 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-cam Multi-map Visual Inertial Localization: System, Validation and Dataset
Dec 05, 2024



Map-based localization is crucial for the autonomous movement of robots as it provides real-time positional feedback. However, existing VINS and SLAM systems cannot be directly integrated into the robot's control loop. Although VINS offers high-frequency position estimates, it suffers from drift in long-term operation. And the drift-free trajectory output by SLAM is post-processed with loop correction, which is non-causal. In practical control, it is impossible to update the current pose with future information. Furthermore, existing SLAM evaluation systems measure accuracy after aligning the entire trajectory, which overlooks the transformation error between the odometry start frame and the ground truth frame. To address these issues, we propose a multi-cam multi-map visual inertial localization system, which provides real-time, causal and drift-free position feedback to the robot control loop. Additionally, we analyze the error composition of map-based localization systems and propose a set of evaluation metric suitable for measuring causal localization performance. To validate our system, we design a multi-camera IMU hardware setup and collect a long-term challenging campus dataset. Experimental results demonstrate the higher real-time localization accuracy of the proposed system. To foster community development, both the system and the dataset have been made open source https://github.com/zoeylove/Multi-cam-Multi-map-VILO/tree/main.
3D Model-free Visual Localization System from Essential Matrix under Local Planar Motion
Sep 04, 2023Visual localization plays a critical role in the functionality of low-cost autonomous mobile robots. Current state-of-the-art approaches for achieving accurate visual localization are 3D scene-specific, requiring additional computational and storage resources to construct a 3D scene model when facing a new environment. An alternative approach of directly using a database of 2D images for visual localization offers more flexibility. However, such methods currently suffer from limited localization accuracy. In this paper, we propose an accurate and robust multiple checking-based 3D model-free visual localization system to address the aforementioned issues. To ensure high accuracy, our focus is on estimating the pose of a query image relative to the retrieved database images using 2D-2D feature matches. Theoretically, by incorporating the local planar motion constraint into both the estimation of the essential matrix and the triangulation stages, we reduce the minimum required feature matches for absolute pose estimation, thereby enhancing the robustness of outlier rejection. Additionally, we introduce a multiple-checking mechanism to ensure the correctness of the solution throughout the solving process. For validation, qualitative and quantitative experiments are performed on both simulation and two real-world datasets and the experimental results demonstrate a significant enhancement in both accuracy and robustness afforded by the proposed 3D model-free visual localization system.
Leveraging BEV Representation for 360-degree Visual Place Recognition
May 23, 2023



This paper investigates the advantages of using Bird's Eye View (BEV) representation in 360-degree visual place recognition (VPR). We propose a novel network architecture that utilizes the BEV representation in feature extraction, feature aggregation, and vision-LiDAR fusion, which bridges visual cues and spatial awareness. Our method extracts image features using standard convolutional networks and combines the features according to pre-defined 3D grid spatial points. To alleviate the mechanical and time misalignments between cameras, we further introduce deformable attention to learn the compensation. Upon the BEV feature representation, we then employ the polar transform and the Discrete Fourier transform for aggregation, which is shown to be rotation-invariant. In addition, the image and point cloud cues can be easily stated in the same coordinates, which benefits sensor fusion for place recognition. The proposed BEV-based method is evaluated in ablation and comparative studies on two datasets, including on-the-road and off-the-road scenarios. The experimental results verify the hypothesis that BEV can benefit VPR by its superior performance compared to baseline methods. To the best of our knowledge, this is the first trial of employing BEV representation in this task.
GOOD: General Optimization-based Fusion for 3D Object Detection via LiDAR-Camera Object Candidates
Mar 17, 2023



3D object detection serves as the core basis of the perception tasks in autonomous driving. Recent years have seen the rapid progress of multi-modal fusion strategies for more robust and accurate 3D object detection. However, current researches for robust fusion are all learning-based frameworks, which demand a large amount of training data and are inconvenient to implement in new scenes. In this paper, we propose GOOD, a general optimization-based fusion framework that can achieve satisfying detection without training additional models and is available for any combinations of 2D and 3D detectors to improve the accuracy and robustness of 3D detection. First we apply the mutual-sided nearest-neighbor probability model to achieve the 3D-2D data association. Then we design an optimization pipeline that can optimize different kinds of instances separately based on the matching result. Apart from this, the 3D MOT method is also introduced to enhance the performance aided by previous frames. To the best of our knowledge, this is the first optimization-based late fusion framework for multi-modal 3D object detection which can be served as a baseline for subsequent research. Experiments on both nuScenes and KITTI datasets are carried out and the results show that GOOD outperforms by 9.1\% on mAP score compared with PointPillars and achieves competitive results with the learning-based late fusion CLOCs.
