 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast Square Estimation Network for Depth Completion
Paper and Code
Mar 07, 2022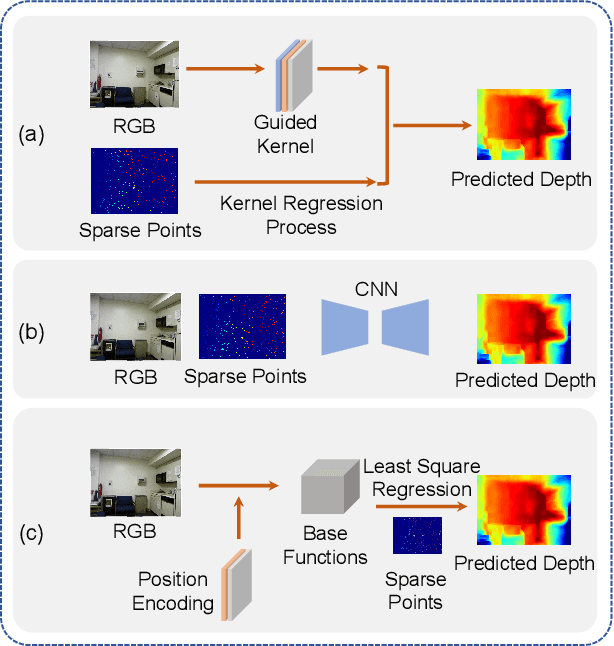
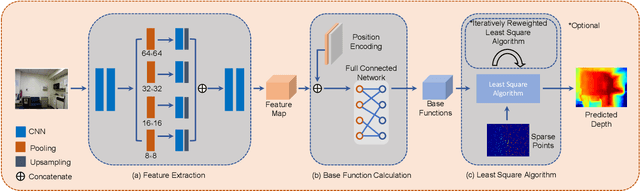
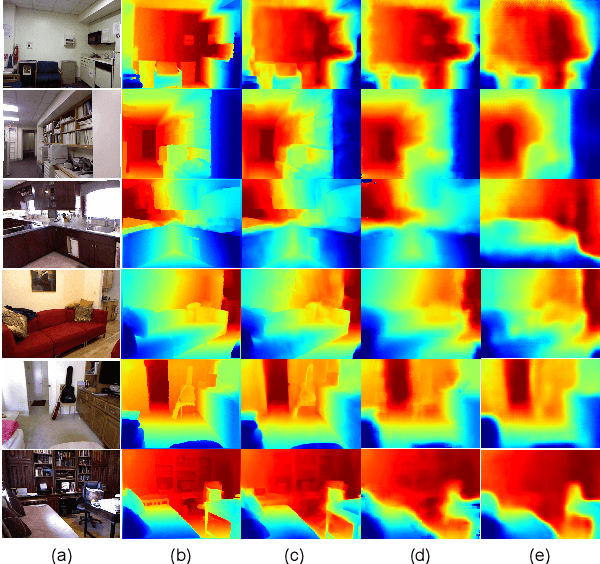
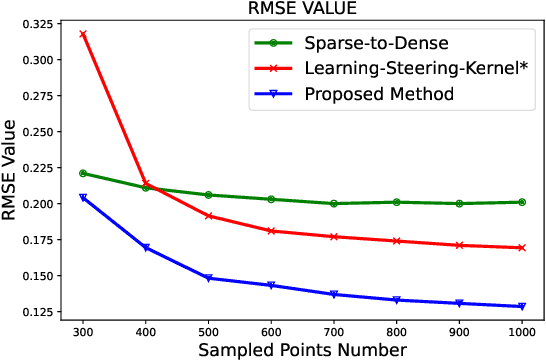
Depth completion is a fundamental task in computer vision and robotics research. Many previous works complete the dense depth map with neural networks directly but most of them are non-interpretable and can not generalize to different situations well. In this paper, we propose an effective image representation method for depth completion tasks. The input of our system is a monocular camera frame and the synchronous sparse depth map. The output of our system is a dense per-pixel depth map of the frame. First we use a neural network to transform each pixel into a feature vector, which we call base functions. Then we pick out the known pixels' base functions and their depth values. We use a linear least square algorithm to fit the base functions and the depth values. Then we get the weights estimated from the least square algorithm. Finally, we apply the weights to the whole image and predict the final depth map. Our method is interpretable so it can generalize well. Experiments show that our results beat the state-of-the-art on NYU-Depth-V2 dataset both in accuracy and runtime. Moreover, experiments show that our method can generalize well on different numbers of sparse points and different datasets.