 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBifrostUMI: Bridging Robot-Free Demonstrations and Humanoid Whole-Body Manipulation
May 05, 2026High-quality data collection is a fundamental cornerstone for training humanoid whole-body visuomotor policies. Current data acquisition paradigms predominantly rely on robot teleoperation, which is often hindered by limited hardware accessibility and low operational efficiency. Inspired by the Universal Manipulation Interface (UMI), we propose BifrostUMI, a portable, efficient, and robot-free data collection framework tailored for humanoid robots. BifrostUMI leverages lightweight VR devices to capture human demonstrations as sparse keypoint trajectories while simultaneously recording wrist-mounted visual data. These multimodal data are subsequently utilized to train a high-level policy network that predicts future keypoint trajectories conditioned on the captured visual features. Through a robust keypoint retargeting pipeline, keypoint trajectories are precisely mapped onto the robot's morphology and executed via a whole-body controller. This approach enables the seamless transfer of diverse and agile behaviors from natural human demonstrations to humanoid embodiments. We demonstrate the efficacy and versatility of the proposed framework across two distinct experimental scenarios.
OmniUMI: Towards Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction
Apr 12, 2026UMI-style interfaces enable scalable robot learning, but existing systems remain largely visuomotor, relying primarily on RGB observations and trajectory while providing only limited access to physical interaction signals. This becomes a fundamental limitation in contact-rich manipulation, where success depends on contact dynamics such as tactile interaction, internal grasping force, and external interaction wrench that are difficult to infer from vision alone. We present OmniUMI, a unified framework for physically grounded robot learning via human-aligned multimodal interaction. OmniUMI synchronously captures RGB, depth, trajectory, tactile sensing, internal grasping force, and external interaction wrench within a compact handheld system, while maintaining collection--deployment consistency through a shared embodiment design. To support human-aligned demonstration, OmniUMI provides dual-force feedback through bilateral gripper feedback and natural perception of external interaction wrench in the handheld embodiment. Built on this interface, we extend diffusion policy with visual, tactile, and force-related observations, and deploy the learned policy through impedance-based execution for unified regulation of motion and contact behavior. Experiments demonstrate reliable sensing and strong downstream performance on force-sensitive pick-and-place, interactive surface erasing, and tactile-informed selective release. Overall, OmniUMI combines physically grounded multimodal data acquisition with human-aligned interaction, providing a scalable foundation for learning contact-rich manipulation.
MOGeo: Beyond One-to-One Cross-View Object Geo-localization
Mar 14, 2026Cross-View Object Geo-Localization (CVOGL) aims to locate an object of interest in a query image within a corresponding satellite image. Existing methods typically assume that the query image contains only a single object, which does not align with the complex, multi-object geo-localization requirements in real-world applications, making them unsuitable for practical scenarios. To bridge the gap between the realistic setting and existing task, we propose a new task, called Cross-View Multi-Object Geo-Localization (CVMOGL). To advance the CVMOGL task, we first construct a benchmark, CMLocation, which includes two datasets: CMLocation-V1 and CMLocation-V2. Furthermore, we propose a novel cross-view multi-object geo-localization method, MOGeo, and benchmark it against existing state-of-the-art methods. Extensive experiments are conducted under various application scenarios to validate the effectiveness of our method. The results demonstrate that cross-view object geo-localization in the more realistic setting remains a challenging problem, encouraging further research in this area.
Copyright Infringement Risk Reduction via Chain-of-Thought and Task Instruction Prompting
Dec 17, 2025Large scale text-to-image generation models can memorize and reproduce their training dataset. Since the training dataset often contains copyrighted material, reproduction of training dataset poses a copyright infringement risk, which could result in legal liabilities and financial losses for both the AI user and the developer. The current works explores the potential of chain-of-thought and task instruction prompting in reducing copyrighted content generation. To this end, we present a formulation that combines these two techniques with two other copyright mitigation strategies: a) negative prompting, and b) prompt re-writing. We study the generated images in terms their similarity to a copyrighted image and their relevance of the user input. We present numerical experiments on a variety of models and provide insights on the effectiveness of the aforementioned techniques for varying model complexity.
