 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCFORGE-BENCH: A Comprehensive Benchmark for Document Forgery Detection and Analysis
Mar 02, 2026We present DOCFORGE-BENCH, the first unified zero-shot benchmark for document forgery detection, evaluating 14 methods across eight datasets spanning text tampering, receipt forgery, and identity document manipulation. Unlike fine-tuning-oriented evaluations such as ForensicHub [Du et al., 2025], DOCFORGE-BENCH applies all methods with their published pretrained weights and no domain adaptation -- a deliberate design choice that reflects the realistic deployment scenario where practitioners lack labeled document training data. Our central finding is a pervasive calibration failure invisible under single-threshold protocols: methods achieve moderate Pixel-AUC (>=0.76) yet near-zero Pixel-F1. This AUC-F1 gap is not a discrimination failure but a score-distribution shift: tampered regions occupy only 0.27-4.17% of pixels in document images -- an order of magnitude less than in natural image benchmarks -- making the standard tau=0.5 threshold catastrophically miscalibrated. Oracle-F1 is 2-10x higher than fixed-threshold Pixel-F1, confirming that calibration, not representation, is the bottleneck. A controlled calibration experiment validates this: adapting a single threshold on N=10 domain images recovers 39-55% of the Oracle-F1 gap, demonstrating that threshold adaptation -- not retraining -- is the key missing step for practical deployment. Overall, no evaluated method works reliably out-of-the-box on diverse document types, underscoring that document forgery detection remains an unsolved problem. We further note that all eight datasets predate the era of generative AI editing; benchmarks covering diffusion- and LLM-based document forgeries represent a critical open gap on the modern attack surface.
Attention Mechanism and Context Modeling System for Text Mining Machine Translation
Aug 08, 2024



This paper advances a novel architectural schema anchored upon the Transformer paradigm and innovatively amalgamates the K-means categorization algorithm to augment the contextual apprehension capabilities of the schema. The transformer model performs well in machine translation tasks due to its parallel computing power and multi-head attention mechanism. However, it may encounter contextual ambiguity or ignore local features when dealing with highly complex language structures. To circumvent this constraint, this exposition incorporates the K-Means algorithm, which is used to stratify the lexis and idioms of the input textual matter, thereby facilitating superior identification and preservation of the local structure and contextual intelligence of the language. The advantage of this combination is that K-Means can automatically discover the topic or concept regions in the text, which may be directly related to translation quality. Consequently, the schema contrived herein enlists K-Means as a preparatory phase antecedent to the Transformer and recalibrates the multi-head attention weights to assist in the discrimination of lexis and idioms bearing analogous semantics or functionalities. This ensures the schema accords heightened regard to the contextual intelligence embodied by these clusters during the training phase, rather than merely focusing on locational intelligence.
Research on Feature Extraction Data Processing System For MRI of Brain Diseases Based on Computer Deep Learning
Jun 23, 2024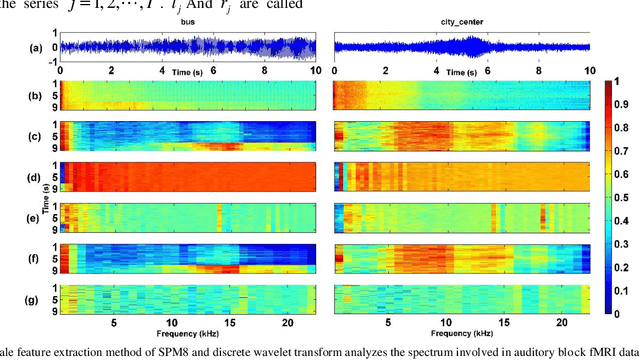
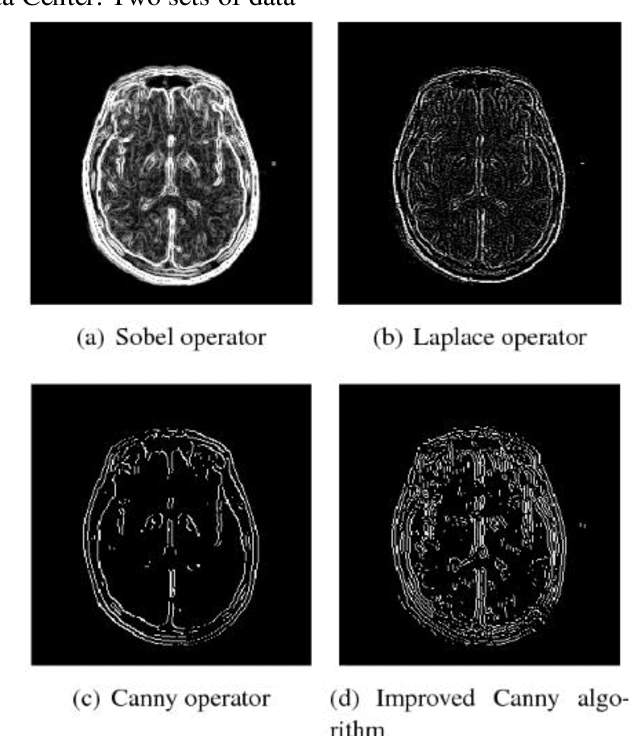

