 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-SPPO: Semantic-Calibrated Self-Play Preference Optimization
Jun 01, 2026Aligning Large Language Models (LLMs) with human preferences is often formulated via Direct Preference Optimization (DPO). However, the standard Bradley-Terry instantiation of DPO is limited in modeling common departures from transitivity in human preferences. To address this, recent work has introduced Self-Play Preference Optimization (SPPO), which iteratively refines the policy by training on self-generated win-lose pairs. Our investigation, however, reveals a critical instability in SPPO: the optimization is prone to policy degeneration when the preference oracle assigns overly confident wins to semantically indistinguishable responses. To mitigate this, we propose S-SPPO, a dual-space semantic calibration framework comprising: i) Supervision Calibration via semantic gating, which anneals win rate targets toward the maximum-entropy baseline as semantic overlap increases; and ii) Representation Calibration via latent repulsion to enforce geometric diversity to prevent manifold collapse and maintain latent diversity between chosen and rejected samples. Theoretically, we show that the calibration preserves the constant-sum game structure, facilitating convergence to a Nash Equilibrium. Empirically, S-SPPO avoids the performance degradation seen in prior methods, achieving 52.19% win rate and 47.46% length-controlled win rate on AlpacaEval 2.0 with Llama-3-8B, without using additional human-annotated preferences during training. The code will be available at https://github.com/xiwenc1/s-sppo.
Don't Waste Bits! Adaptive KV-Cache Quantization for Lightweight On-Device LLMs
Apr 06, 2026Large Language Models (LLMs) have achieved remarkable progress across reasoning, generation, and decision-making tasks, yet deploying them on mobile, embedded, and edge devices remains particularly challenging. On-device LLM inference is heavily constrained by the memory and bandwidth overhead of the key-value (KV) cache, which grows linearly with context length and often dominates decoding cost. Existing KV-cache quantization schemes typically rely on fixed precision or hand-crafted heuristics, thereby wasting bits on low-impact tokens while over-compressing informative ones, leading to avoidable accuracy degradation. Inspired by Huffman coding's principle of variable-length allocation, we propose adaptive KV-cache quantization, a learned policy that assigns bit-width proportional to token importance, minimizing expected memory and latency without sacrificing competitive accuracy. Our framework extracts lightweight token-level features, including token frequency, quality score, attention variance, and entropy-based uncertainty, and feeds them into a compact data-driven controller that dynamically selects KV precision from {2-bit, 4-bit, 8-bit, FP16} during decoding. This adaptive precision policy reduces KV memory footprint and latency while improving accuracy compared to static KV quantization and rule-based baselines, and maintaining competitive accuracy close to FP16 inference across standard LLM benchmarks. Extensive experiments across multiple commonsense reasoning benchmarks using SmolLM-135M, SmolLM-360M, and SmolLM-1.7B demonstrate that our controller consistently improves the accuracy-latency trade-off. For instance, with SmolLM-360M on HellaSwag, our method reduces decoding latency (ms/token) by 17.75% relative to static KV quantization, improves accuracy by 7.60 points, and remains within only 0.30 points of FP16 inference.
Meta-Adaptive Beam Search Planning for Transformer-Based Reinforcement Learning Control of UAVs with Overhead Manipulators under Flight Disturbances
Mar 27, 2026Drones equipped with overhead manipulators offer unique capabilities for inspection, maintenance, and contact-based interaction. However, the motion of the drone and its manipulator is tightly linked, and even small attitude changes caused by wind or control imperfections shift the end-effector away from its intended path. This coupling makes reliable tracking difficult and also limits the direct use of learning-based arm controllers that were originally designed for fixed-base robots. These effects appear consistently in our tests whenever the UAV body experiences drift or rapid attitude corrections. To address this behavior, we develop a reinforcement-learning (RL) framework with a transformer-based double deep Q learning (DDQN), with the core idea of using an adaptive beam-search planner that applies a short-horizon beam search over candidate control sequences using the learned critic as the forward estimator. This allows the controller to anticipate the end-effector's motion through simulated rollouts rather than executing those actions directly on the actual model, realizing a software-in-the-loop (SITL) approach. The lookahead relies on value estimates from a Transformer critic that processes short sequences of states, while a DDQN backbone provides the one-step targets needed to keep the learning process stable. Evaluated on a 3-DoF aerial manipulator under identical training conditions, the proposed meta-adaptive planner shows the strongest overall performance with a 10.2% reward increase, a substantial reduction in mean tracking error (from about 6% to 3%), and a 29.6% improvement in the combined reward-error metric relative to the DDQN baseline. Our method exhibits elevated stability in tracking target tip trajectory (by maintaining 5 cm tracking error) when the drone base exhibits drifts due to external disturbances, as opposed to the fixed-beam and Transformer-only variants.
