 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSBF: An Effective Representation to Augment Skeleton for Video-based Human Action Recognition
Apr 04, 2026Many modern video-based human action recognition (HAR) approaches use 2D skeleton as the intermediate representation in their prediction pipelines. Despite overall encouraging results, these approaches still struggle in many common scenes, mainly because the skeleton does not capture critical action-related information pertaining to the depth of the joints, contour of the human body, and interaction between the human and objects. To address this, we propose an effective approach to augment skeleton with a representation capturing action-related information in the pipeline of HAR. The representation, termed Scale-Body-Flow (SBF), consists of three distinct components, namely a scale map volume given by the scale (and hence depth information) of each joint, a body map outlining the human subject, and a flow map indicating human-object interaction given by pixel-wise optical flow values. To predict SBF, we further present SFSNet, a novel segmentation network supervised by the skeleton and optical flow without extra annotation overhead beyond the existing skeleton extraction. Extensive experiments across different datasets demonstrate that our pipeline based on SBF and SFSNet achieves significantly higher HAR accuracy with similar compactness and efficiency as compared with the state-of-the-art skeleton-only approaches.
Systematic validation of time-resolved diffuse optical simulators via non-contact SPAD-based measurements
Nov 17, 2025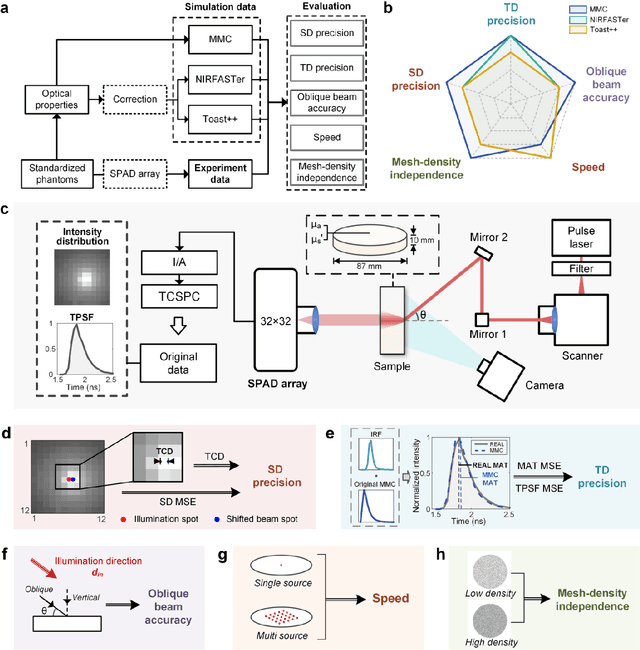
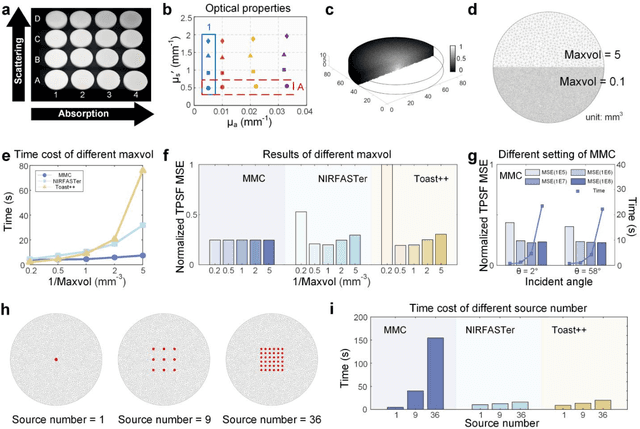
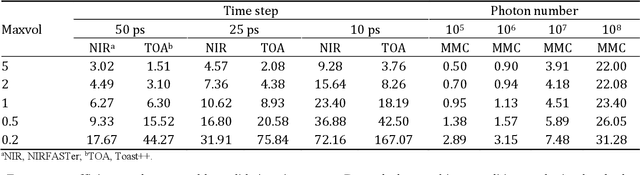
Objective: Time-domain diffuse optical imaging (DOI) requires accurate forward models for photon propagation in scattering media. However, existing simulators lack comprehensive experimental validation, especially for non-contact configurations with oblique illumination. This study rigorously evaluates three widely used open-source simulators, including MMC, NIRFASTer, and Toast++, using time-resolved experimental data. Approach: All simulations employed a unified mesh and point-source illumination. Virtual source correction was applied to FEM solvers for oblique incidence. A time-resolved DOI system with a 32 $\times$ 32 single-photon avalanche diode (SPAD) array acquired transmission-mode data from 16 standardized phantoms with varying absorption coefficient $μ_a$ and reduced scattering coefficient $μ_s'$. The simulation results were