Most of the existing wavelet image processing techniques are carried out in the form of single-scale reconstruction and multiple iterations. However, processing high-quality fMRI data presents problems such as mixed noise and excessive computation time. This project proposes the use of matrix operations by combining mixed noise elimination methods with wavelet analysis to replace traditional iterative algorithms. Functional magnetic resonance imaging (fMRI) of the auditory cortex of a single subject is analyzed and compared to the wavelet domain signal processing technology based on repeated times and the world's most influential SPM8. Experiments show that this algorithm is the fastest in computing time, and its detection effect is comparable to the traditional iterative algorithm. However, this has a higher practical value for the processing of FMRI data. In addition, the wavelet analysis method proposed signal processing to speed up the calculation rate.
Research on Disease Prediction Model Construction Based on Computer AI deep Learning Technology
Jun 23, 2024

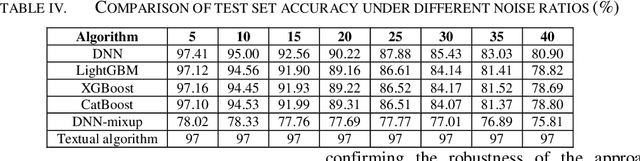
The prediction of disease risk factors can screen vulnerable groups for effective prevention and treatment, so as to reduce their morbidity and mortality. Machine learning has a great demand for high-quality labeling information, and labeling noise in medical big data poses a great challenge to efficient disease risk warning methods. Therefore, this project intends to study the robust learning algorithm and apply it to the early warning of infectious disease risk. A dynamic truncated loss model is proposed, which combines the traditional mutual entropy implicit weight feature with the mean variation feature. It is robust to label noise. A lower bound on training loss is constructed, and a method based on sampling rate is proposed to reduce the gradient of suspected samples to reduce the influence of noise on training results. The effectiveness of this method under different types of noise was verified by using a stroke screening data set as an example. This method enables robust learning of data containing label noise.
Exploration of Attention Mechanism-Enhanced Deep Learning Models in the Mining of Medical Textual Data
May 23, 2024



The research explores the utilization of a deep learning model employing an attention mechanism in medical text mining. It targets the challenge of analyzing unstructured text information within medical data. This research seeks to enhance the model's capability to identify essential medical information by incorporating deep learning and attention mechanisms. This paper reviews the basic principles and typical model architecture of attention mechanisms and shows the effectiveness of their application in the tasks of disease prediction, drug side effect monitoring, and entity relationship extraction. Aiming at the particularity of medical texts, an adaptive attention model integrating domain knowledge is proposed, and its ability to understand medical terms and process complex contexts is optimized. The experiment verifies the model's effectiveness in improving task accuracy and robustness, especially when dealing with long text. The future research path of enhancing model interpretation, realizing cross-domain knowledge transfer, and adapting to low-resource scenarios is discussed in the research outlook, which provides a new perspective and method support for intelligent medical information processing and clinical decision assistance. Finally, cross-domain knowledge transfer and adaptation strategies for low-resource scenarios, providing theoretical basis and technical reference for promoting the development of intelligent medical information processing and clinical decision support systems.