Safer Prompts: Reducing IP Risk in Visual Generative AI
May 06, 2025Visual Generative AI models have demonstrated remarkable capability in generating high-quality images from simple inputs like text prompts. However, because these models are trained on images from diverse sources, they risk memorizing and reproducing specific content, raising concerns about intellectual property (IP) infringement. Recent advances in prompt engineering offer a cost-effective way to enhance generative AI performance. In this paper, we evaluate the effectiveness of prompt engineering techniques in mitigating IP infringement risks in image generation. Our findings show that Chain of Thought Prompting and Task Instruction Prompting significantly reduce the similarity between generated images and the training data of diffusion models, thereby lowering the risk of IP infringement.
Quantifying Correlations of Machine Learning Models
Feb 06, 2025Machine Learning models are being extensively used in safety critical applications where errors from these models could cause harm to the user. Such risks are amplified when multiple machine learning models, which are deployed concurrently, interact and make errors simultaneously. This paper explores three scenarios where error correlations between multiple models arise, resulting in such aggregated risks. Using real-world data, we simulate these scenarios and quantify the correlations in errors of different models. Our findings indicate that aggregated risks are substantial, particularly when models share similar algorithms, training datasets, or foundational models. Overall, we observe that correlations across models are pervasive and likely to intensify with increased reliance on foundational models and widely used public datasets, highlighting the need for effective mitigation strategies to address these challenges.
An In-Depth Examination of Risk Assessment in Multi-Class Classification Algorithms
Dec 05, 2024



Advanced classification algorithms are being increasingly used in safety-critical applications like health-care, engineering, etc. In such applications, miss-classifications made by ML algorithms can result in substantial financial or health-related losses. To better anticipate and prepare for such losses, the algorithm user seeks an estimate for the probability that the algorithm miss-classifies a sample. We refer to this task as the risk-assessment. For a variety of models and datasets, we numerically analyze the performance of different methods in solving the risk-assessment problem. We consider two solution strategies: a) calibration techniques that calibrate the output probabilities of classification models to provide accurate probability outputs; and b) a novel approach based upon the prediction interval generation technique of conformal prediction. Our conformal prediction based approach is model and data-distribution agnostic, simple to implement, and provides reasonable results for a variety of use-cases. We compare the different methods on a broad variety of models and datasets.
The sampling complexity of learning invertible residual neural networks
Nov 08, 2024In recent work it has been shown that determining a feedforward ReLU neural network to within high uniform accuracy from point samples suffers from the curse of dimensionality in terms of the number of samples needed. As a consequence, feedforward ReLU neural networks are of limited use for applications where guaranteed high uniform accuracy is required. We consider the question of whether the sampling complexity can be improved by restricting the specific neural network architecture. To this end, we investigate invertible residual neural networks which are foundational architectures in deep learning and are widely employed in models that power modern generative methods. Our main result shows that the residual neural network architecture and invertibility do not help overcome the complexity barriers encountered with simpler feedforward architectures. Specifically, we demonstrate that the computational complexity of approximating invertible residual neural networks from point samples in the uniform norm suffers from the curse of dimensionality. Similar results are established for invertible convolutional Residual neural networks.
