 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Two-view 6D Object Pose Estimation: A Comparative Study on Fusion Strategy
Jul 01, 2022



Current RGB-based 6D object pose estimation methods have achieved noticeable performance on datasets and real world applications. However, predicting 6D pose from single 2D image features is susceptible to disturbance from changing of environment and textureless or resemblant object surfaces. Hence, RGB-based methods generally achieve less competitive results than RGBD-based methods, which deploy both image features and 3D structure features. To narrow down this performance gap, this paper proposes a framework for 6D object pose estimation that learns implicit 3D information from 2 RGB images. Combining the learned 3D information and 2D image features, we establish more stable correspondence between the scene and the object models. To seek for the methods best utilizing 3D information from RGB inputs, we conduct an investigation on three different approaches, including Early- Fusion, Mid-Fusion, and Late-Fusion. We ascertain the Mid- Fusion approach is the best approach to restore the most precise 3D keypoints useful for object pose estimation. The experiments show that our method outperforms state-of-the-art RGB-based methods, and achieves comparable results with RGBD-based methods.
Learning Stereopsis from Geometric Synthesis for 6D Object Pose Estimation
Sep 25, 2021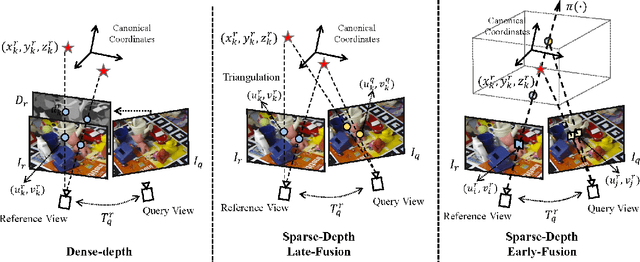
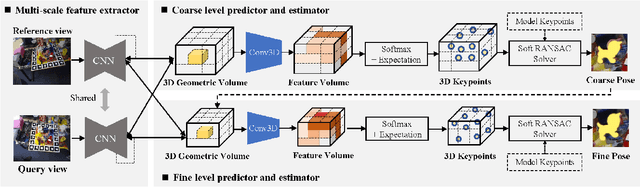
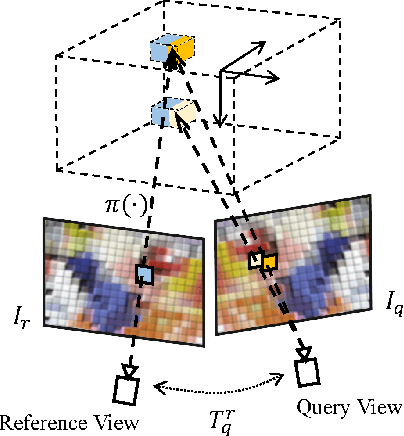
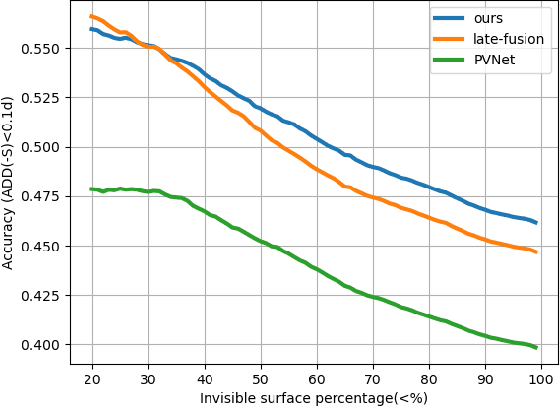
Current monocular-based 6D object pose estimation methods generally achieve less competitive results than RGBD-based methods, mostly due to the lack of 3D information. To make up this gap, this paper proposes a 3D geometric volume based pose estimation method with a short baseline two-view setting. By constructing a geometric volume in the 3D space, we combine the features from two adjacent images to the same 3D space. Then a network is trained to learn the distribution of the position of object keypoints in the volume, and a robust soft RANSAC solver is deployed to solve the pose in closed form. To balance accuracy and cost, we propose a coarse-to-fine framework to improve the performance in an iterative way. The experiments show that our method outperforms state-of-the-art monocular-based methods, and is robust in different objects and scenes, especially in serious occlusion situations.
