 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reach to Insert: Tactile-Augmented Precision Assembly under Sub-Millimeter Tolerances
May 06, 2026High-precision assembly frequently involves tight-tolerance insertions, where even slight pose errors can cause jamming or excessive interaction forces, making robust and safe insertion policies difficult to obtain. This paper proposes a tactile-augmented two-stage method that combines Imitation Learning (IL) and Reinforcement Learning (RL) for precision insertion tasks. In the first stage, IL learns a reaching policy with position generalization that grasps the peg and brings it to the vicinity of the target region. In the second stage, RL executes the insertion and enables recovery from failures during contact-rich interactions. To better exploit tactile feedback, we introduce tactile group sampling to increase coverage of critical contact segments during training, and design a tactile critic to more accurately evaluate policy values, improving insertion performance while maintaining low contact forces. We conduct systematic experiments across five hole geometries and three clearance settings. Results show that our method substantially improves insertion performance across all settings; under the most challenging 0.05\,mm clearance, it achieves a 67\% success rate while keeping contact forces low, reducing the maximum interaction force by 60\% and torque by 44\%, thereby validating both effectiveness and safety for precision assembly.
Solar-VLM: Multimodal Vision-Language Models for Augmented Solar Power Forecasting
Apr 05, 2026Photovoltaic (PV) power forecasting plays a critical role in power system dispatch and market participation. Because PV generation is highly sensitive to weather conditions and cloud motion, accurate forecasting requires effective modeling of complex spatiotemporal dependencies across multiple information sources. Although recent studies have advanced AI-based forecasting methods, most fail to fuse temporal observations, satellite imagery, and textual weather information in a unified framework. This paper proposes Solar-VLM, a large-language-model-driven framework for multimodal PV power forecasting. First, modality-specific encoders are developed to extract complementary features from heterogeneous inputs. The time-series encoder adopts a patch-based design to capture temporal patterns from multivariate observations at each site. The visual encoder, built upon a Qwen-based vision backbone, extracts cloud-cover information from satellite images. The text encoder distills historical weather characteristics from textual descriptions. Second, to capture spatial dependencies across geographically distributed PV stations, a cross-site feature fusion mechanism is introduced. Specifically, a Graph Learner models inter-station correlations through a graph attention network constructed over a K-nearest-neighbor (KNN) graph, while a cross-site attention module further facilitates adaptive information exchange among sites. Finally, experiments conducted on data from eight PV stations in a northern province of China demonstrate the effectiveness of the proposed framework. Our proposed model is publicly available at https://github.com/rhp413/Solar-VLM.
Towards Automated Community Notes Generation with Large Vision Language Models for Combating Contextual Deception
Mar 23, 2026Community Notes have emerged as an effective crowd-sourced mechanism for combating online deception on social media platforms. However, its reliance on human contributors limits both the timeliness and scalability. In this work, we study the automated Community Notes generation method for image-based contextual deception, where an authentic image is paired with misleading context (e.g., time, entity, and event). Unlike prior work that primarily focuses on deception detection (i.e., judging whether a post is true or false in a binary manner), Community Notes-style systems need to generate concise and grounded notes that help users recover the missing or corrected context. This problem remains underexplored due to three reasons: (i) datasets that support the research are scarce; (ii) methods must handle the dynamic nature of contextual deception; (iii) evaluation is difficult because standard metrics do not capture whether notes actually improve user understanding. To address these gaps, we curate a real-world dataset, XCheck, comprising X posts with associated Community Notes and external contexts. We further propose the Automated Context-Corrective Note generation method, named ACCNote, which is a retrieval-augmented, multi-agent collaboration framework built on large vision-language models. Finally, we introduce a new evaluation metric, Context Helpfulness Score (CHS), that aligns with user study outcomes rather than relying on lexical overlap. Experiments on our XCheck dataset show that the proposed ACCNote improves both deception detection and note generation performance over baselines, and exceeds a commercial tool GPT5-mini. Together, our dataset, method, and metric advance practical automated generation of context-corrective notes toward more responsible online social networks.