Distribution-free risk assessment of regression-based machine learning algorithms
Oct 05, 2023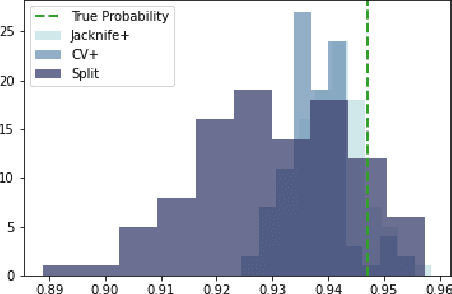
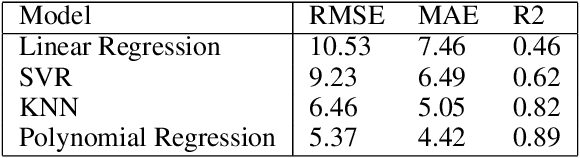
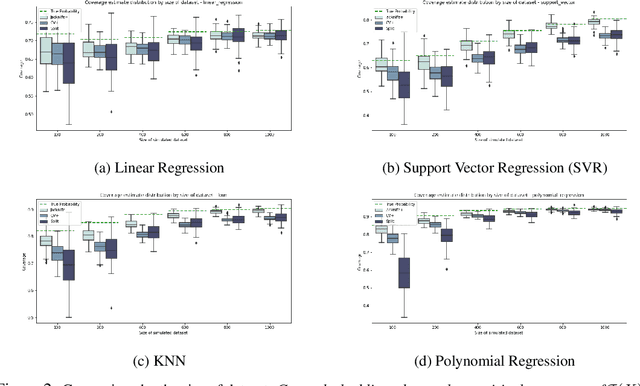
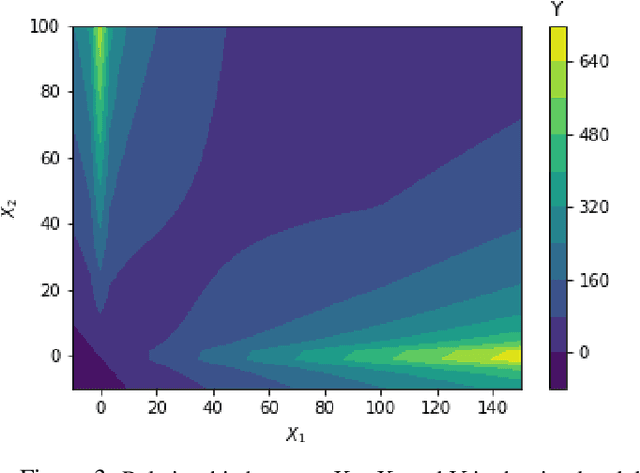
Machine learning algorithms have grown in sophistication over the years and are increasingly deployed for real-life applications. However, when using machine learning techniques in practical settings, particularly in high-risk applications such as medicine and engineering, obtaining the failure probability of the predictive model is critical. We refer to this problem as the risk-assessment task. We focus on regression algorithms and the risk-assessment task of computing the probability of the true label lying inside an interval defined around the model's prediction. We solve the risk-assessment problem using the conformal prediction approach, which provides prediction intervals that are guaranteed to contain the true label with a given probability. Using this coverage property, we prove that our approximated failure probability is conservative in the sense that it is not lower than the true failure probability of the ML algorithm. We conduct extensive experiments to empirically study the accuracy of the proposed method for problems with and without covariate shift. Our analysis focuses on different modeling regimes, dataset sizes, and conformal prediction methodologies.
Model-agnostic network inference enhancement from noisy measurements via curriculum learning
Sep 05, 2023Noise is a pervasive element within real-world measurement data, significantly undermining the performance of network inference models. However, the quest for a comprehensive enhancement framework capable of bolstering noise resistance across a diverse array of network inference models has remained elusive. Here, we present an elegant and efficient framework tailored to amplify the capabilities of network inference models in the presence of noise. Leveraging curriculum learning, we mitigate the deleterious impact of noisy samples on network inference models. Our proposed framework is model-agnostic, seamlessly integrable into a plethora of model-based and model-free network inference methods. Notably, we utilize one model-based and three model-free network inference methods as the foundation. Extensive experimentation across various synthetic and real-world networks, encapsulating diverse nonlinear dynamic processes, showcases substantial performance augmentation under varied noise types, particularly thriving in scenarios enriched with clean samples. This framework's adeptness in fortifying both model-free and model-based network inference methodologies paves the avenue towards a comprehensive and unified enhancement framework, encompassing the entire spectrum of network inference models. Available Code: https://github.com/xiaoyuans/MANIE.