DAMS-LIO: A Degeneration-Aware and Modular Sensor-Fusion LiDAR-inertial Odometry
Feb 08, 2023



The fusion scheme is crucial to the multi-sensor fusion method that is the promising solution to the state estimation in complex and extreme environments like underground mines and planetary surfaces. In this work, a light-weight iEKF-based LiDAR-inertial odometry system is presented, which utilizes a degeneration-aware and modular sensor-fusion pipeline that takes both LiDAR points and relative pose from another odometry as the measurement in the update process only when degeneration is detected. Both the CRLB theory and simulation test are used to demonstrate the higher accuracy of our method compared to methods using a single observation. Furthermore, the proposed system is evaluated in perceptually challenging datasets against various state-of-the-art sensor-fusion methods. The results show that the proposed system achieves real-time and high estimation accuracy performance despite the challenging environment and poor observations.
FEJ-VIRO: A Consistent First-Estimate Jacobian Visual-Inertial-Ranging Odometry
Jul 17, 2022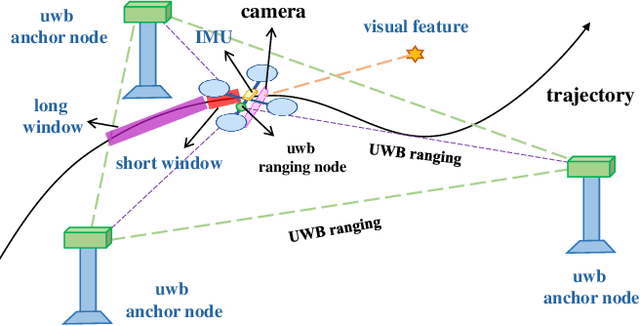
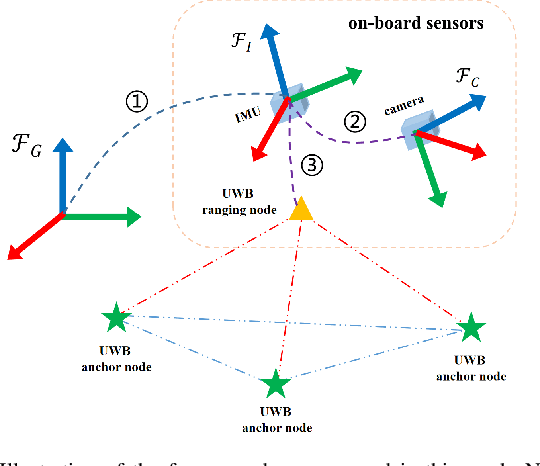
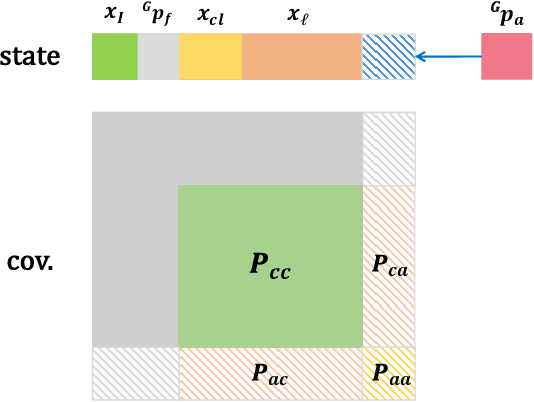

In recent years, Visual-Inertial Odometry (VIO) has achieved many significant progresses. However, VIO methods suffer from localization drift over long trajectories. In this paper, we propose a First-Estimates Jacobian Visual-Inertial-Ranging Odometry (FEJ-VIRO) to reduce the localization drifts of VIO by incorporating ultra-wideband (UWB) ranging measurements into the VIO framework \textit{consistently}. Considering that the initial positions of UWB anchors are usually unavailable, we propose a long-short window structure to initialize the UWB anchors' positions as well as the covariance for state augmentation. After initialization, the FEJ-VIRO estimates the UWB anchors' positions simultaneously along with the robot poses. We further analyze the observability of the visual-inertial-ranging estimators and proved that there are \textit{four} unobservable directions in the ideal case, while one of them vanishes in the actual case due to the gain of spurious information. Based on these analyses, we leverage the FEJ technique to enforce the unobservable directions, hence reducing inconsistency of the estimator. Finally, we validate our analysis and evaluate the proposed FEJ-VIRO with both simulation and real-world experiments.
