 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Uncertainty Estimation Methods in Large Language Models
Oct 23, 2025Large language models (LLMs) produce outputs with varying levels of uncertainty, and, just as often, varying levels of correctness; making their practical reliability far from guaranteed. To quantify this uncertainty, we systematically evaluate four approaches for confidence estimation in LLM outputs: VCE, MSP, Sample Consistency, and CoCoA (Vashurin et al., 2025). For the evaluation of the approaches, we conduct experiments on four question-answering tasks using a state-of-the-art open-source LLM. Our results show that each uncertainty metric captures a different facet of model confidence and that the hybrid CoCoA approach yields the best reliability overall, improving both calibration and discrimination of correct answers. We discuss the trade-offs of each method and provide recommendations for selecting uncertainty measures in LLM applications.
AIn't Nothing But a Survey? Using Large Language Models for Coding German Open-Ended Survey Responses on Survey Motivation
Jun 18, 2025The recent development and wider accessibility of LLMs have spurred discussions about how they can be used in survey research, including classifying open-ended survey responses. Due to their linguistic capacities, it is possible that LLMs are an efficient alternative to time-consuming manual coding and the pre-training of supervised machine learning models. As most existing research on this topic has focused on English-language responses relating to non-complex topics or on single LLMs, it is unclear whether its findings generalize and how the quality of these classifications compares to established methods. In this study, we investigate to what extent different LLMs can be used to code open-ended survey responses in other contexts, using German data on reasons for survey participation as an example. We compare several state-of-the-art LLMs and several prompting approaches, and evaluate the LLMs' performance by using human expert codings. Overall performance differs greatly between LLMs, and only a fine-tuned LLM achieves satisfactory levels of predictive performance. Performance differences between prompting approaches are conditional on the LLM used. Finally, LLMs' unequal classification performance across different categories of reasons for survey participation results in different categorical distributions when not using fine-tuning. We discuss the implications of these findings, both for methodological research on coding open-ended responses and for their substantive analysis, and for practitioners processing or substantively analyzing such data. Finally, we highlight the many trade-offs researchers need to consider when choosing automated methods for open-ended response classification in the age of LLMs. In doing so, our study contributes to the growing body of research about the conditions under which LLMs can be efficiently, accurately, and reliably leveraged in survey research.
Safer Prompts: Reducing IP Risk in Visual Generative AI
May 06, 2025Visual Generative AI models have demonstrated remarkable capability in generating high-quality images from simple inputs like text prompts. However, because these models are trained on images from diverse sources, they risk memorizing and reproducing specific content, raising concerns about intellectual property (IP) infringement. Recent advances in prompt engineering offer a cost-effective way to enhance generative AI performance. In this paper, we evaluate the effectiveness of prompt engineering techniques in mitigating IP infringement risks in image generation. Our findings show that Chain of Thought Prompting and Task Instruction Prompting significantly reduce the similarity between generated images and the training data of diffusion models, thereby lowering the risk of IP infringement.
"It Listens Better Than My Therapist": Exploring Social Media Discourse on LLMs as Mental Health Tool
Apr 14, 2025The emergence of generative AI chatbots such as ChatGPT has prompted growing public and academic interest in their role as informal mental health support tools. While early rule-based systems have been around for several years, large language models (LLMs) offer new capabilities in conversational fluency, empathy simulation, and availability. This study explores how users engage with LLMs as mental health tools by analyzing over 10,000 TikTok comments from videos referencing LLMs as mental health tools. Using a self-developed tiered coding schema and supervised classification models, we identify user experiences, attitudes, and recurring themes. Results show that nearly 20% of comments reflect personal use, with these users expressing overwhelmingly positive attitudes. Commonly cited benefits include accessibility, emotional support, and perceived therapeutic value. However, concerns around privacy, generic responses, and the lack of professional oversight remain prominent. It is important to note that the user feedback does not indicate which therapeutic framework, if any, the LLM-generated output aligns with. While the findings underscore the growing relevance of AI in everyday practices, they also highlight the urgent need for clinical and ethical scrutiny in the use of AI for mental health support.