quantified across five metrics: spatial-domain (SD) precision, time-domain (TD) precision, oblique beam accuracy, computational speed, and mesh-density independence. Results: Among three simulators, MMC achieves superior accuracy in SD and TD metrics, and shows robustness across all optical properties. NIRFASTer and Toast++ demonstrate comparable overall performance. In general, MMC is optimal for accuracy-critical TD-DOI applications, while NIRFASTer and Toast++ suit scenarios prioritizing speed with sufficiently large $μ_s'$. Besides, virtual source correction is essential for non-contact FEM modeling, which reduced average errors by > 34% in large-angle scenarios. Significance: This work provides benchmarked guidelines for simulator selection during the development phase of next-generation TD-DOI systems. Our work represents the first study to systematically validate TD simulators against SPAD array-based data under clinically relevant non-contact conditions, bridging a critical gap in biomedical optical simulation standards.
MedDCR: Learning to Design Agentic Workflows for Medical Coding
Nov 17, 2025Medical coding converts free-text clinical notes into standardized diagnostic and procedural codes, which are essential for billing, hospital operations, and medical research. Unlike ordinary text classification, it requires multi-step reasoning: extracting diagnostic concepts, applying guideline constraints, mapping to hierarchical codebooks, and ensuring cross-document consistency. Recent advances leverage agentic LLMs, but most rely on rigid, manually crafted workflows that fail to capture the nuance and variability of real-world documentation, leaving open the question of how to systematically learn effective workflows. We present MedDCR, a closed-loop framework that treats workflow design as a learning problem. A Designer proposes workflows, a Coder executes them, and a Reflector evaluates predictions and provides constructive feedback, while a memory archive preserves prior designs for reuse and iterative refinement. On benchmark datasets, MedDCR outperforms state-of-the-art baselines and produces interpretable, adaptable workflows that better reflect real coding practice, improving both the reliability and trustworthiness of automated systems.
Transporter: A 128$\times$4 SPAD Imager with On-chip Encoder for Spiking Neural Network-based Processing
Nov 07, 2025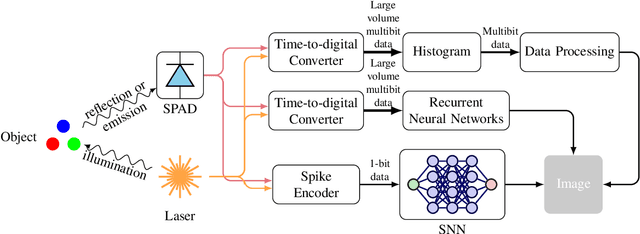
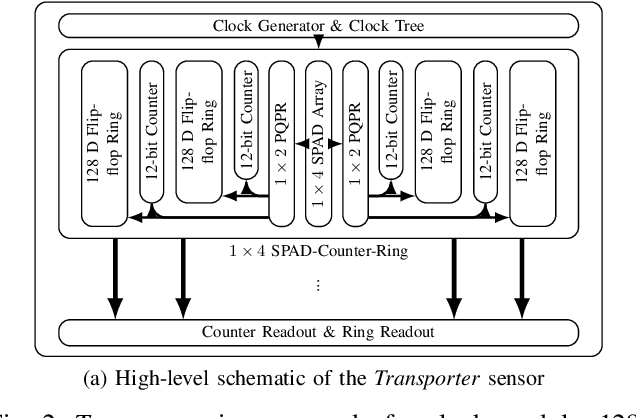
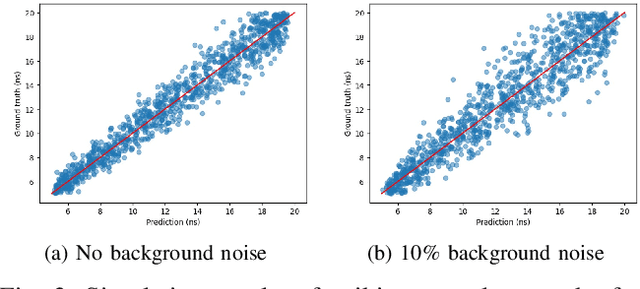
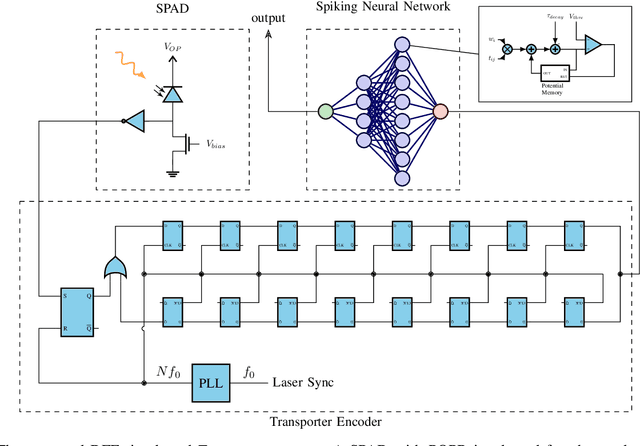
