 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDust to Tower: Coarse-to-Fine Photo-Realistic Scene Reconstruction from Sparse Uncalibrated Images
Dec 27, 2024



Photo-realistic scene reconstruction from sparse-view, uncalibrated images is highly required in practice. Although some successes have been made, existing methods are either Sparse-View but require accurate camera parameters (i.e., intrinsic and extrinsic), or SfM-free but need densely captured images. To combine the advantages of both methods while addressing their respective weaknesses, we propose Dust to Tower (D2T), an accurate and efficient coarse-to-fine framework to optimize 3DGS and image poses simultaneously from sparse and uncalibrated images. Our key idea is to first construct a coarse model efficiently and subsequently refine it using warped and inpainted images at novel viewpoints. To do this, we first introduce a Coarse Construction Module (CCM) which exploits a fast Multi-View Stereo model to initialize a 3D Gaussian Splatting (3DGS) and recover initial camera poses. To refine the 3D model at novel viewpoints, we propose a Confidence Aware Depth Alignment (CADA) module to refine the coarse depth maps by aligning their confident parts with estimated depths by a Mono-depth model. Then, a Warped Image-Guided Inpainting (WIGI) module is proposed to warp the training images to novel viewpoints by the refined depth maps, and inpainting is applied to fulfill the ``holes" in the warped images caused by view-direction changes, providing high-quality supervision to further optimize the 3D model and the camera poses. Extensive experiments and ablation studies demonstrate the validity of D2T and its design choices, achieving state-of-the-art performance in both tasks of novel view synthesis and pose estimation while keeping high efficiency. Codes will be publicly available.
PRISM: PRogressive dependency maxImization for Scale-invariant image Matching
Aug 07, 2024

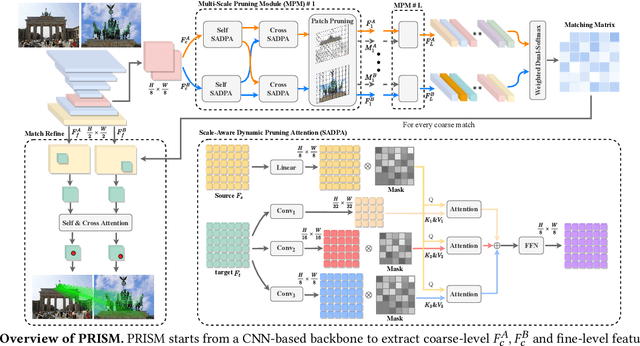

Image matching aims at identifying corresponding points between a pair of images. Currently, detector-free methods have shown impressive performance in challenging scenarios, thanks to their capability of generating dense matches and global receptive field. However, performing feature interaction and proposing matches across the entire image is unnecessary, because not all image regions contribute to the matching process. Interacting and matching in unmatchable areas can introduce errors, reducing matching accuracy and efficiency. Meanwhile, the scale discrepancy issue still troubles existing methods. To address above issues, we propose PRogressive dependency maxImization for Scale-invariant image Matching (PRISM), which jointly prunes irrelevant patch features and tackles the scale discrepancy. To do this, we firstly present a Multi-scale Pruning Module (MPM) to adaptively prune irrelevant features by maximizing the dependency between the two feature sets. Moreover, we design the Scale-Aware Dynamic Pruning Attention (SADPA) to aggregate information from different scales via a hierarchical design. Our method's superior matching performance and generalization capability are confirmed by leading accuracy across various evaluation benchmarks and downstream tasks. The code is publicly available at https://github.com/Master-cai/PRISM.