Leveraging Large Language Models in Conversational Recommender Systems
May 16, 2023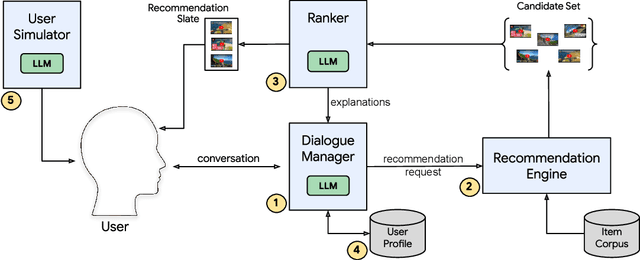



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
DPCN++: Differentiable Phase Correlation Network for Versatile Pose Registration
Jun 12, 2022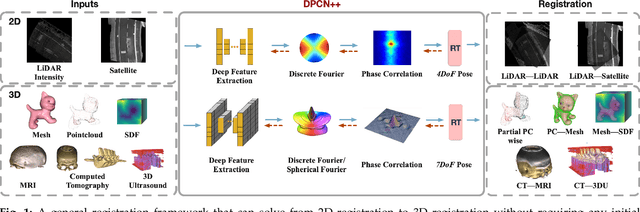
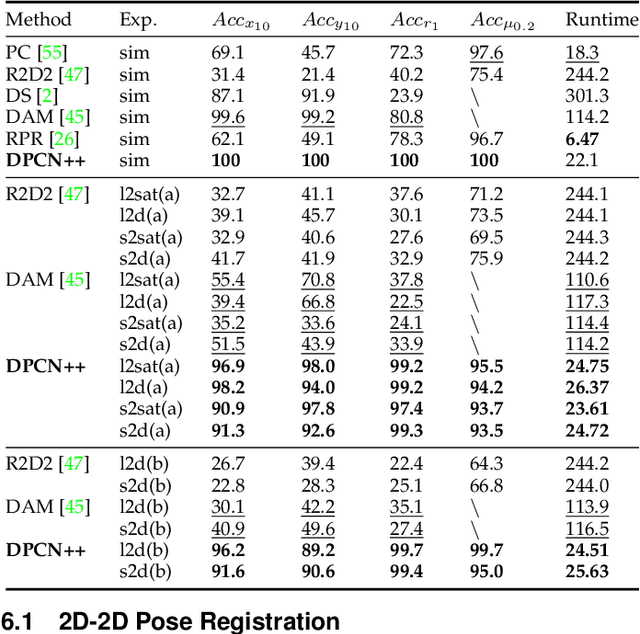
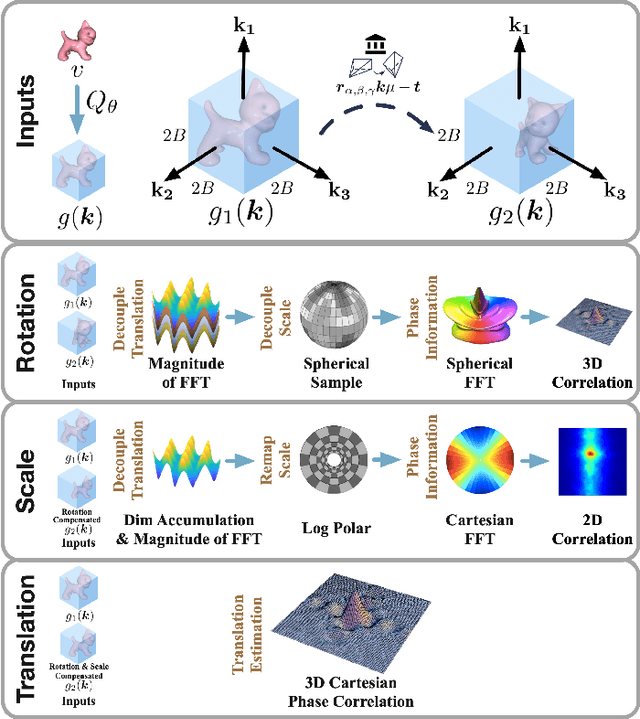
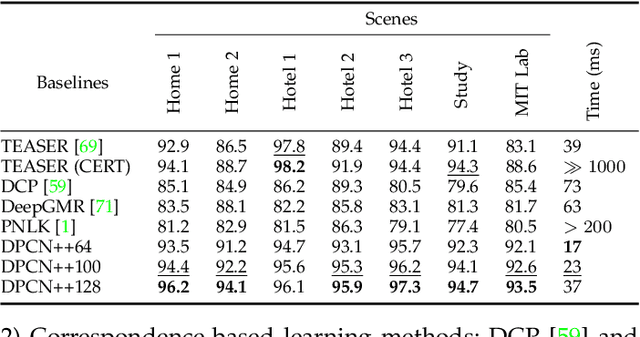
Pose registration is critical in vision and robotics. This paper focuses on the challenging task of initialization-free pose registration up to 7DoF for homogeneous and heterogeneous measurements. While recent learning-based methods show promise using differentiable solvers, they either rely on heuristically defined correspondences or are prone to local minima. We present a differentiable phase correlation (DPC) solver that is globally convergent and correspondence-free. When combined with simple feature extraction networks, our general framework DPCN++ allows for versatile pose registration with arbitrary initialization. Specifically, the feature extraction networks first learn dense feature grids from a pair of homogeneous/heterogeneous measurements. These feature grids are then transformed into a translation and scale invariant spectrum representation based on Fourier transform and spherical radial aggregation, decoupling translation and scale from rotation. Next, the rotation, scale, and translation are independently and efficiently estimated in the spectrum step-by-step using the DPC solver. The entire pipeline is differentiable and trained end-to-end. We evaluate DCPN++ on a wide range of registration tasks taking different input modalities, including 2D bird's-eye view images, 3D object and scene measurements, and medical images. Experimental results demonstrate that DCPN++ outperforms both classical and learning-based baselines, especially on partially observed and heterogeneous measurements.
