 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRING#: PR-by-PE Global Localization with Roto-translation Equivariant Gram Learning
Aug 30, 2024



Global localization using onboard perception sensors, such as cameras and LiDARs, is crucial in autonomous driving and robotics applications when GPS signals are unreliable. Most approaches achieve global localization by sequential place recognition and pose estimation. Some of them train separate models for each task, while others employ a single model with dual heads, trained jointly with separate task-specific losses. However, the accuracy of localization heavily depends on the success of place recognition, which often fails in scenarios with significant changes in viewpoint or environmental appearance. Consequently, this renders the final pose estimation of localization ineffective. To address this, we propose a novel paradigm, PR-by-PE localization, which improves global localization accuracy by deriving place recognition directly from pose estimation. Our framework, RING#, is an end-to-end PR-by-PE localization network operating in the bird's-eye view (BEV) space, designed to support both vision and LiDAR sensors. It introduces a theoretical foundation for learning two equivariant representations from BEV features, which enables globally convergent and computationally efficient pose estimation. Comprehensive experiments on the NCLT and Oxford datasets across both vision and LiDAR modalities demonstrate that our method outperforms state-of-the-art approaches. Furthermore, we provide extensive analyses to confirm the effectiveness of our method. The code will be publicly released.
Leveraging BEV Representation for 360-degree Visual Place Recognition
May 23, 2023



This paper investigates the advantages of using Bird's Eye View (BEV) representation in 360-degree visual place recognition (VPR). We propose a novel network architecture that utilizes the BEV representation in feature extraction, feature aggregation, and vision-LiDAR fusion, which bridges visual cues and spatial awareness. Our method extracts image features using standard convolutional networks and combines the features according to pre-defined 3D grid spatial points. To alleviate the mechanical and time misalignments between cameras, we further introduce deformable attention to learn the compensation. Upon the BEV feature representation, we then employ the polar transform and the Discrete Fourier transform for aggregation, which is shown to be rotation-invariant. In addition, the image and point cloud cues can be easily stated in the same coordinates, which benefits sensor fusion for place recognition. The proposed BEV-based method is evaluated in ablation and comparative studies on two datasets, including on-the-road and off-the-road scenarios. The experimental results verify the hypothesis that BEV can benefit VPR by its superior performance compared to baseline methods. To the best of our knowledge, this is the first trial of employing BEV representation in this task.
A Survey on Global LiDAR Localization
Feb 15, 2023



Knowledge about the own pose is key for all mobile robot applications. Thus pose estimation is part of the core functionalities of mobile robots. In the last two decades, LiDAR scanners have become a standard sensor for robot localization and mapping. This article surveys recent progress and advances in LiDAR-based global localization. We start with the problem formulation and explore the application scope. We then present the methodology review covering various global localization topics, such as maps, descriptor extraction, and consistency checks. The contents are organized under three themes. The first is the combination of global place retrieval and local pose estimation. Then the second theme is upgrading single-shot measurement to sequential ones for sequential global localization. The third theme is extending single-robot global localization to cross-robot localization on multi-robot systems. We end this survey with a discussion of open challenges and promising directions on global lidar localization.