ModaLink: Unifying Modalities for Efficient Image-to-PointCloud Place Recognition
Mar 27, 2024



Place recognition is an important task for robots and autonomous cars to localize themselves and close loops in pre-built maps. While single-modal sensor-based methods have shown satisfactory performance, cross-modal place recognition that retrieving images from a point-cloud database remains a challenging problem. Current cross-modal methods transform images into 3D points using depth estimation for modality conversion, which are usually computationally intensive and need expensive labeled data for depth supervision. In this work, we introduce a fast and lightweight framework to encode images and point clouds into place-distinctive descriptors. We propose an effective Field of View (FoV) transformation module to convert point clouds into an analogous modality as images. This module eliminates the necessity for depth estimation and helps subsequent modules achieve real-time performance. We further design a non-negative factorization-based encoder to extract mutually consistent semantic features between point clouds and images. This encoder yields more distinctive global descriptors for retrieval. Experimental results on the KITTI dataset show that our proposed methods achieve state-of-the-art performance while running in real time. Additional evaluation on the HAOMO dataset covering a 17 km trajectory further shows the practical generalization capabilities. We have released the implementation of our methods as open source at: https://github.com/haomo-ai/ModaLink.git.
Learning A Simulation-based Visual Policy for Real-world Peg In Unseen Holes
May 09, 2022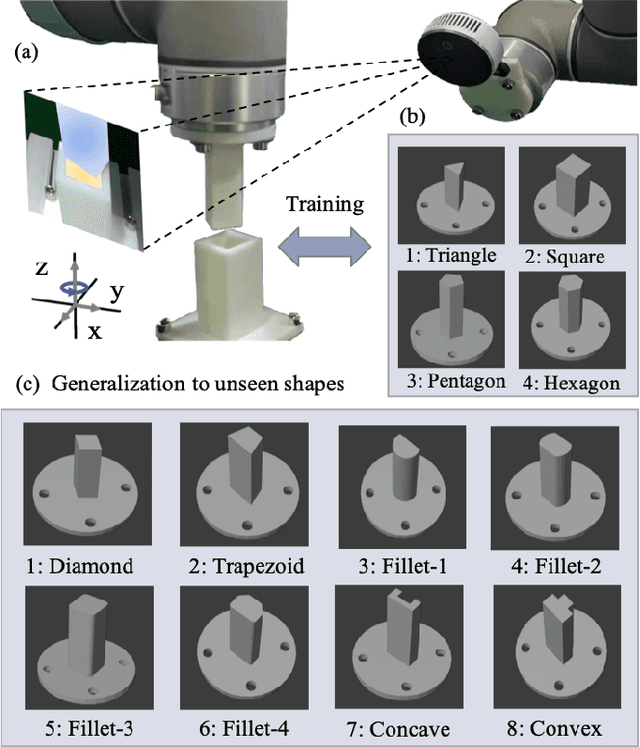

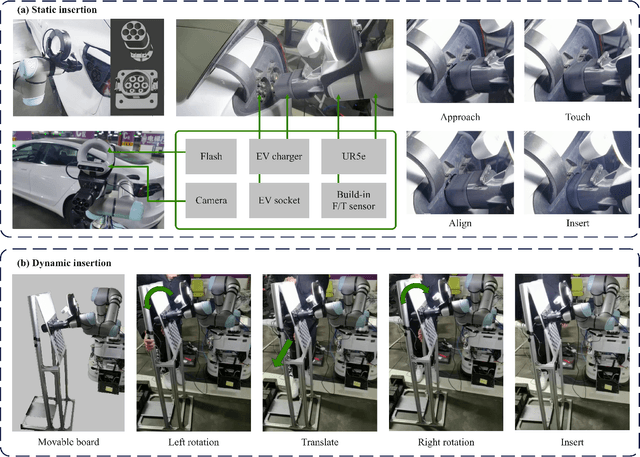
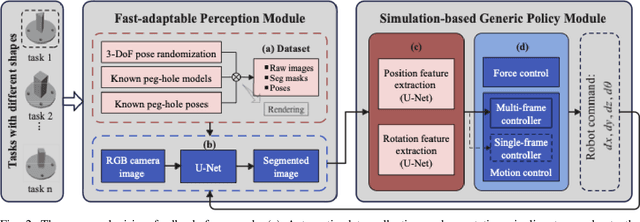
This paper proposes a learning-based visual peg-in-hole that enables training with several shapes in simulation, and adapting to arbitrary unseen shapes in real world with minimal sim-to-real cost. The core idea is to decouple the generalization of the sensory-motor policy to the design of a fast-adaptable perception module and a simulated generic policy module. The framework consists of a segmentation network (SN), a virtual sensor network (VSN), and a controller network (CN). Concretely, the VSN is trained to measure the pose of the unseen shape from a segmented image. After that, given the shape-agnostic pose measurement, the CN is trained to achieve generic peg-in-hole. Finally, when applying to real unseen holes, we only have to fine-tune the SN required by the simulated VSN+CN. To further minimize the transfer cost, we propose to automatically collect and annotate the data for the SN after one-minute human teaching. Simulated and real-world results are presented under the configurations of eye-to/in-hand. An electric vehicle charging system with the proposed policy inside achieves a 10/10 success rate in 2-3s, using only hundreds of auto-labeled samples for the SN transfer.