Map-based Visual-Inertial Localization: Consistency and Complexity
Apr 26, 2022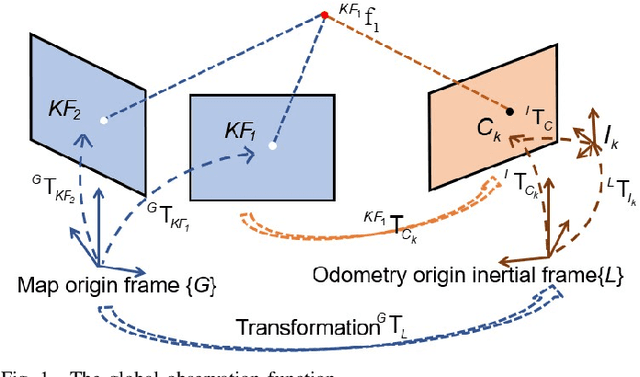
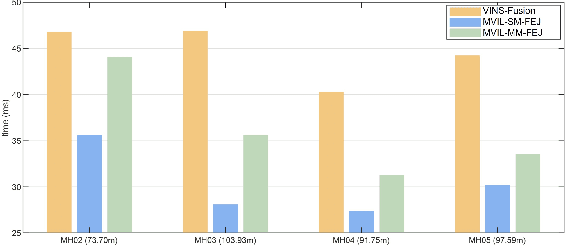
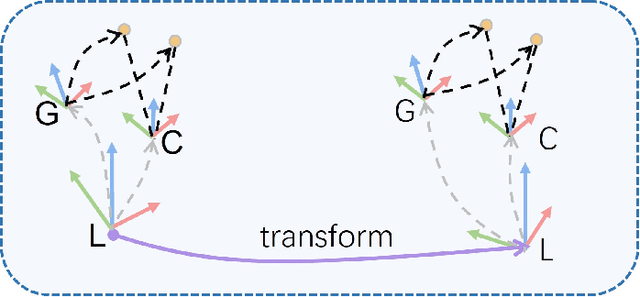
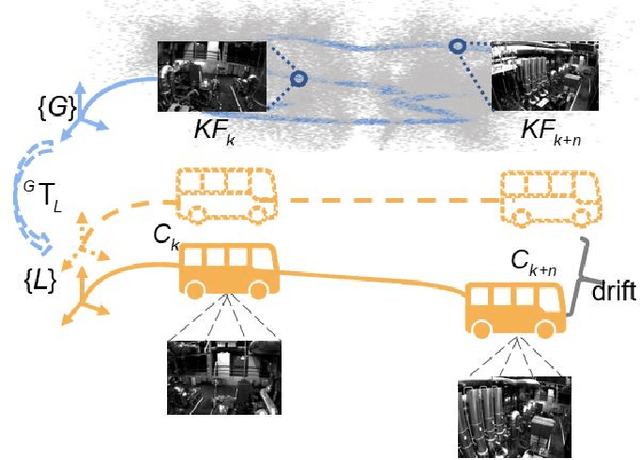
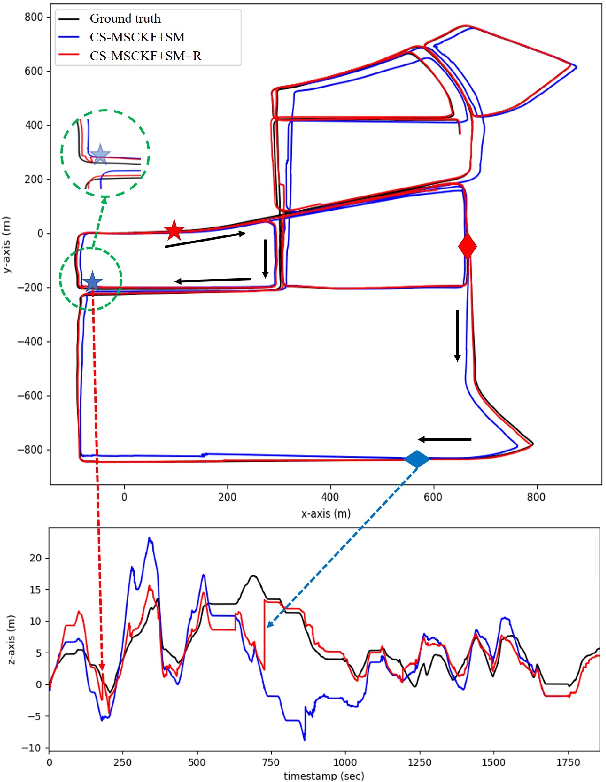
Drift-free localization is essential for autonomous vehicles. In this paper, we address the problem by proposing a filter-based framework, which integrates the visual-inertial odometry and the measurements of the features in the pre-built map. In this framework, the transformation between the odometry frame and the map frame is augmented into the state and estimated on the fly. Besides, we maintain only the keyframe poses in the map and employ Schmidt extended Kalman filter to update the state partially, so that the uncertainty of the map information can be consistently considered with low computational cost. Moreover, we theoretically demonstrate that the ever-changing linearization points of the estimated state can introduce spurious information to the augmented system and make the original four-dimensional unobservable subspace vanish, leading to inconsistent estimation in practice. To relieve this problem, we employ first-estimate Jacobian (FEJ) to maintain the correct observability properties of the augmented system. Furthermore, we introduce an observability-constrained updating method to compensate for the significant accumulated error after the