Comparative Analysis of Patch Attack on VLM-Based Autonomous Driving Architectures
Mar 09, 2026Vision-language models are emerging for autonomous driving, yet their robustness to physical adversarial attacks remains unexplored. This paper presents a systematic framework for comparative adversarial evaluation across three VLM architectures: Dolphins, OmniDrive (Omni-L), and LeapVAD. Using black-box optimization with semantic homogenization for fair comparison, we evaluate physically realizable patch attacks in CARLA simulation. Results reveal severe vulnerabilities across all architectures, sustained multi-frame failures, and critical object detection degradation. Our analysis exposes distinct architectural vulnerability patterns, demonstrating that current VLM designs inadequately address adversarial threats in safety-critical autonomous driving applications.
DisPatch: Disarming Adversarial Patches in Object Detection with Diffusion Models
Sep 04, 2025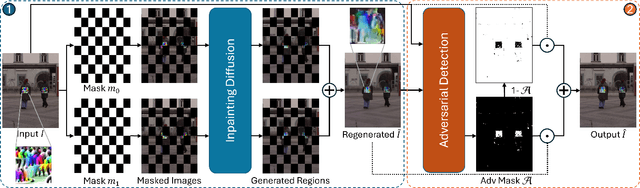
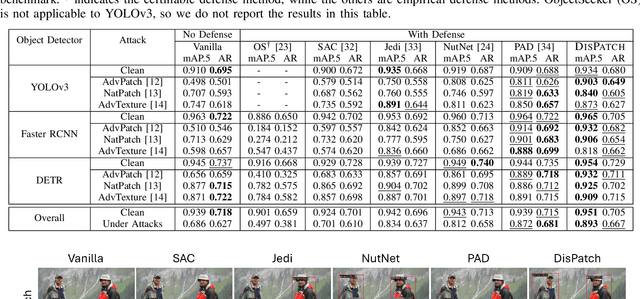
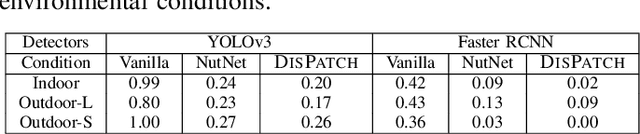
Object detection is fundamental to various real-world applications, such as security monitoring and surveillance video analysis. Despite their advancements, state-of-theart object detectors are still vulnerable to adversarial patch attacks, which can be easily applied to real-world objects to either conceal actual items or create non-existent ones, leading to severe consequences. Given the current diversity of adversarial patch attacks and potential unknown threats, an ideal defense method should be effective, generalizable, and robust against adaptive attacks. In this work, we introduce DISPATCH, the first diffusion-based defense framework for object detection. Unlike previous works that aim to "detect and remove" adversarial patches, DISPATCH adopts a "regenerate and rectify" strategy, leveraging generative models to disarm attack effects while preserving the integrity of the input image. Specifically, we utilize the in-distribution generative power of diffusion models to regenerate the entire image, aligning it with benign data. A rectification process is then employed to identify and replace adversarial regions with their regenerated benign counterparts. DISPATCH is attack-agnostic and requires no prior knowledge of the existing patches. Extensive experiments across multiple detectors and attacks demonstrate that DISPATCH consistently outperforms state-of-the-art defenses on both hiding attacks and creating attacks, achieving the best overall mAP.5 score of 89.3% on hiding attacks, and lowering the attack success rate to 24.8% on untargeted creating attacks. Moreover, it maintains strong robustness against adaptive attacks, making it a practical and reliable defense for object detection systems.