Least Square Estimation Network for Depth Completion
Mar 07, 2022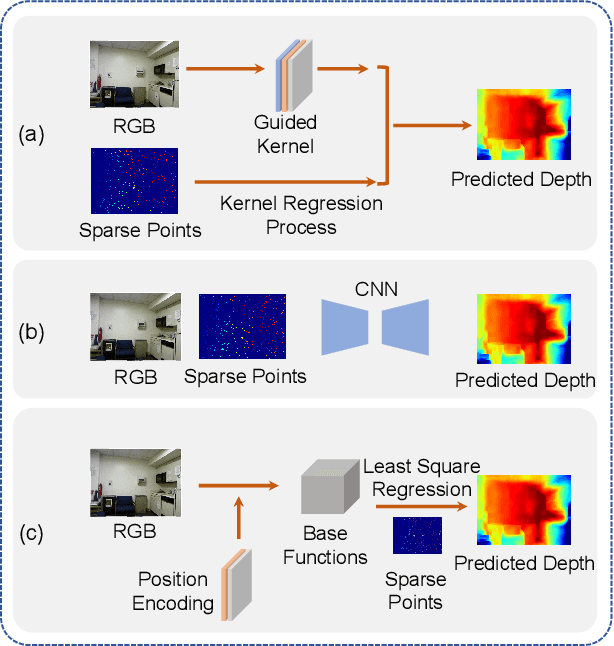
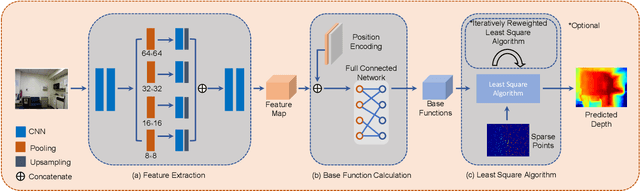
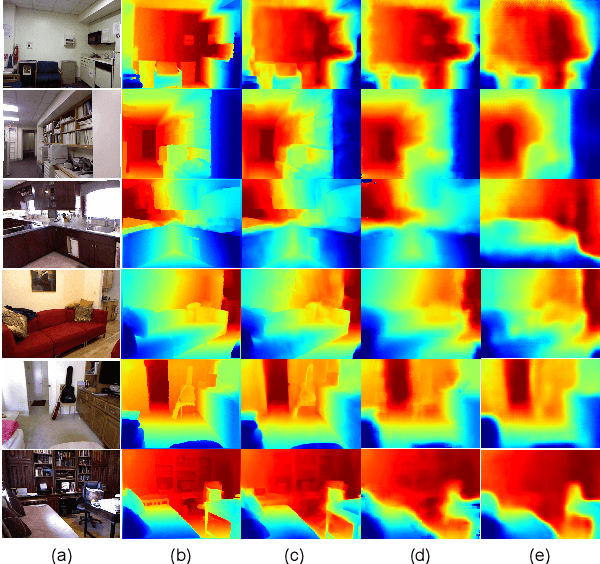
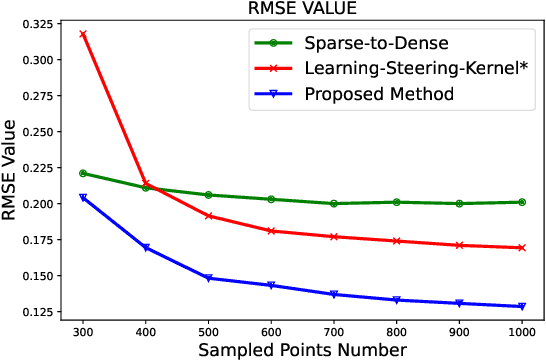
Depth completion is a fundamental task in computer vision and robotics research. Many previous works complete the dense depth map with neural networks directly but most of them are non-interpretable and can not generalize to different situations well. In this paper, we propose an effective image representation method for depth completion tasks. The input of our system is a monocular camera frame and the synchronous sparse depth map. The output of our system is a dense per-pixel depth map of the frame. First we use a neural network to transform each pixel into a feature vector, which we call base functions. Then we pick out the known pixels' base functions and their depth values. We use a linear least square algorithm to fit the base functions and the depth values. Then we get the weights estimated from the least square algorithm. Finally, we apply the weights to the whole image and predict the final depth map. Our method is interpretable so it can generalize well. Experiments show that our results beat the state-of-the-art on NYU-Depth-V2 dataset both in accuracy and runtime. Moreover, experiments show that our method can generalize well on different numbers of sparse points and different datasets.