Robust localization for planar moving robot in changing environment: A perspective on density of correspondence and depth
Nov 01, 2020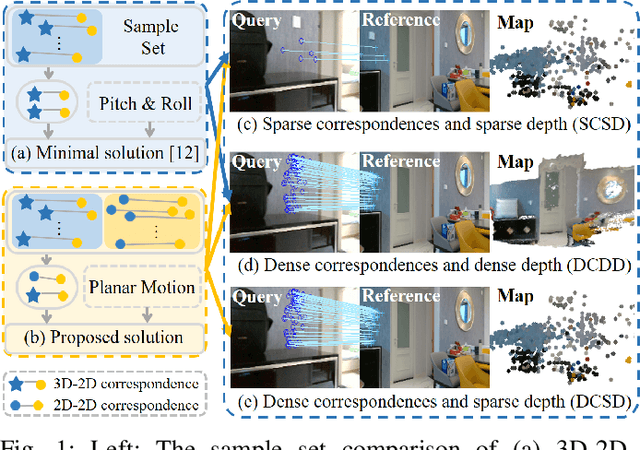
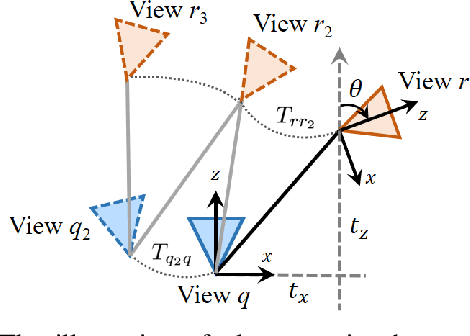
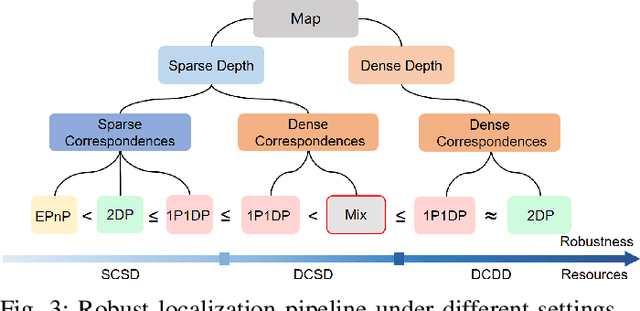
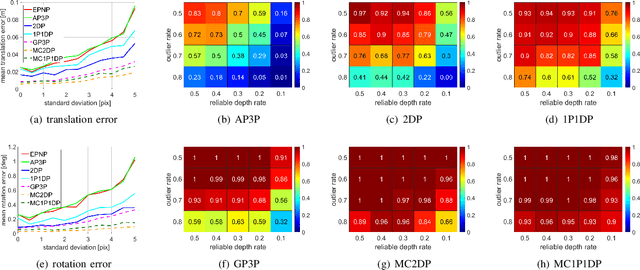
Visual localization for planar moving robot is important to various indoor service robotic applications. To handle the textureless areas and frequent human activities in indoor environments, a novel robust visual localization algorithm which leverages dense correspondence and sparse depth for planar moving robot is proposed. The key component is a minimal solution which computes the absolute camera pose with one 3D-2D correspondence and one 2D-2D correspondence. The advantages are obvious in two aspects. First, the robustness is enhanced as the sample set for pose estimation is maximal by utilizing all correspondences with or without depth. Second, no extra effort for dense map construction is required to exploit dense correspondences for handling textureless and repetitive texture scenes. That is meaningful as building a dense map is computational expensive especially in large scale. Moreover, a probabilistic analysis among different solutions is presented and an automatic solution selection mechanism is designed to maximize the success rate by selecting appropriate solutions in different environmental characteristics. Finally, a complete visual localization pipeline considering situations from the perspective of correspondence and depth density is summarized and validated on both simulation and public real-world indoor localization dataset. The code is released on github.