Learning to Fill the Seam by Vision: Sub-millimeter Peg-in-hole on Unseen Shapes in Real World
Apr 20, 2022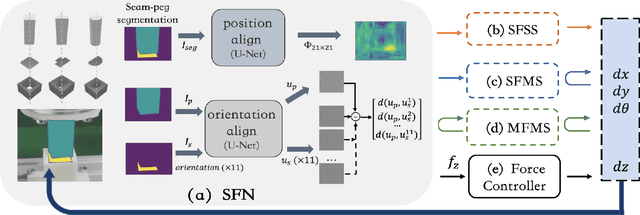
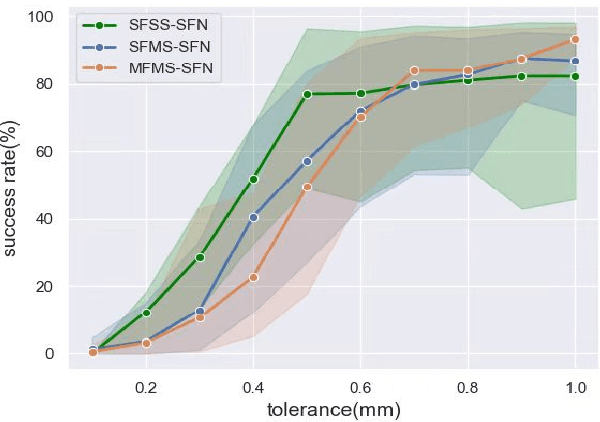
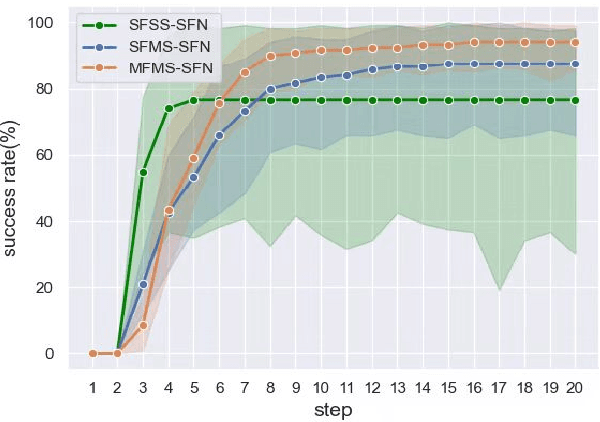

In the peg insertion task, human pays attention to the seam between the peg and the hole and tries to fill it continuously with visual feedback. By imitating the human behavior, we design architectures with position and orientation estimators based on the seam representation for pose alignment, which proves to be general to the unseen peg geometries. By putting the estimators into the closed-loop control with reinforcement learning, we further achieve a higher or comparable success rate, efficiency, and robustness compared with the baseline methods. The policy is trained totally in simulation without any manual intervention. To achieve sim-to-real, a learnable segmentation module with automatic data collecting and labeling can be easily trained to decouple the perception and the policy, which helps the model trained in simulation quickly adapt to the real world with negligible effort. Results are presented in simulation and on a physical robot. Code, videos, and supplemental material are available at https://github.com/xieliang555/SFN.git
Robust localization for planar moving robot in changing environment: A perspective on density of correspondence and depth
Nov 01, 2020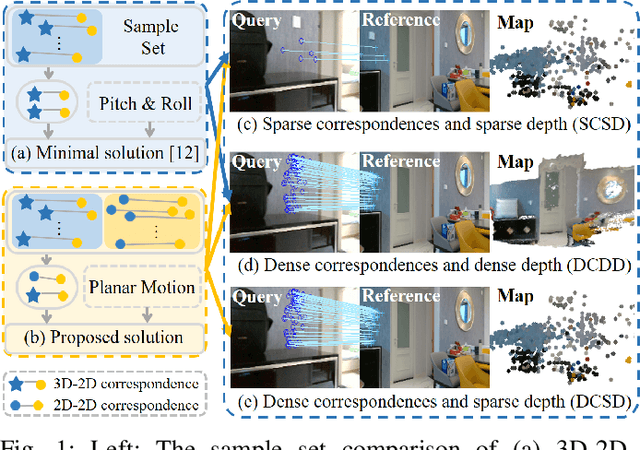
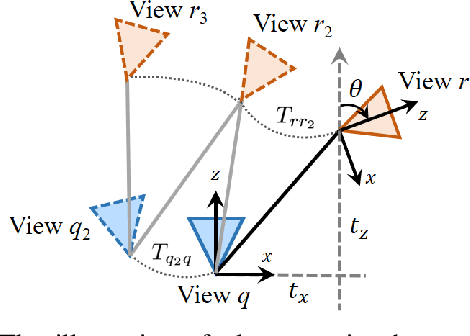