RING++: Roto-translation Invariant Gram for Global Localization on a Sparse Scan Map
Oct 12, 2022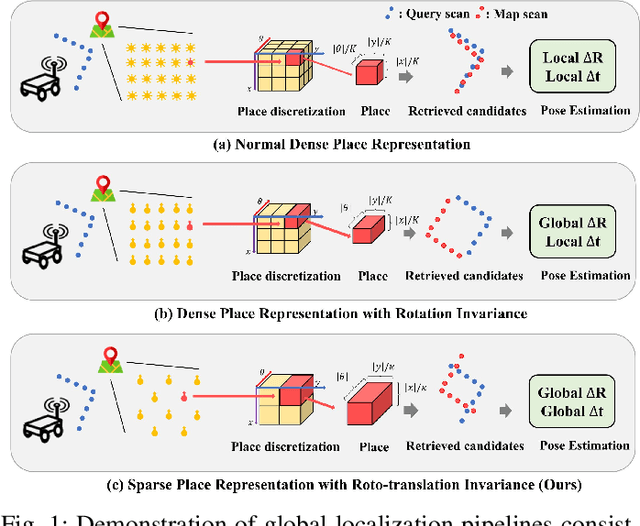
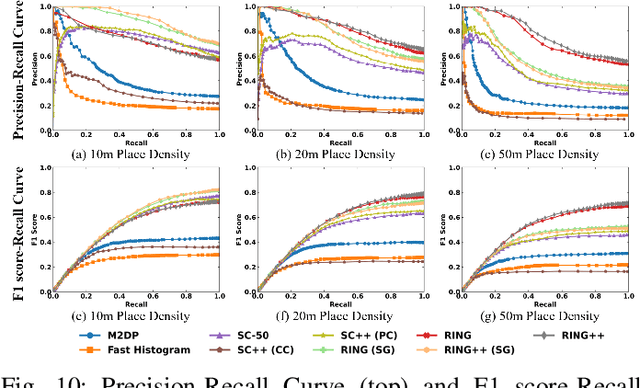
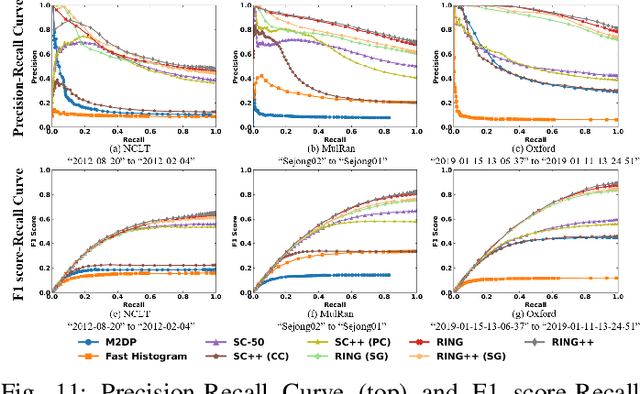
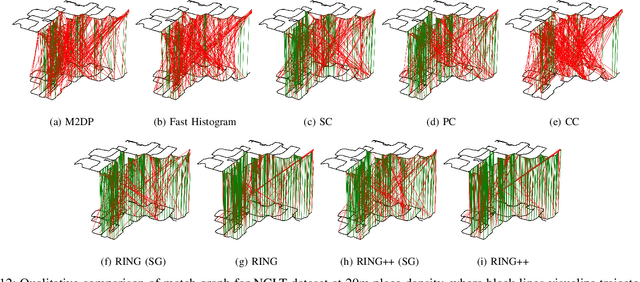
Global localization plays a critical role in many robot applications. LiDAR-based global localization draws the community's focus with its robustness against illumination and seasonal changes. To further improve the localization under large viewpoint differences, we propose RING++ which has roto-translation invariant representation for place recognition, and global convergence for both rotation and translation estimation. With the theoretical guarantee, RING++ is able to address the large viewpoint difference using a lightweight map with sparse scans. In addition, we derive sufficient conditions of feature extractors for the representation preserving the roto-translation invariance, making RING++ a framework applicable to generic multi-channel features. To the best of our knowledge, this is the first learning-free framework to address all subtasks of global localization in the sparse scan map. Validations on real-world datasets show that our approach demonstrates better performance than state-of-the-art learning-free methods, and competitive performance with learning-based methods. Finally, we integrate RING++ into a multi-robot/session SLAM system, performing its effectiveness in collaborative applications.
