 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impossibility of Separating Intelligence from Judgment: The Computational Intractability of Filtering for AI Alignment
Jul 09, 2025With the increased deployment of large language models (LLMs), one concern is their potential misuse for generating harmful content. Our work studies the alignment challenge, with a focus on filters to prevent the generation of unsafe information. Two natural points of intervention are the filtering of the input prompt before it reaches the model, and filtering the output after generation. Our main results demonstrate computational challenges in filtering both prompts and outputs. First, we show that there exist LLMs for which there are no efficient prompt filters: adversarial prompts that elicit harmful behavior can be easily constructed, which are computationally indistinguishable from benign prompts for any efficient filter. Our second main result identifies a natural setting in which output filtering is computationally intractable. All of our separation results are under cryptographic hardness assumptions. In addition to these core findings, we also formalize and study relaxed mitigation approaches, demonstrating further computational barriers. We conclude that safety cannot be achieved by designing filters external to the LLM internals (architecture and weights); in particular, black-box access to the LLM will not suffice. Based on our technical results, we argue that an aligned AI system's intelligence cannot be separated from its judgment.
Human Preferences in Large Language Model Latent Space: A Technical Analysis on the Reliability of Synthetic Data in Voting Outcome Prediction
Feb 22, 2025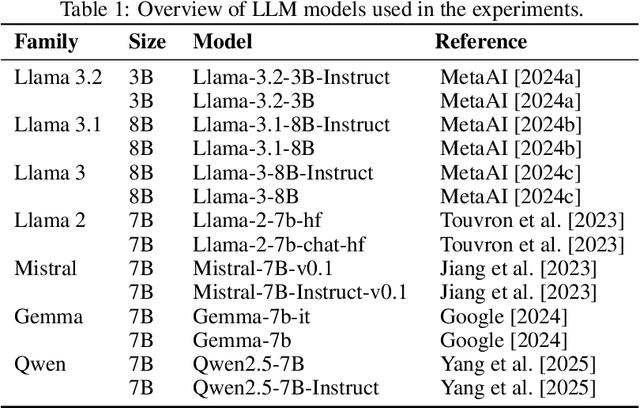
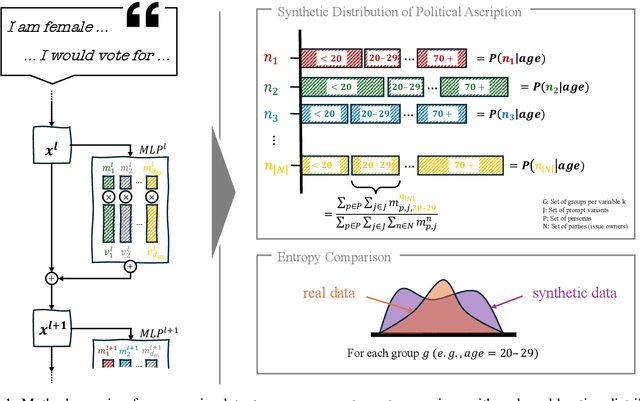
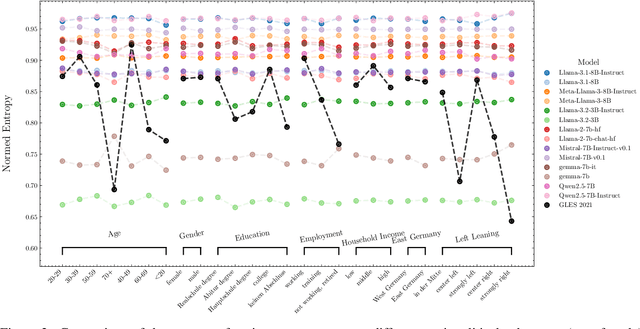
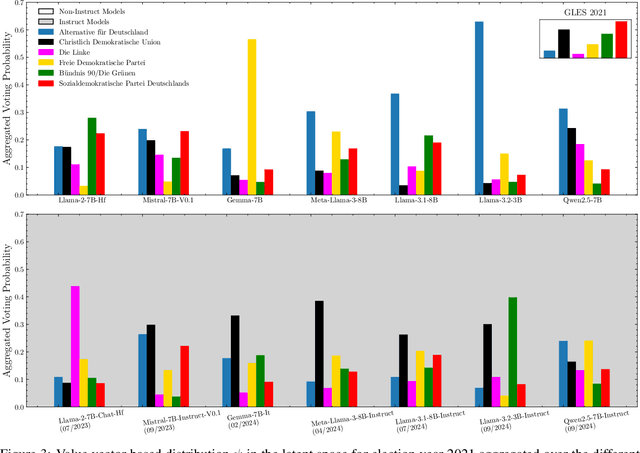
Generative AI (GenAI) is increasingly used in survey contexts to simulate human preferences. While many research endeavors evaluate the quality of synthetic GenAI data by comparing model-generated responses to gold-standard survey results, fundamental questions about the validity and reliability of using LLMs as substitutes for human respondents remain. Our study provides a technical analysis of how demographic attributes and prompt variations influence latent opinion mappings in large language models (LLMs) and evaluates their suitability for survey-based predictions. Using 14 different models, we find that LLM-generated data fails to replicate the variance observed in real-world human responses, particularly across demographic subgroups. In the political space, persona-to-party mappings exhibit limited differentiation, resulting in synthetic data that lacks the nuanced distribution of opinions found in survey data. Moreover, we show that prompt sensitivity can significantly alter outputs for some models, further undermining the stability and predictiveness of LLM-based simulations. As a key contribution, we adapt a probe-based methodology that reveals how LLMs encode political affiliations in their latent space, exposing the systematic distortions introduced by these models. Our findings highlight critical limitations in AI-generated survey data, urging caution in its use for public opinion research, social science experimentation, and computational behavioral modeling.