long-term absence (can be 3 minutes and 1 km) of map-based measurements. Through simulations, the consistent estimation of our proposed algorithm is validated. Through real-world experiments, we demonstrate that our proposed algorithm runs successfully on four kinds of datasets with the lower computational cost (20% time-saving) and the better estimation accuracy (45% trajectory error reduction) compared with the baseline algorithm VINS-Fusion, whereas VINS-Fusion fails to give bounded localization performance on three of four datasets because of its inconsistent estimation.
Translation Invariant Global Estimation of Heading Angle Using Sinogram of LiDAR Point Cloud
Mar 02, 2022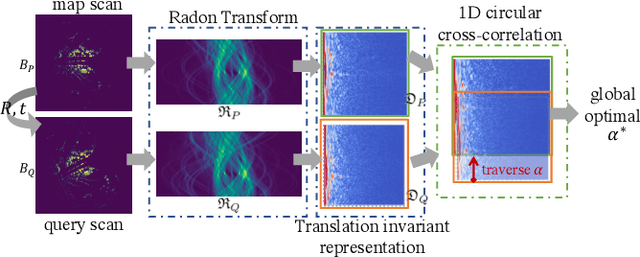
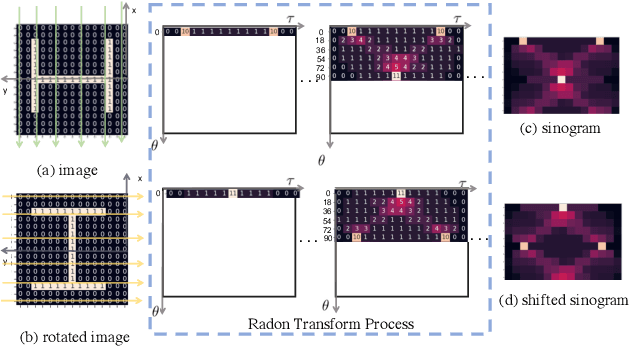
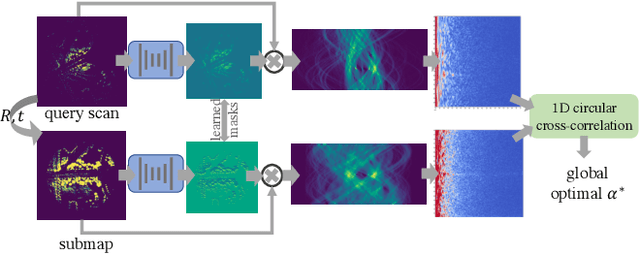
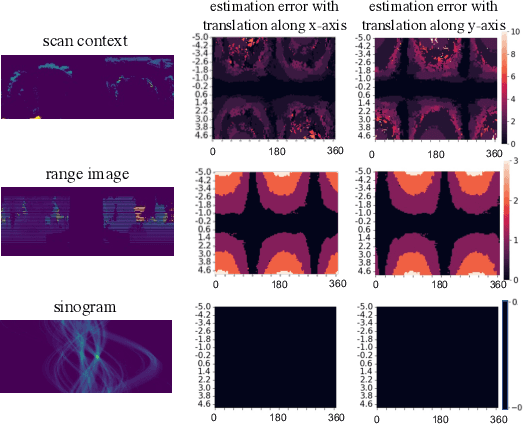
Global point cloud registration is an essential module for localization, of which the main difficulty exists in estimating the rotation globally without initial value. With the aid of gravity alignment, the degree of freedom in point cloud registration could be reduced to 4DoF, in which only the heading angle is required for rotation estimation. In this paper, we propose a fast and accurate global heading angle estimation method for gravity-aligned point clouds. Our key idea is that we generate a translation invariant representation based on Radon Transform, allowing us to solve the decoupled heading angle