DPCN++: Differentiable Phase Correlation Network for Versatile Pose Registration
Jun 12, 2022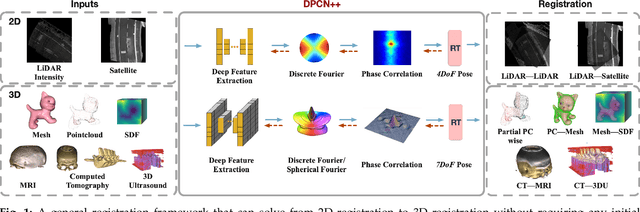
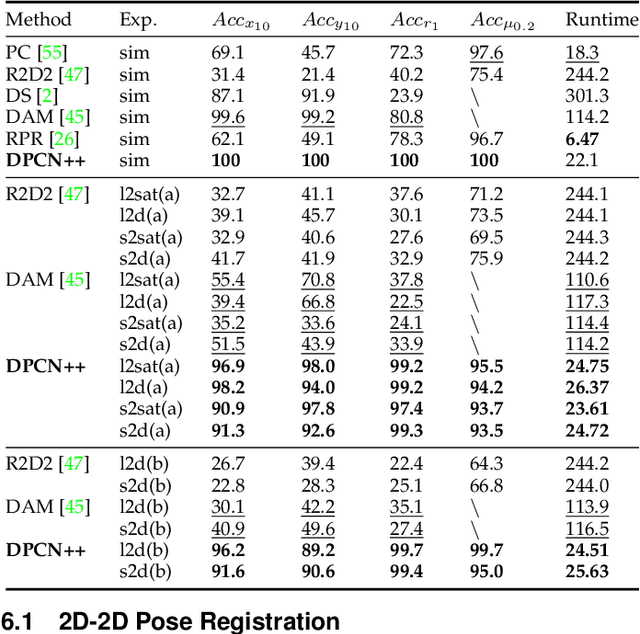
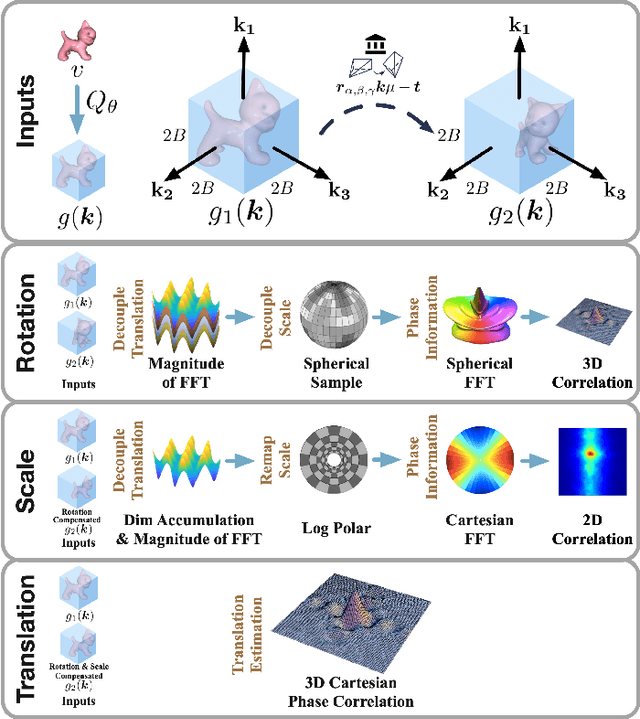
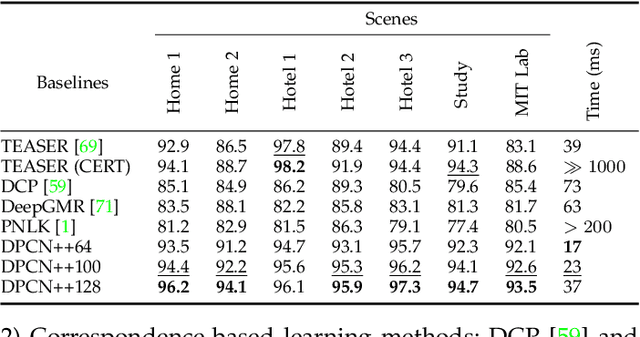
Pose registration is critical in vision and robotics. This paper focuses on the challenging task of initialization-free pose registration up to 7DoF for homogeneous and heterogeneous measurements. While recent learning-based methods show promise using differentiable solvers, they either rely on heuristically defined correspondences or are prone to local minima. We present a differentiable phase correlation (DPC) solver that is globally convergent and correspondence-free. When combined with simple feature extraction networks, our general framework DPCN++ allows for versatile pose registration with arbitrary initialization. Specifically, the feature extraction networks first learn dense feature grids from a pair of homogeneous/heterogeneous measurements. These feature grids are then transformed into a translation and scale invariant spectrum representation based on Fourier transform and spherical radial aggregation, decoupling translation and scale from rotation. Next, the rotation, scale, and translation are independently and efficiently estimated in the spectrum step-by-step using the DPC solver. The entire pipeline is differentiable and trained end-to-end. We evaluate DCPN++ on a wide range of registration tasks taking different input modalities, including 2D bird's-eye view images, 3D object and scene measurements, and medical images. Experimental results demonstrate that DCPN++ outperforms both classical and learning-based baselines, especially on partially observed and heterogeneous measurements.