Fully Differentiable and Interpretable Model for VIO with 4 Trainable Parameters
Sep 25, 2021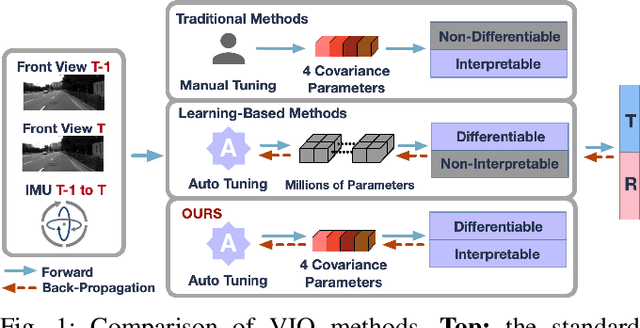
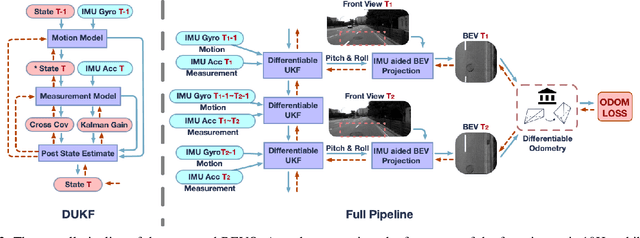
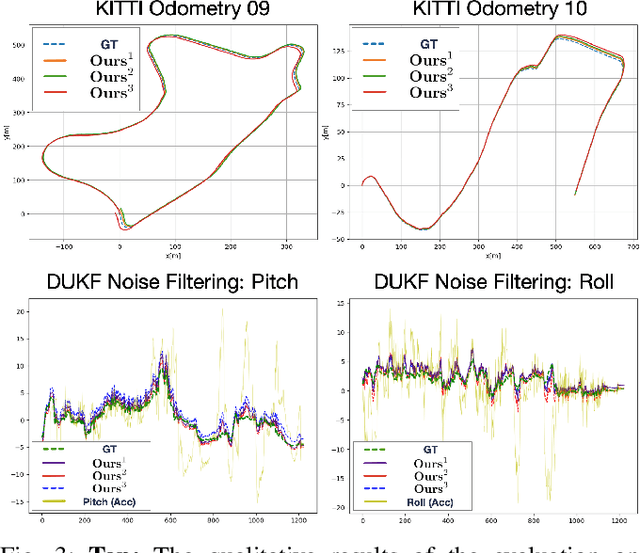
Monocular visual-inertial odometry (VIO) is a critical problem in robotics and autonomous driving. Traditional methods solve this problem based on filtering or optimization. While being fully interpretable, they rely on manual interference and empirical parameter tuning. On the other hand, learning-based approaches allow for end-to-end training but require a large number of training data to learn millions of parameters. However, the non-interpretable and heavy models hinder the generalization ability. In this paper, we propose a fully differentiable, interpretable, and lightweight monocular VIO model that contains only 4 trainable parameters. Specifically, we first adopt Unscented Kalman Filter as a differentiable layer to predict the pitch and roll, where the covariance matrices of noise are learned to filter out the noise of the IMU raw data. Second, the refined pitch and roll are adopted to retrieve a gravity-aligned BEV image of each frame using differentiable camera projection. Finally, a differentiable pose estimator is utilized to estimate the remaining 4 DoF poses between the BEV frames. Our method allows for learning the covariance matrices end-to-end supervised by the pose estimation loss, demonstrating superior performance to empirical baselines. Experimental results on synthetic and real-world datasets demonstrate that our simple approach is competitive with state-of-the-art methods and generalizes well on unseen scenes.