globally with circular cross-correlation. Besides, for heading angle estimation between point clouds with different distributions, we implement this heading angle estimator as a differentiable module to train a feature extraction network end- to-end. The experimental results validate the effectiveness of the proposed method in heading angle estimation and show better performance compared with other methods.
Toward Consistent Drift-free Visual Inertial Localization on Keyframe Based Map
Mar 21, 2021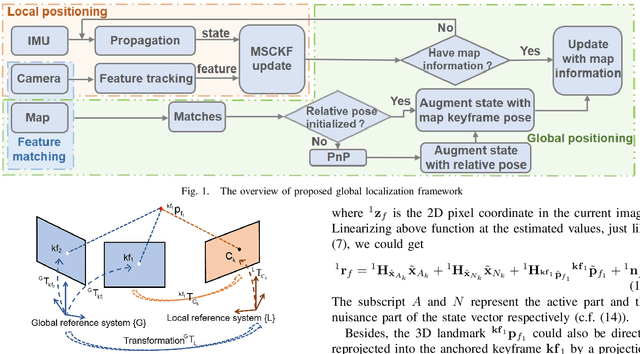

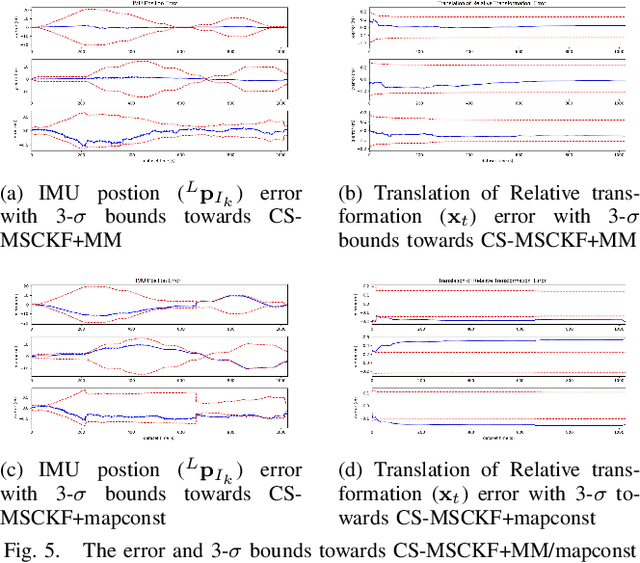
Global localization is essential for robots to perform further tasks like navigation. In this paper, we propose a new framework to perform global localization based on a filter-based visual-inertial odometry framework MSCKF. To reduce the computation and memory consumption, we only maintain the keyframe poses of the map and employ Schmidt-EKF to update the state. This global localization framework is shown to be able to maintain the consistency of the state estimator. Furthermore, we introduce a re-linearization mechanism during the updating phase. This mechanism could ease the linearization error of observation function to make the state estimation more precise. The experiments show that this mechanism is crucial for large and challenging scenes. Simulations and experiments demonstrate the effectiveness and consistency of our global localization framework.