One RING to Rule Them All: Radon Sinogram for Place Recognition, Orientation and Translation Estimation
Apr 17, 2022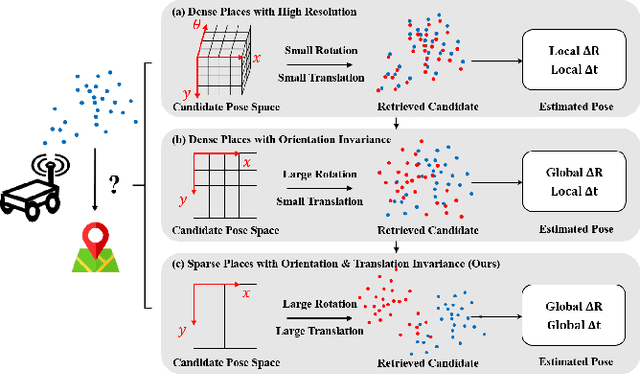
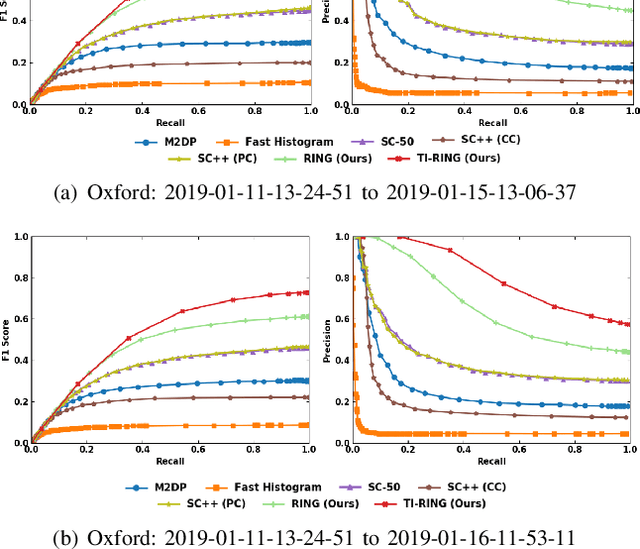
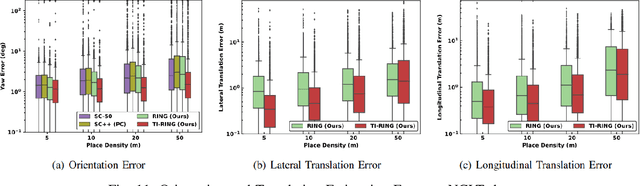

LiDAR-based global localization is a fundamental problem for mobile robots. It consists of two stages, place recognition and pose estimation, and yields the current orientation and translation, using only the current scan as query and a database of map scans. Inspired by the definition of a recognized place, we consider that a good global localization solution should keep the pose estimation accuracy with a lower place density. Following this idea, we propose a novel framework towards sparse place-based global localization, which utilizes a unified and learning-free representation, Radon sinogram (RING), for all sub-tasks. Based on the theoretical derivation, a translation invariant descriptor and an orientation invariant metric are proposed for place recognition, achieving certifiable robustness against arbitrary orientation and large translation between query and map scan. In addition, we also utilize the property of RING to propose a global convergent solver for both orientation and translation estimation, arriving at global localization. Evaluation of the proposed RING based framework validates the feasibility and demonstrates a superior performance even under a lower place density.
