 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Few-Shot Learning with Integrated Data and GAN Model Approaches
Nov 25, 2024This paper presents an innovative approach to enhancing few-shot learning by integrating data augmentation with model fine-tuning in a framework designed to tackle the challenges posed by small-sample data. Recognizing the critical limitations of traditional machine learning models that require large datasets-especially in fields such as drug discovery, target recognition, and malicious traffic detection-this study proposes a novel strategy that leverages Generative Adversarial Networks (GANs) and advanced optimization techniques to improve model performance with limited data. Specifically, the paper addresses the noise and bias issues introduced by data augmentation methods, contrasting them with model-based approaches, such as fine-tuning and metric learning, which rely heavily on related datasets. By combining Markov Chain Monte Carlo (MCMC) sampling and discriminative model ensemble strategies within a GAN framework, the proposed model adjusts generative and discriminative distributions to simulate a broader range of relevant data. Furthermore, it employs MHLoss and a reparameterized GAN ensemble to enhance stability and accelerate convergence, ultimately leading to improved classification performance on small-sample images and structured datasets. Results confirm that the MhERGAN algorithm developed in this research is highly effective for few-shot learning, offering a practical solution that bridges data scarcity with high-performing model adaptability and generalization.
Research on Feature Extraction Data Processing System For MRI of Brain Diseases Based on Computer Deep Learning
Jun 23, 2024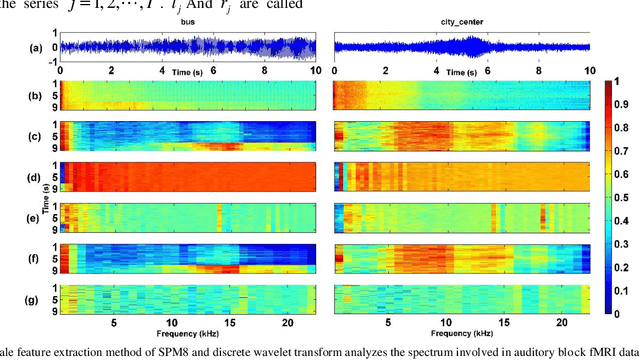
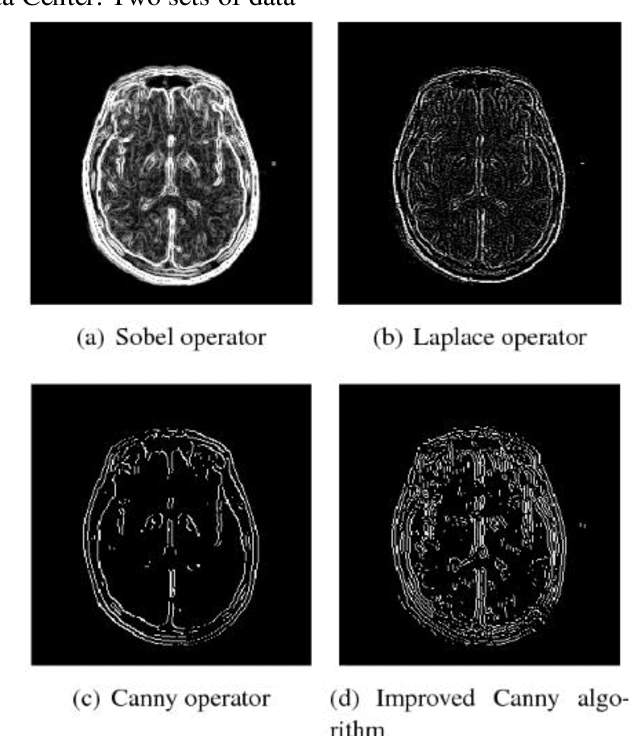

Most of the existing wavelet image processing techniques are carried out in the form of single-scale reconstruction and multiple iterations. However, processing high-quality fMRI data presents problems such as mixed noise and excessive computation time. This project proposes the use of matrix operations by combining mixed noise elimination methods with wavelet analysis to replace traditional iterative algorithms. Functional magnetic resonance imaging (fMRI) of the auditory cortex of a single subject is analyzed and compared to the wavelet domain signal processing technology based on repeated times and the world's most influential SPM8. Experiments show that this algorithm is the fastest in computing time, and its detection effect is comparable to the traditional iterative algorithm. However, this has a higher practical value for the processing of FMRI data. In addition, the wavelet analysis method proposed signal processing to speed up the calculation rate.
Research on Disease Prediction Model Construction Based on Computer AI deep Learning Technology
Jun 23, 2024

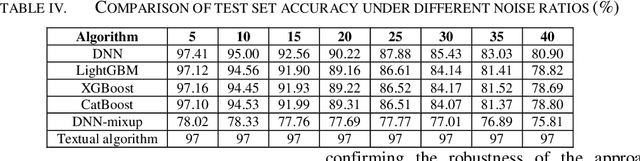
The prediction of disease risk factors can screen vulnerable groups for effective prevention and treatment, so as to reduce their morbidity and mortality. Machine learning has a great demand for high-quality labeling information, and labeling noise in medical big data poses a great challenge to efficient disease risk warning methods. Therefore, this project intends to study the robust learning algorithm and apply it to the early warning of infectious disease risk. A dynamic truncated loss model is proposed, which combines the traditional mutual entropy implicit weight feature with the mean variation feature. It is robust to label noise. A lower bound on training loss is constructed, and a method based on sampling rate is proposed to reduce the gradient of suspected samples to reduce the influence of noise on training results. The effectiveness of this method under different types of noise was verified by using a stroke screening data set as an example. This method enables robust learning of data containing label noise.
Exploration of Attention Mechanism-Enhanced Deep Learning Models in the Mining of Medical Textual Data
May 23, 2024



The research explores the utilization of a deep learning model employing an attention mechanism in medical text mining. It targets the challenge of analyzing unstructured text information within medical data. This research seeks to enhance the model's capability to identify essential medical information by incorporating deep learning and attention mechanisms. This paper reviews the basic principles and typical model architecture of attention mechanisms and shows the effectiveness of their application in the tasks of disease prediction, drug side effect monitoring, and entity relationship extraction. Aiming at the particularity of medical texts, an adaptive attention model integrating domain knowledge is proposed, and its ability to understand medical terms and process complex contexts is optimized. The experiment verifies the model's effectiveness in improving task accuracy and robustness, especially when dealing with long text. The future research path of enhancing model interpretation, realizing cross-domain knowledge transfer, and adapting to low-resource scenarios is discussed in the research outlook, which provides a new perspective and method support for intelligent medical information processing and clinical decision assistance. Finally, cross-domain knowledge transfer and adaptation strategies for low-resource scenarios, providing theoretical basis and technical reference for promoting the development of intelligent medical information processing and clinical decision support systems.