Robust localization for planar moving robot in changing environment: A perspective on density of correspondence and depth
Nov 01, 2020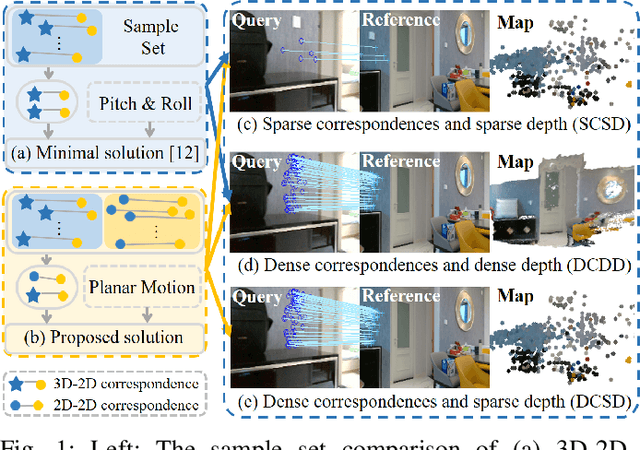
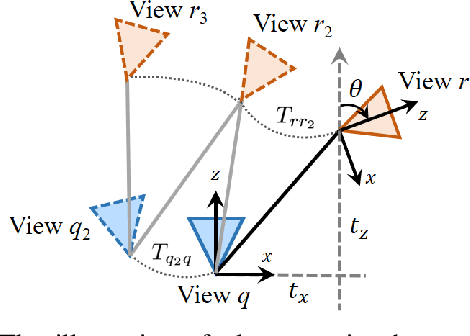
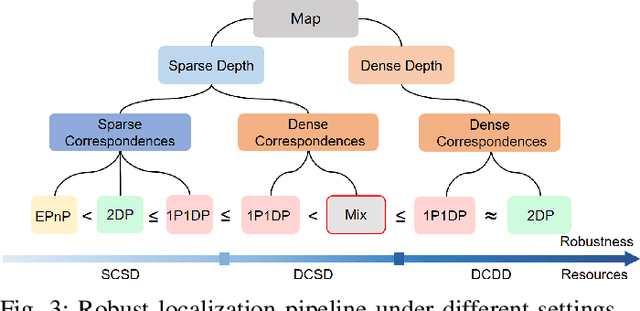
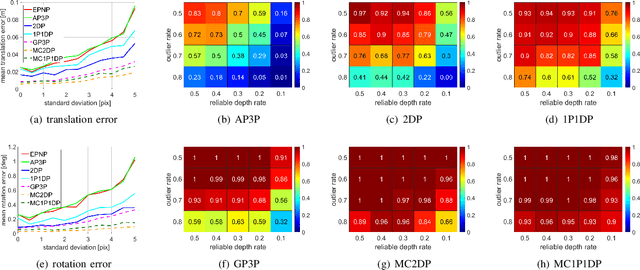
Visual localization for planar moving robot is important to various indoor service robotic applications. To handle the textureless areas and frequent human activities in indoor environments, a novel robust visual localization algorithm which leverages dense correspondence and sparse depth for planar moving robot is proposed. The key component is a minimal solution which computes the absolute camera pose with one 3D-2D correspondence and one 2D-2D correspondence. The advantages are obvious in two aspects. First, the robustness is enhanced as the sample set for pose estimation is maximal by utilizing all correspondences with or without depth. Second, no extra effort for dense map construction is required to exploit dense correspondences for handling textureless and repetitive texture scenes. That is meaningful as building a dense map is computational expensive especially in large scale. Moreover, a probabilistic analysis among different solutions is presented and an automatic solution selection mechanism is designed to maximize the success rate by selecting appropriate solutions in different environmental characteristics. Finally, a complete visual localization pipeline considering situations from the perspective of correspondence and depth density is summarized and validated on both simulation and public real-world indoor localization dataset. The code is released on github.