Algorithmic Fidelity of Large Language Models in Generating Synthetic German Public Opinions: A Case Study
Dec 17, 2024In recent research, large language models (LLMs) have been increasingly used to investigate public opinions. This study investigates the algorithmic fidelity of LLMs, i.e., the ability to replicate the socio-cultural context and nuanced opinions of human participants. Using open-ended survey data from the German Longitudinal Election Studies (GLES), we prompt different LLMs to generate synthetic public opinions reflective of German subpopulations by incorporating demographic features into the persona prompts. Our results show that Llama performs better than other LLMs at representing subpopulations, particularly when there is lower opinion diversity within those groups. Our findings further reveal that the LLM performs better for supporters of left-leaning parties like The Greens and The Left compared to other parties, and matches the least with the right-party AfD. Additionally, the inclusion or exclusion of specific variables in the prompts can significantly impact the models' predictions. These findings underscore the importance of aligning LLMs to more effectively model diverse public opinions while minimizing political biases and enhancing robustness in representativeness.
Vox Populi, Vox AI? Using Language Models to Estimate German Public Opinion
Jul 11, 2024


The recent development of large language models (LLMs) has spurred discussions about whether LLM-generated "synthetic samples" could complement or replace traditional surveys, considering their training data potentially reflects attitudes and behaviors prevalent in the population. A number of mostly US-based studies have prompted LLMs to mimic survey respondents, with some of them finding that the responses closely match the survey data. However, several contextual factors related to the relationship between the respective target population and LLM training data might affect the generalizability of such findings. In this study, we investigate the extent to which LLMs can estimate public opinion in Germany, using the example of vote choice. We generate a synthetic sample of personas matching the individual characteristics of the 2017 German Longitudinal Election Study respondents. We ask the LLM GPT-3.5 to predict each respondent's vote choice and compare these predictions to the survey-based estimates on the aggregate and subgroup levels. We find that GPT-3.5 does not predict citizens' vote choice accurately, exhibiting a bias towards the Green and Left parties. While the LLM captures the tendencies of "typical" voter subgroups, such as partisans, it misses the multifaceted factors swaying individual voter choices. By examining the LLM-based prediction of voting behavior in a new context, our study contributes to the growing body of research about the conditions under which LLMs can be leveraged for studying public opinion. The findings point to disparities in opinion representation in LLMs and underscore the limitations in applying them for public opinion estimation.