Translation Invariant Global Estimation of Heading Angle Using Sinogram of LiDAR Point Cloud
Mar 02, 2022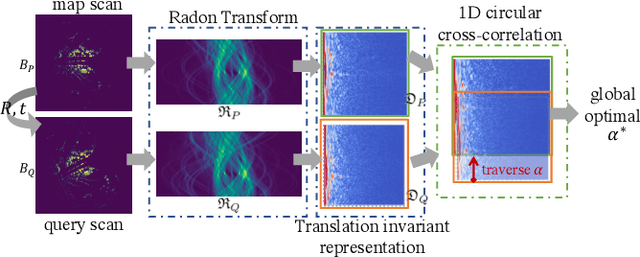
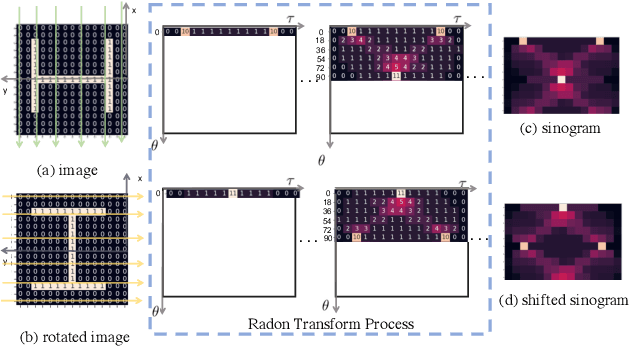
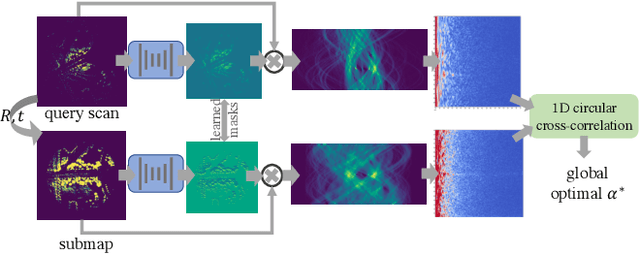
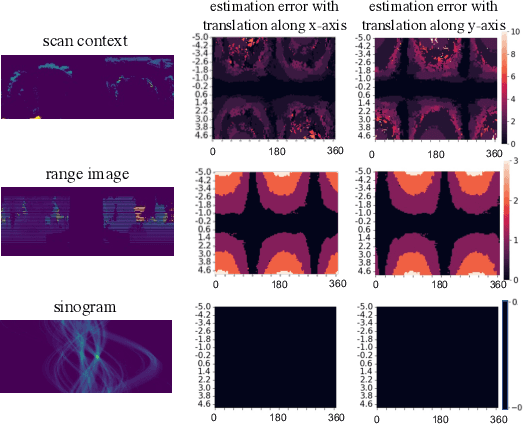
Global point cloud registration is an essential module for localization, of which the main difficulty exists in estimating the rotation globally without initial value. With the aid of gravity alignment, the degree of freedom in point cloud registration could be reduced to 4DoF, in which only the heading angle is required for rotation estimation. In this paper, we propose a fast and accurate global heading angle estimation method for gravity-aligned point clouds. Our key idea is that we generate a translation invariant representation based on Radon Transform, allowing us to solve the decoupled heading angle globally with circular cross-correlation. Besides, for heading angle estimation between point clouds with different distributions, we implement this heading angle estimator as a differentiable module to train a feature extraction network end- to-end. The experimental results validate the effectiveness of the proposed method in heading angle estimation and show better performance compared with other methods.