Boosting Action-Information via a Variational Bottleneck on Unlabelled Robot Videos
Aug 12, 2025Learning from demonstrations (LfD) typically relies on large amounts of action-labeled expert trajectories, which fundamentally constrains the scale of available training data. A promising alternative is to learn directly from unlabeled video demonstrations. However, we find that existing methods tend to encode latent actions that share little mutual information with the true robot actions, leading to suboptimal control performance. To address this limitation, we introduce a novel framework that explicitly maximizes the mutual information between latent actions and true actions, even in the absence of action labels. Our method leverage the variational information-bottleneck to extract action-relevant representations while discarding task-irrelevant information. We provide a theoretical analysis showing that our objective indeed maximizes the mutual information between latent and true actions. Finally, we validate our approach through extensive experiments: first in simulated robotic environments and then on real-world robotic platforms, the experimental results demonstrate that our method significantly enhances mutual information and consistently improves policy performance.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Adversarial Testing in LLMs: Insights into Decision-Making Vulnerabilities
May 19, 2025As Large Language Models (LLMs) become increasingly integrated into real-world decision-making systems, understanding their behavioural vulnerabilities remains a critical challenge for AI safety and alignment. While existing evaluation metrics focus primarily on reasoning accuracy or factual correctness, they often overlook whether LLMs are robust to adversarial manipulation or capable of using adaptive strategy in dynamic environments. This paper introduces an adversarial evaluation framework designed to systematically stress-test the decision-making processes of LLMs under interactive and adversarial conditions. Drawing on methodologies from cognitive psychology and game theory, our framework probes how models respond in two canonical tasks: the two-armed bandit task and the Multi-Round Trust Task. These tasks capture key aspects of exploration-exploitation trade-offs, social cooperation, and strategic flexibility. We apply this framework to several state-of-the-art LLMs, including GPT-3.5, GPT-4, Gemini-1.5, and DeepSeek-V3, revealing model-specific susceptibilities to manipulation and rigidity in strategy adaptation. Our findings highlight distinct behavioral patterns across models and emphasize the importance of adaptability and fairness recognition for trustworthy AI deployment. Rather than offering a performance benchmark, this work proposes a methodology for diagnosing decision-making weaknesses in LLM-based agents, providing actionable insights for alignment and safety research.
PointArena: Probing Multimodal Grounding Through Language-Guided Pointing
May 15, 2025Pointing serves as a fundamental and intuitive mechanism for grounding language within visual contexts, with applications spanning robotics, assistive technologies, and interactive AI systems. While recent multimodal models have started to support pointing capabilities, existing benchmarks typically focus only on referential object localization tasks. We introduce PointArena, a comprehensive platform for evaluating multimodal pointing across diverse reasoning scenarios. PointArena comprises three components: (1) Point-Bench, a curated dataset containing approximately 1,000 pointing tasks across five reasoning categories; (2) Point-Battle, an interactive, web-based arena facilitating blind, pairwise model comparisons, which has already gathered over 4,500 anonymized votes; and (3) Point-Act, a real-world robotic manipulation system allowing users to directly evaluate multimodal model pointing capabilities in practical settings. We conducted extensive evaluations of both state-of-the-art open-source and proprietary multimodal models. Results indicate that Molmo-72B consistently outperforms other models, though proprietary models increasingly demonstrate comparable performance. Additionally, we find that supervised training specifically targeting pointing tasks significantly enhances model performance. Across our multi-stage evaluation pipeline, we also observe strong correlations, underscoring the critical role of precise pointing capabilities in enabling multimodal models to effectively bridge abstract reasoning with concrete, real-world actions. Project page: https://pointarena.github.io/
Graph Based Deep Reinforcement Learning Aided by Transformers for Multi-Agent Cooperation
Apr 11, 2025Mission planning for a fleet of cooperative autonomous drones in applications that involve serving distributed target points, such as disaster response, environmental monitoring, and surveillance, is challenging, especially under partial observability, limited communication range, and uncertain environments. Traditional path-planning algorithms struggle in these scenarios, particularly when prior information is not available. To address these challenges, we propose a novel framework that integrates Graph Neural Networks (GNNs), Deep Reinforcement Learning (DRL), and transformer-based mechanisms for enhanced multi-agent coordination and collective task execution. Our approach leverages GNNs to model agent-agent and agent-goal interactions through adaptive graph construction, enabling efficient information aggregation and decision-making under constrained communication. A transformer-based message-passing mechanism, augmented with edge-feature-enhanced attention, captures complex interaction patterns, while a Double Deep Q-Network (Double DQN) with prioritized experience replay optimizes agent policies in partially observable environments. This integration is carefully designed to address specific requirements of multi-agent navigation, such as scalability, adaptability, and efficient task execution. Experimental results demonstrate superior performance, with 90% service provisioning and 100% grid coverage (node discovery), while reducing the average steps per episode to 200, compared to 600 for benchmark methods such as particle swarm optimization (PSO), greedy algorithms and DQN.