 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fill the Seam by Vision: Sub-millimeter Peg-in-hole on Unseen Shapes in Real World
Paper and Code
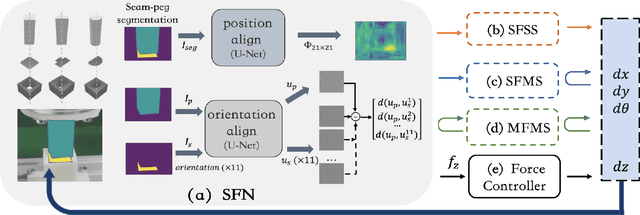
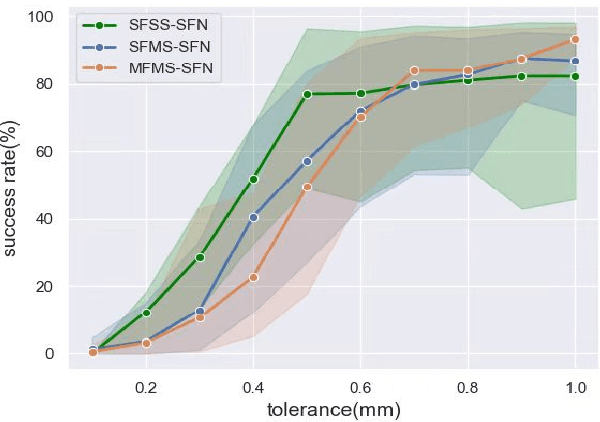
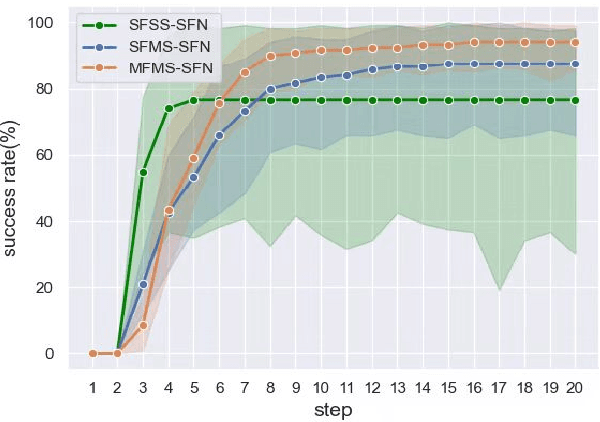

In the peg insertion task, human pays attention to the seam between the peg and the hole and tries to fill it continuously with visual feedback. By imitating the human behavior, we design architectures with position and orientation estimators based on the seam representation for pose alignment, which proves to be general to the unseen peg geometries. By putting the estimators into the closed-loop control with reinforcement learning, we further achieve a higher or comparable success rate, efficiency, and robustness compared with the baseline methods. The policy is trained totally in simulation without any manual intervention. To achieve sim-to-real, a learnable segmentation module with automatic data collecting and labeling can be easily trained to decouple the perception and the policy, which helps the model trained in simulation quickly adapt to the real world with negligible effort. Results are presented in simulation and on a physical robot. Code, videos, and supplemental material are available at https://github.com/xieliang555/SFN.git