Single-photon avalanche diodes (SPADs) are widely used today in time-resolved imaging applications. However, traditional architectures rely on time-to-digital converters (TDCs) and histogram-based processing, leading to significant data transfer and processing challenges. Previous work based on recurrent neural networks has realized histogram-free processing. To further address these limitations, we propose a novel paradigm that eliminates TDCs by integrating in-sensor spike encoders. This approach enables preprocessing of photon arrival events in the sensor while significantly compressing data, reducing complexity, and maintaining real-time edge processing capabilities. A dedicated spike encoder folds multiple laser repetition periods, transforming phase-based spike trains into density-based spike trains optimized for spiking neural network processing and training via backpropagation through time. As a proof of concept, we introduce Transporter, a 128$\times$4 SPAD sensor with a per-pixel D flip-flop ring-based spike encoder, designed for intelligent active time-resolved imaging. This work demonstrates a path toward more efficient, neuromorphic SPAD imaging systems with reduced data overhead and enhanced real-time processing.
Speaker Anonymisation for Speech-based Suicide Risk Detection
Sep 26, 2025



Adolescent suicide is a critical global health issue, and speech provides a cost-effective modality for automatic suicide risk detection. Given the vulnerable population, protecting speaker identity is particularly important, as speech itself can reveal personally identifiable information if the data is leaked or maliciously exploited. This work presents the first systematic study of speaker anonymisation for speech-based suicide risk detection. A broad range of anonymisation methods are investigated, including techniques based on traditional signal processing, neural voice conversion, and speech synthesis. A comprehensive evaluation framework is built to assess the trade-off between protecting speaker identity and preserving information essential for suicide risk detection. Results show that combining anonymisation methods that retain complementary information yields detection performance comparable to that of original speech, while achieving protection of speaker identity for vulnerable populations.
Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
Jul 03, 2025Process Reinforcement Learning~(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models~(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5\% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.
LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models
Apr 03, 2025Natural Language to SQL (NL2SQL) has emerged as a critical task for enabling seamless interaction with databases. Recent advancements in Large Language Models (LLMs) have demonstrated remarkable performance in this domain. However, existing NL2SQL methods predominantly rely on closed-source LLMs leveraging prompt engineering, while open-source models typically require fine-tuning to acquire domain-specific knowledge. Despite these efforts, open-source LLMs struggle with complex NL2SQL tasks due to the indirect expression of user query objectives and the semantic gap between user queries and database schemas. Inspired by the application of reinforcement learning in mathematical problem-solving to encourage step-by-step reasoning in LLMs, we propose LearNAT (Learning NL2SQL with AST-guided Task Decomposition), a novel framework that improves the performance of open-source LLMs on complex NL2SQL tasks through task decomposition and reinforcement learning. LearNAT introduces three key components: (1) a Decomposition Synthesis Procedure that leverages Abstract Syntax Trees (ASTs) to guide efficient search and pruning strategies for task decomposition, (2) Margin-aware Reinforcement Learning, which employs fine-grained step-level optimization via DPO with AST margins, and (3) Adaptive Demonstration Reasoning, a mechanism for dynamically selecting relevant examples to enhance decomposition capabilities. Extensive experiments on two benchmark datasets, Spider and BIRD, demonstrate that LearNAT enables a 7B-parameter open-source LLM to achieve performance comparable to GPT-4, while offering improved efficiency and accessibility.
Multi-Scale Transformer Architecture for Accurate Medical Image Classification
Feb 10, 2025



This study introduces an AI-driven skin lesion classification algorithm built on an enhanced Transformer architecture, addressing the challenges of accuracy and robustness in medical image analysis. By integrating a multi-scale feature fusion mechanism and refining the self-attention process, the model effectively extracts both global and local features, enhancing its ability to detect lesions with ambiguous boundaries and intricate structures. Performance evaluation on the ISIC 2017 dataset demonstrates that the improved Transformer surpasses established AI models, including ResNet50, VGG19, ResNext, and Vision Transformer, across key metrics such as accuracy, AUC, F1-Score, and Precision. Grad-CAM visualizations further highlight the interpretability of the model, showcasing strong alignment between the algorithm's focus areas and actual lesion sites. This research underscores the transformative potential of advanced AI models in medical imaging, paving the way for more accurate and reliable diagnostic tools. Future work will explore the scalability of this approach to broader medical imaging tasks and investigate the integration of multimodal data to enhance AI-driven diagnostic frameworks for intelligent healthcare.
Quantifying Correlations of Machine Learning Models
Feb 06, 2025Machine Learning models are being extensively used in safety critical applications where errors from these models could cause harm to the user. Such risks are amplified when multiple machine learning models, which are deployed concurrently, interact and make errors simultaneously. This paper explores three scenarios where error correlations between multiple models arise, resulting in such aggregated risks. Using real-world data, we simulate these scenarios and quantify the correlations in errors of different models. Our findings indicate that aggregated risks are substantial, particularly when models share similar algorithms, training datasets, or foundational models. Overall, we observe that correlations across models are pervasive and likely to intensify with increased reliance on foundational models and widely used public datasets, highlighting the need for effective mitigation strategies to address these challenges.
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
Jan 24, 2025We introduce DRESS, a novel approach for generating stylized large language model (LLM) responses through representation editing. Existing methods like prompting and fine-tuning are either insufficient for complex style adaptation or computationally expensive, particularly in tasks like NPC creation or character role-playing. Our approach leverages the over-parameterized nature of LLMs to disentangle a style-relevant subspace within the model's representation space to conduct representation editing, ensuring a minimal impact on the original semantics. By applying adaptive editing strengths, we dynamically adjust the steering vectors in the style subspace to maintain both stylistic fidelity and semantic integrity. We develop two stylized QA benchmark datasets to validate the effectiveness of DRESS, and the results demonstrate significant improvements compared to baseline methods such as prompting and ITI. In short, DRESS is a lightweight, train-free solution for enhancing LLMs with flexible and effective style control, making it particularly useful for developing stylized conversational agents. Codes and benchmark datasets are available at https://github.com/ArthurLeoM/DRESS-LLM.