 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEV-ODOM2: Enhanced BEV-based Monocular Visual Odometry with PV-BEV Fusion and Dense Flow Supervision for Ground Robots
Sep 18, 2025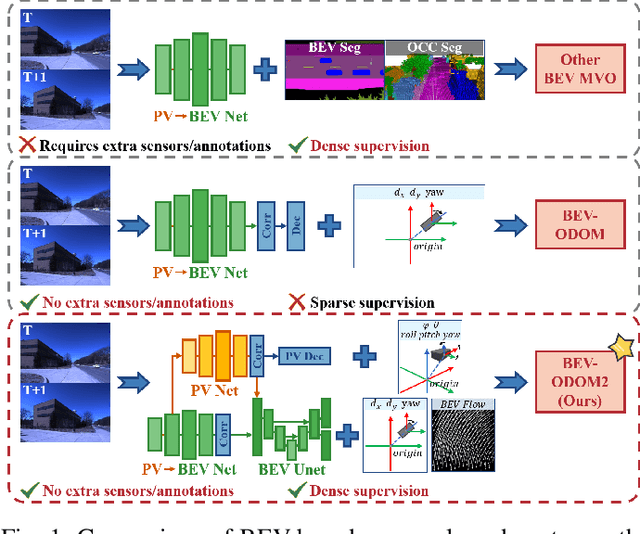
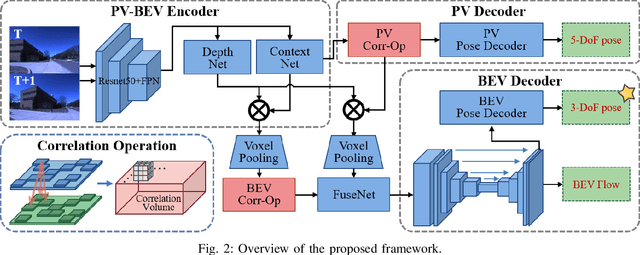
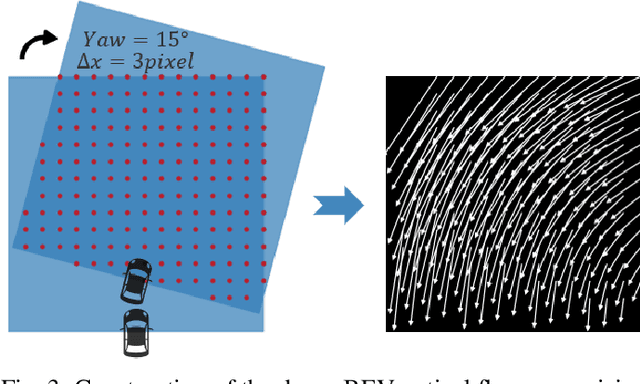
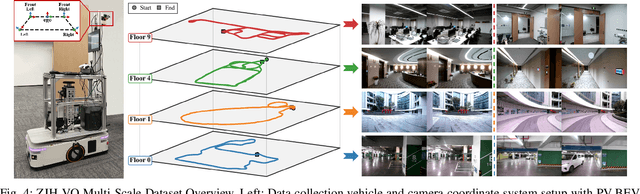
Bird's-Eye-View (BEV) representation offers a metric-scaled planar workspace, facilitating the simplification of 6-DoF ego-motion to a more robust 3-DoF model for monocular visual odometry (MVO) in intelligent transportation systems. However, existing BEV methods suffer from sparse supervision signals and information loss during perspective-to-BEV projection. We present BEV-ODOM2, an enhanced framework addressing both limitations without additional annotations. Our approach introduces: (1) dense BEV optical flow supervision constructed from 3-DoF pose ground truth for pixel-level guidance; (2) PV-BEV fusion that computes correlation volumes before projection to preserve 6-DoF motion cues while maintaining scale consistency. The framework employs three supervision levels derived solely from pose data: dense BEV flow, 5-DoF for the PV branch, and final 3-DoF output. Enhanced rotation sampling further balances diverse motion patterns in training. Extensive evaluation on KITTI, NCLT, Oxford, and our newly collected ZJH-VO multi-scale dataset demonstrates state-of-the-art performance, achieving 40 improvement in RTE compared to previous BEV methods. The ZJH-VO dataset, covering diverse ground vehicle scenarios from underground parking to outdoor plazas, is publicly available to facilitate future research.
Multi-cam Multi-map Visual Inertial Localization: System, Validation and Dataset
Dec 05, 2024



