 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Preferences in Large Language Model Latent Space: A Technical Analysis on the Reliability of Synthetic Data in Voting Outcome Prediction
Paper and Code
Feb 22, 2025
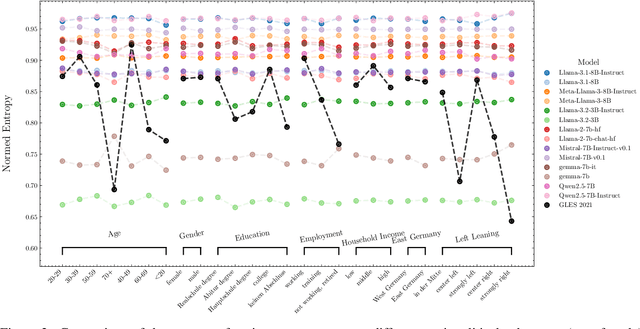
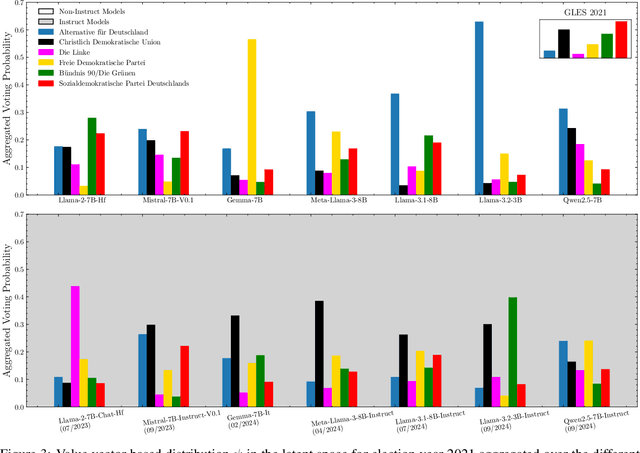
Generative AI (GenAI) is increasingly used in survey contexts to simulate human preferences. While many research endeavors evaluate the quality of synthetic GenAI data by comparing model-generated responses to gold-standard survey results, fundamental questions about the validity and reliability of using LLMs as substitutes for human respondents remain. Our study provides a technical analysis of how demographic attributes and prompt variations influence latent opinion mappings in large language models (LLMs) and evaluates their suitability for survey-based predictions. Using 14 different models, we find that LLM-generated data fails to replicate the variance observed in real-world human responses, particularly across demographic subgroups. In the political space, persona-to-party mappings exhibit limited differentiation, resulting in synthetic data that lacks the nuanced distribution of opinions found in survey data. Moreover, we show that prompt sensitivity can significantly alter outputs for some models, further undermining the stability and predictiveness of LLM-based simulations. As a key contribution, we adapt a probe-based methodology that reveals how LLMs encode political affiliations in their latent space, exposing the systematic distortions introduced by these models. Our findings highlight critical limitations in AI-generated survey data, urging caution in its use for public opinion research, social science experimentation, and computational behavioral modeling.