The Potential and Challenges of Evaluating Attitudes, Opinions, and Values in Large Language Models
Jun 16, 2024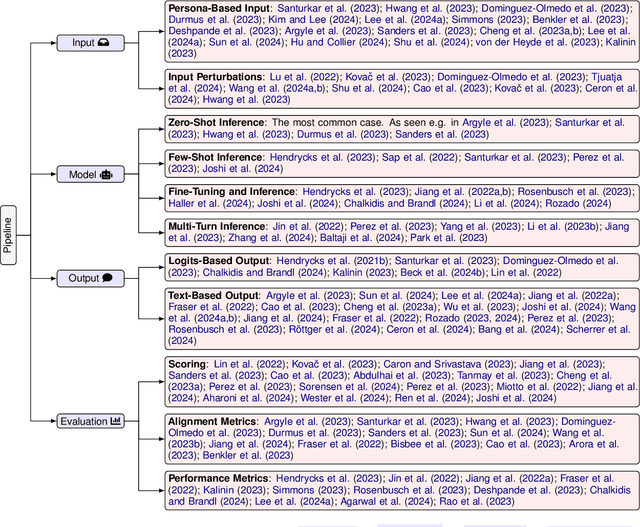
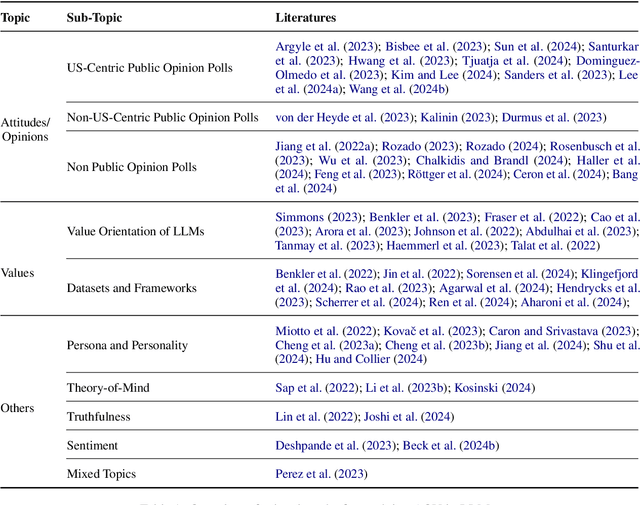
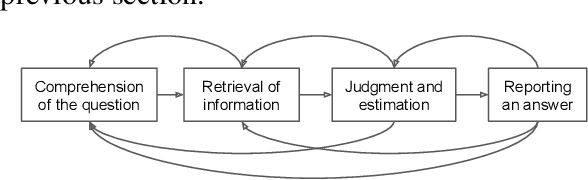
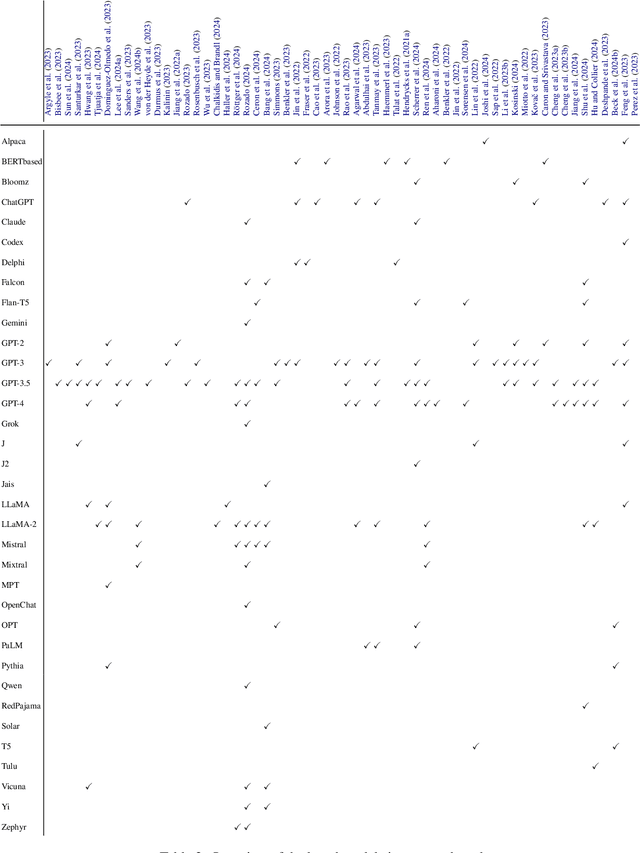
Recent advances in Large Language Models (LLMs) have sparked wide interest in validating and comprehending the human-like cognitive-behavioral traits LLMs may have. These cognitive-behavioral traits include typically Attitudes, Opinions, Values (AOV). However, measuring AOV embedded within LLMs remains opaque, and different evaluation methods may yield different results. This has led to a lack of clarity on how different studies are related to each other and how they can be interpreted. This paper aims to bridge this gap by providing an overview of recent works on the evaluation of AOV in LLMs. Moreover, we survey related approaches in different stages of the evaluation pipeline in these works. By doing so, we address the potential and challenges with respect to understanding the model, human-AI alignment, and downstream application in social sciences. Finally, we provide practical insights into evaluation methods, model enhancement, and interdisciplinary collaboration, thereby contributing to the evolving landscape of evaluating AOV in LLMs.
Seeing ChatGPT Through Students' Eyes: An Analysis of TikTok Data
Mar 09, 2023


Advanced large language models like ChatGPT have gained considerable attention recently, including among students. However, while the debate on ChatGPT in academia is making waves, more understanding is needed among lecturers and teachers on how students use and perceive ChatGPT. To address this gap, we analyzed the content on ChatGPT available on TikTok in February 2023. TikTok is a rapidly growing social media platform popular among individuals under 30. Specifically, we analyzed the content of the 100 most popular videos in English tagged with #chatgpt, which collectively garnered over 250 million views. Most of the videos we studied promoted the use of ChatGPT for tasks like writing essays or code. In addition, many videos discussed AI detectors, with a focus on how other tools can help to transform ChatGPT output to fool these detectors. This also mirrors the discussion among educators on how to treat ChatGPT as lecturers and teachers in teaching and grading. What is, however, missing from the analyzed clips on TikTok are videos that discuss ChatGPT producing content that is nonsensical or unfaithful to the training data.