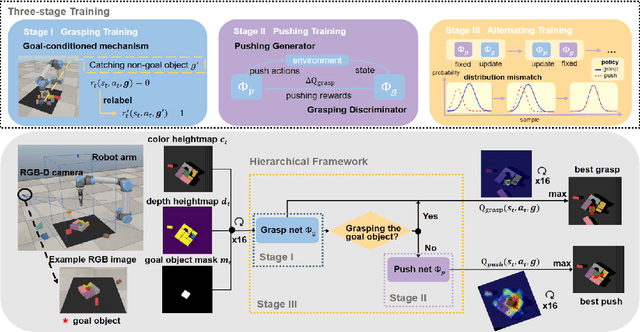
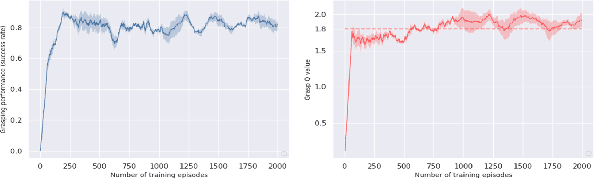
We focus on the task of goal-oriented grasping, in which a robot is supposed to grasp a pre-assigned goal object in clutter and needs some pre-grasp actions such as pushes to enable stable grasps. However, sample inefficiency remains a main challenge. In this paper, a goal-conditioned hierarchical reinforcement learning formulation with high sample efficiency is proposed to learn a push-grasping policy for grasping a specific object in clutter. In our work, sample efficiency is improved by two means. First, we use a goal-conditioned mechanism by goal relabeling to enrich the replay buffer. Second, the pushing and grasping policies are respectively regarded as a generator and a discriminator and the pushing policy is trained with supervision of the grasping discriminator, thus densifying pushing rewards. To deal with the problem of distribution mismatch caused by different training settings of two policies, an alternating training stage is added to learn pushing and grasping in turn. A series of experiments carried out in simulation and real world indicate that our method can quickly learn effective pushing and grasping policies and outperforms existing methods in task completion rate and goal grasp success rate by less times of motion. Furthermore, we validate that our system can also adapt to goal-agnostic conditions with better performance. Note that our system can be transferred to the real world without any fine-tuning. Our code is available at https://github.com/xukechun/Efficient goal-oriented push-grasping synergy