 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stereopsis from Geometric Synthesis for 6D Object Pose Estimation
Paper and Code
Sep 25, 2021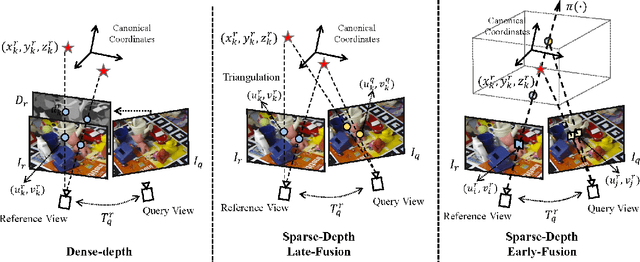
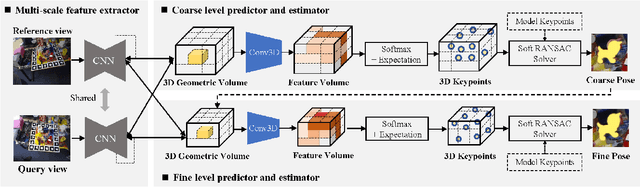
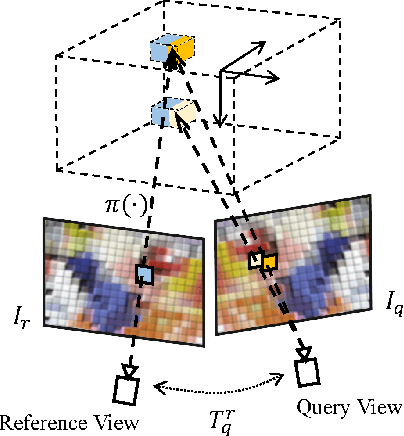
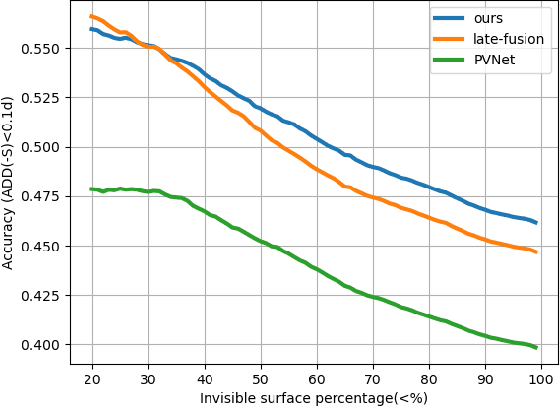
Current monocular-based 6D object pose estimation methods generally achieve less competitive results than RGBD-based methods, mostly due to the lack of 3D information. To make up this gap, this paper proposes a 3D geometric volume based pose estimation method with a short baseline two-view setting. By constructing a geometric volume in the 3D space, we combine the features from two adjacent images to the same 3D space. Then a network is trained to learn the distribution of the position of object keypoints in the volume, and a robust soft RANSAC solver is deployed to solve the pose in closed form. To balance accuracy and cost, we propose a coarse-to-fine framework to improve the performance in an iterative way. The experiments show that our method outperforms state-of-the-art monocular-based methods, and is robust in different objects and scenes, especially in serious occlusion situations.