HiTMap: A Hierarchical Topological Map Representation for Navigation in Unknown Environments
Sep 20, 2021

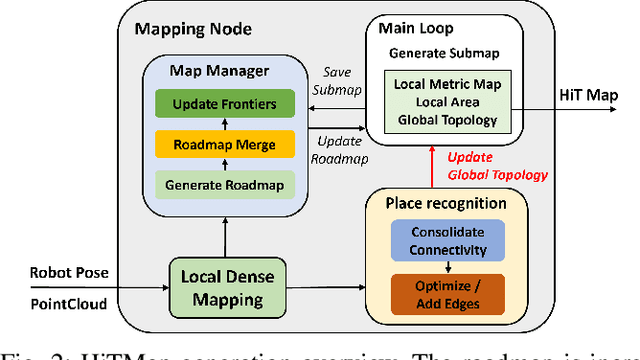
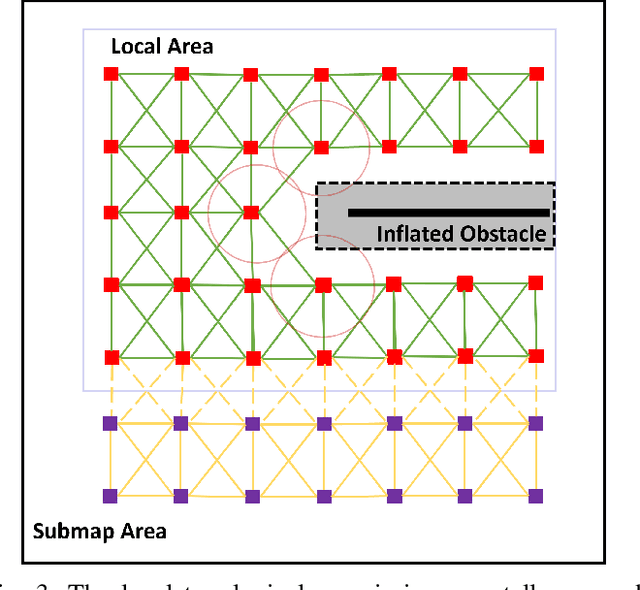
The ability to autonomously navigate in unknown environments is important for mobile robots. The map is the core component to achieve this. Most map representations rely on drift-free state estimation and provide a global metric map to navigate. However, in large-scale real-world applications, it's hard to prohibit drifts and compose a globally consistent map quickly. In this paper, a novel representation named, HiTMap, is proposed to enhance the existing map representations. The central idea is to adopt a submap-based hierarchical topology rather than a global metric map so that only a local metric map is maintained for obstacle avoidance which ensures the lightweight of the representation. To guide the robots navigate into unknown spaces, frontiers are detected and attached to the map as an attribute. We also develop a path planning module to evaluate the feasibility and efficiency of our map representation. The system is validated in a simulation environment and a demonstration in the real world is conducted. In addition, the HiTMap is made available open-source.
Learn to Differ: Sim2Real Small Defection Segmentation Network
Mar 07, 2021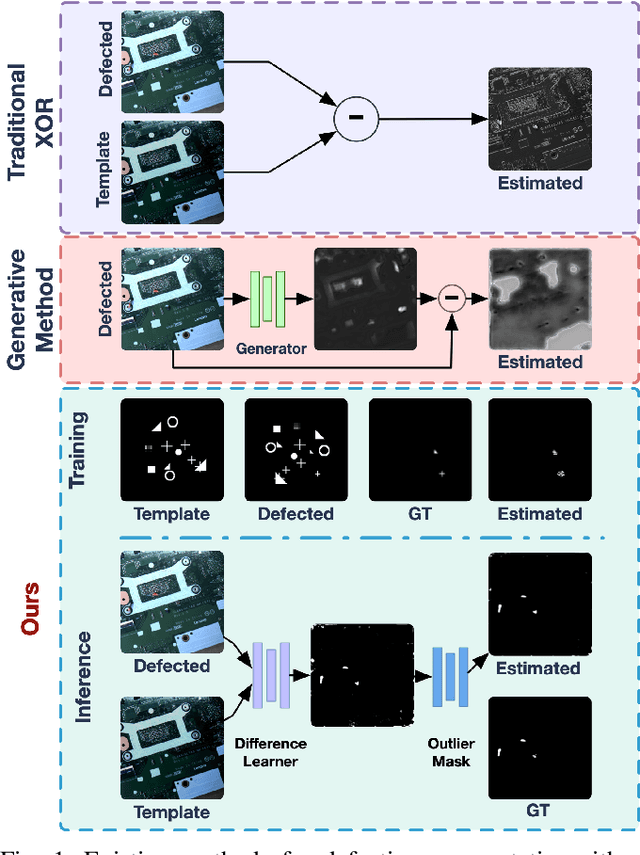
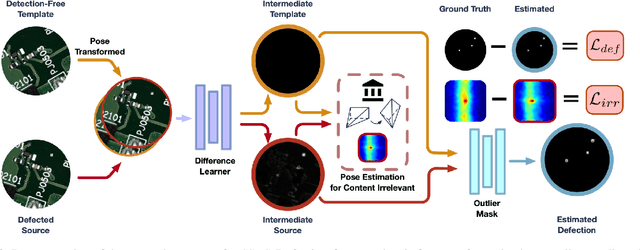

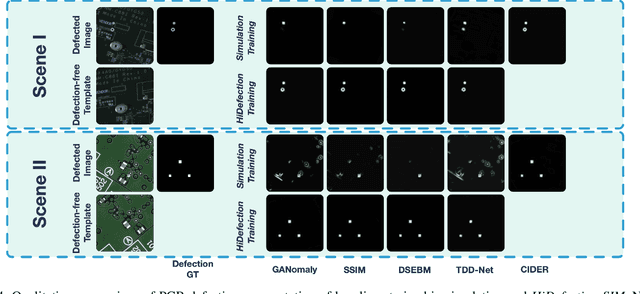
Recent studies on deep-learning-based small defection segmentation approaches are trained in specific settings and tend to be limited by fixed context. Throughout the training, the network inevitably learns the representation of the background of the training data before figuring out the defection. They underperform in the inference stage once the context changed and can only be solved by training in every new setting. This eventually leads to the limitation in practical robotic applications where contexts keep varying. To cope with this, instead