Understanding Jailbreak Success: A Study of Latent Space Dynamics in Large Language Models
Jun 13, 2024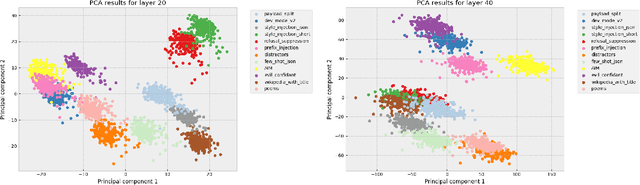
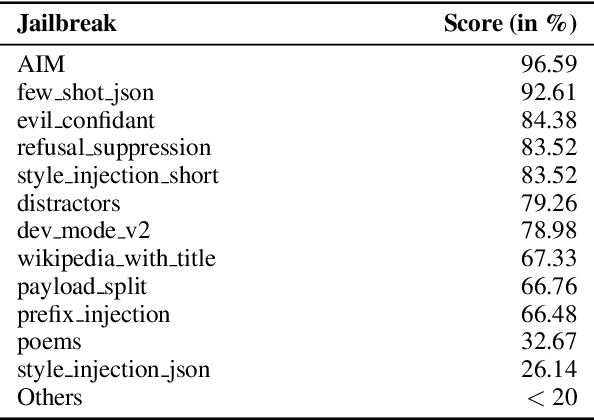
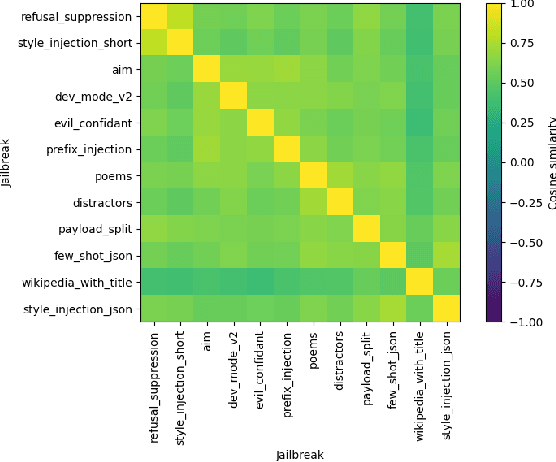
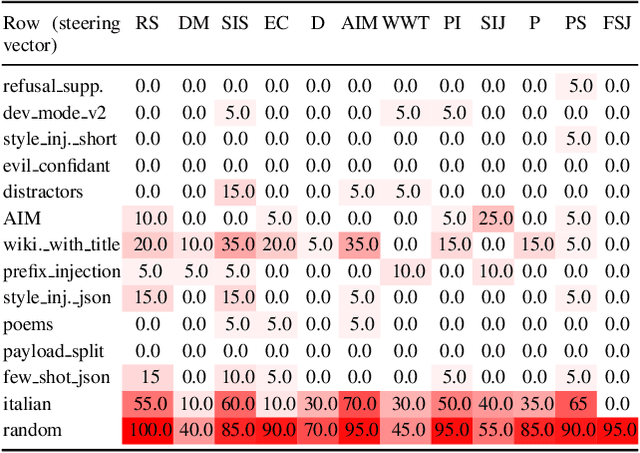
Conversational Large Language Models are trained to refuse to answer harmful questions. However, emergent jailbreaking techniques can still elicit unsafe outputs, presenting an ongoing challenge for model alignment. To better understand how different jailbreak types circumvent safeguards, this paper analyses model activations on different jailbreak inputs. We find that it is possible to extract a jailbreak vector from a single class of jailbreaks that works to mitigate jailbreak effectiveness from other classes. This may indicate that different kinds of effective jailbreaks operate via similar internal mechanisms. We investigate a potential common mechanism of harmfulness feature suppression, and provide evidence for its existence by looking at the harmfulness vector component. These findings offer actionable insights for developing more robust jailbreak countermeasures and lay the groundwork for a deeper, mechanistic understanding of jailbreak dynamics in language models.
Seeing ChatGPT Through Students' Eyes: An Analysis of TikTok Data
Mar 09, 2023


Advanced large language models like ChatGPT have gained considerable attention recently, including among students. However, while the debate on ChatGPT in academia is making waves, more understanding is needed among lecturers and teachers on how students use and perceive ChatGPT. To address this gap, we analyzed the content on ChatGPT available on TikTok in February 2023. TikTok is a rapidly growing social media platform popular among individuals under 30. Specifically, we analyzed the content of the 100 most popular videos in English tagged with #chatgpt, which collectively garnered over 250 million views. Most of the videos we studied promoted the use of ChatGPT for tasks like writing essays or code. In addition, many videos discussed AI detectors, with a focus on how other tools can help to transform ChatGPT output to fool these detectors. This also mirrors the discussion among educators on how to treat ChatGPT as lecturers and teachers in teaching and grading. What is, however, missing from the analyzed clips on TikTok are videos that discuss ChatGPT producing content that is nonsensical or unfaithful to the training data.