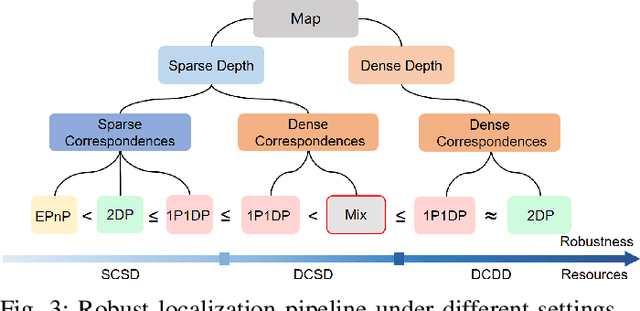
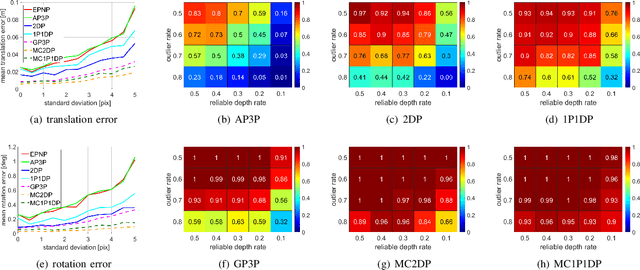
Visual localization for planar moving robot is important to various indoor service robotic applications. To handle the textureless areas and frequent human activities in indoor environments, a novel robust visual localization algorithm which leverages dense correspondence and sparse depth for planar moving robot is proposed. The key component is a minimal solution which computes the absolute camera pose with one 3D-2D correspondence and one 2D-2D correspondence. The advantages are obvious in two aspects. First, the robustness is enhanced as the sample set for pose estimation is maximal by utilizing all correspondences with or without depth. Second, no extra effort for dense map construction is required to exploit dense correspondences for handling textureless and repetitive texture scenes. That is meaningful as building a dense map is computational expensive especially in large scale. Moreover, a probabilistic analysis among different solutions is presented and an automatic solution selection mechanism is designed to maximize the success rate by selecting appropriate solutions in different environmental characteristics. Finally, a complete visual localization pipeline considering situations from the perspective of correspondence and depth density is summarized and validated on both simulation and public real-world indoor localization dataset. The code is released on github.