of training a network context by context and hoping it to generalize, why not stop misleading it with any limited context and start training it with pure simulation? In this paper, we propose the network SSDS that learns a way of distinguishing small defections between two images regardless of the context, so that the network can be trained once for all. A small defection detection layer utilizing the pose sensitivity of phase correlation between images is introduced and is followed by an outlier masking layer. The network is trained on randomly generated simulated data with simple shapes and is generalized across the real world. Finally, SSDS is validated on real-world collected data and demonstrates the ability that even when trained in cheap simulation, SSDS can still find small defections in the real world showing the effectiveness and its potential for practical applications.
Radar-to-Lidar: Heterogeneous Place Recognition via Joint Learning
Jan 30, 2021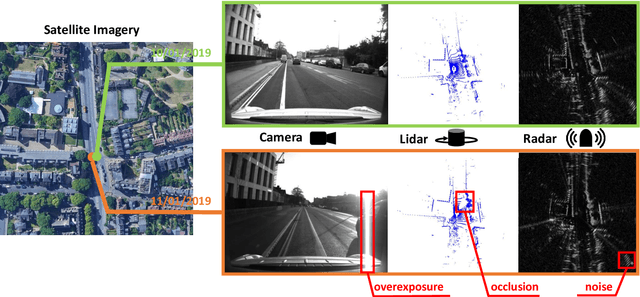

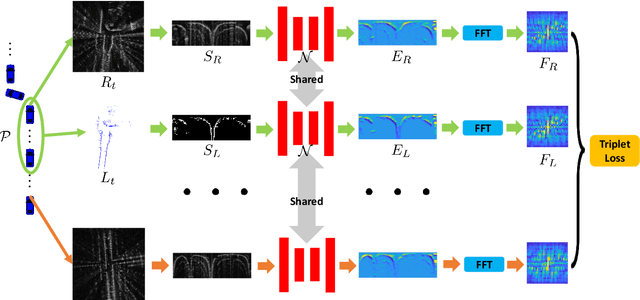

Place recognition is critical for both offline mapping and online localization. However, current single-sensor based place recognition still remains challenging in adverse conditions. In this paper, a heterogeneous measurements based framework is proposed for long-term place recognition, which retrieves the query radar scans from the existing lidar maps. To achieve this, a deep neural network is built with joint training in the learning stage, and then in the testing stage, shared embeddings of radar and lidar are extracted for heterogeneous place recognition. To validate the effectiveness of the proposed method, we conduct tests and generalization on the multi-session public datasets compared to other competitive methods. The experimental results indicate that our model is able to perform multiple place recognitions: lidar-to-lidar, radar-to-radar and radar-to-lidar, while the learned model is trained only once. We also release the source code publicly.