Map-based localization is crucial for the autonomous movement of robots as it provides real-time positional feedback. However, existing VINS and SLAM systems cannot be directly integrated into the robot's control loop. Although VINS offers high-frequency position estimates, it suffers from drift in long-term operation. And the drift-free trajectory output by SLAM is post-processed with loop correction, which is non-causal. In practical control, it is impossible to update the current pose with future information. Furthermore, existing SLAM evaluation systems measure accuracy after aligning the entire trajectory, which overlooks the transformation error between the odometry start frame and the ground truth frame. To address these issues, we propose a multi-cam multi-map visual inertial localization system, which provides real-time, causal and drift-free position feedback to the robot control loop. Additionally, we analyze the error composition of map-based localization systems and propose a set of evaluation metric suitable for measuring causal localization performance. To validate our system, we design a multi-camera IMU hardware setup and collect a long-term challenging campus dataset. Experimental results demonstrate the higher real-time localization accuracy of the proposed system. To foster community development, both the system and the dataset have been made open source https://github.com/zoeylove/Multi-cam-Multi-map-VILO/tree/main.
BEV-ODOM: Reducing Scale Drift in Monocular Visual Odometry with BEV Representation
Nov 15, 2024



Monocular visual odometry (MVO) is vital in autonomous navigation and robotics, providing a cost-effective and flexible motion tracking solution, but the inherent scale ambiguity in monocular setups often leads to cumulative errors over time. In this paper, we present BEV-ODOM, a novel MVO framework leveraging the Bird's Eye View (BEV) Representation to address scale drift. Unlike existing approaches, BEV-ODOM integrates a depth-based perspective-view (PV) to BEV encoder, a correlation feature extraction neck, and a CNN-MLP-based decoder, enabling it to estimate motion across three degrees of freedom without the need for depth supervision or complex optimization techniques. Our framework reduces scale drift in long-term sequences and achieves accurate motion estimation across various datasets, including NCLT, Oxford, and KITTI. The results indicate that BEV-ODOM outperforms current MVO methods, demonstrating reduced scale drift and higher accuracy.
EMV-LIO: An Efficient Multiple Vision aided LiDAR-Inertial Odometry
Feb 15, 2023To deal with the degeneration caused by the incomplete constraints of single sensor, multi-sensor fusion strategies especially in LiDAR-vision-inertial fusion area have attracted much interest from both the industry and the research community in recent years. Considering that a monocular camera is vulnerable to the influence of ambient light from a certain direction and fails, which makes the system degrade into a LiDAR-inertial system, multiple cameras are introduced to expand the visual observation so as to improve the accuracy and robustness of the system. Besides, removing LiDAR's noise via range image, setting condition for nearest neighbor search, and replacing kd-Tree with ikd-Tree are also introduced to enhance the efficiency. Based on the above, we propose an Efficient Multiple vision aided LiDAR-inertial odometry system (EMV-LIO), and evaluate its performance on both open datasets and our custom datasets. Experiments show that the algorithm is helpful to improve the accuracy, robustness and efficiency of the whole system compared with LVI-SAM. Our implementation will be available upon acceptance.
DAMS-LIO: A Degeneration-Aware and Modular Sensor-Fusion LiDAR-inertial Odometry
Feb 08, 2023



The fusion scheme is crucial to the multi-sensor fusion method that is the promising solution to the state estimation in complex and extreme environments like underground mines and planetary surfaces. In this work, a light-weight iEKF-based LiDAR-inertial odometry system is presented, which utilizes a degeneration-aware and modular sensor-fusion pipeline that takes both LiDAR points and relative pose from another odometry as the measurement in the update process only when degeneration is detected. Both the CRLB theory and simulation test are used to demonstrate the higher accuracy of our method compared to methods using a single observation. Furthermore, the proposed system is evaluated in perceptually challenging datasets against various state-of-the-art sensor-fusion methods. The results show that the proposed system achieves real-time and high estimation accuracy performance despite the challenging environment and poor observations.