Domain Generalization for Vision-based Driving Trajectory Generation
Sep 22, 2021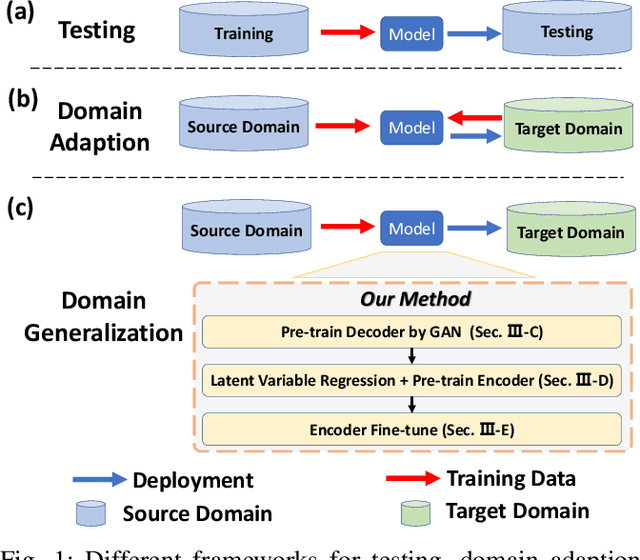
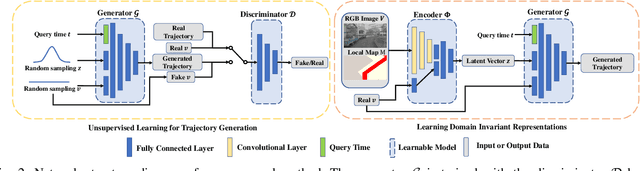
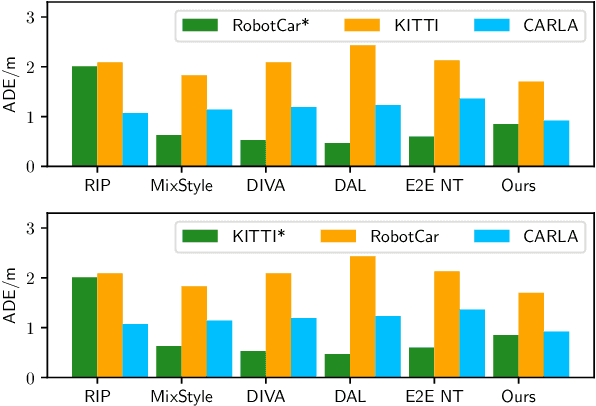

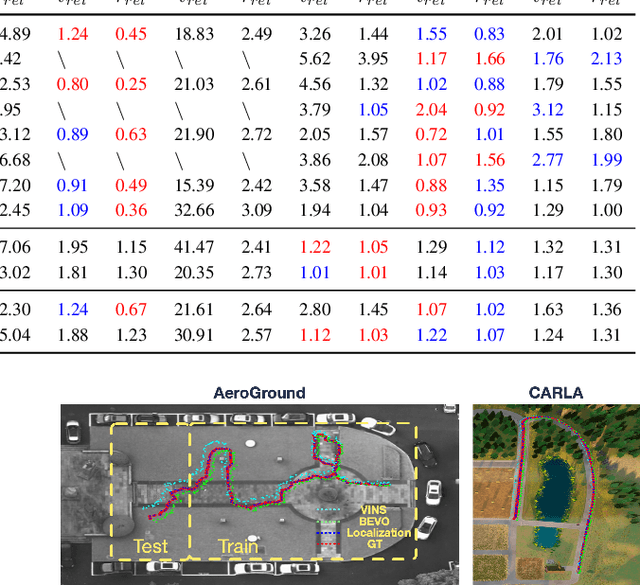
One of the challenges in vision-based driving trajectory generation is dealing with out-of-distribution scenarios. In this paper, we propose a domain generalization method for vision-based driving trajectory generation for autonomous vehicles in urban environments, which can be seen as a solution to extend the Invariant Risk Minimization (IRM) method in complex problems. We leverage an adversarial learning approach to train a trajectory generator as the decoder. Based on the pre-trained decoder, we infer the latent variables corresponding to the trajectories, and pre-train the encoder by regressing the inferred latent variable. Finally, we fix the decoder but fine-tune the encoder with the final trajectory loss. We compare our proposed method with the state-of-the-art trajectory generation method and some recent domain generalization methods on both datasets and simulation, demonstrating that our method has better generalization ability.