Comparative Analysis of Patch Attack on VLM-Based Autonomous Driving Architectures
Mar 09, 2026Vision-language models are emerging for autonomous driving, yet their robustness to physical adversarial attacks remains unexplored. This paper presents a systematic framework for comparative adversarial evaluation across three VLM architectures: Dolphins, OmniDrive (Omni-L), and LeapVAD. Using black-box optimization with semantic homogenization for fair comparison, we evaluate physically realizable patch attacks in CARLA simulation. Results reveal severe vulnerabilities across all architectures, sustained multi-frame failures, and critical object detection degradation. Our analysis exposes distinct architectural vulnerability patterns, demonstrating that current VLM designs inadequately address adversarial threats in safety-critical autonomous driving applications.
OTPrune: Distribution-Aligned Visual Token Pruning via Optimal Transport
Feb 25, 2026Multi-modal large language models (MLLMs) achieve strong visual-language reasoning but suffer from high inference cost due to redundant visual tokens. Recent work explores visual token pruning to accelerate inference, while existing pruning methods overlook the underlying distributional structure of visual representations. We propose OTPrune, a training-free framework that formulates pruning as distribution alignment via optimal transport (OT). By minimizing the 2-Wasserstein distance between the full and pruned token distributions, OTPrune preserves both local diversity and global representativeness while reducing inference cost. Moreover, we derive a tractable submodular objective that enables efficient optimization, and theoretically prove its monotonicity and submodularity, providing a principled foundation for stable and efficient pruning. We further provide a comprehensive analysis that explains how distributional alignment contributes to stable and semantically faithful pruning. Comprehensive experiments on wider benchmarks demonstrate that OTPrune achieves superior performance-efficiency tradeoffs compared to state-of-the-art methods. The code is available at https://github.com/xiwenc1/OTPrune.
Reliability-Aware Determinantal Point Processes for Robust Informative Data Selection in Large Language Models
Jan 31, 2026Informative data selection is a key requirement for large language models (LLMs) to minimize the amount of data required for fine-tuning, network distillation, and token pruning, enabling fast and efficient deployment, especially under computational and communication constraints. Traditional subset selection methods, including those based on Determinantal Point Processes (DPP), focus on maximizing diversity but assume that selected data batches are always available error-free. This presumption prohibits their use under partial storage outage, imperfect communication, and stochastic access failures. Furthermore, we show that the original formulation collapses under such conditions. To address this gap, we introduce ProbDPP, a novel reliability-aware implementation of k-DPP that accounts for probabilistic data access by recasting the objective function with a regularization term that remains well-posed and decomposes into a geometric diversity term and unreliability cost. The resulting objective facilitates robust selection of diverse data batches under uncertainty. Furthermore, we frame this reliability-aware diversity maximization as a combinatorial semi-bandit problem and propose a UCB-style algorithm to efficiently learn the unknown reliability online. Theoretical analysis provides regret bounds for the proposed approach, ensuring performance guarantees.
Spatial-Conditioned Reasoning in Long-Egocentric Videos
Jan 26, 2026Long-horizon egocentric video presents significant challenges for visual navigation due to viewpoint drift and the absence of persistent geometric context. Although recent vision-language models perform well on image and short-video reasoning, their spatial reasoning capability in long egocentric sequences remains limited. In this work, we study how explicit spatial signals influence VLM-based video understanding without modifying model architectures or inference procedures. We introduce Sanpo-D, a fine-grained re-annotation of the Google Sanpo dataset, and benchmark multiple VLMs on navigation-oriented spatial queries. To examine input-level inductive bias, we further fuse depth maps with RGB frames and evaluate their impact on spatial reasoning. Our results reveal a trade-off between general-purpose accuracy and spatial specialization, showing that depth-aware and spatially grounded representations can improve performance on safety-critical tasks such as pedestrian and obstruction detection.
Motion Focus Recognition in Fast-Moving Egocentric Video
Jan 12, 2026From Vision-Language-Action (VLA) systems to robotics, existing egocentric datasets primarily focus on action recognition tasks, while largely overlooking the inherent role of motion analysis in sports and other fast-movement scenarios. To bridge this gap, we propose a real-time motion focus recognition method that estimates the subject's locomotion intention from any egocentric video. Our approach leverages the foundation model for camera pose estimation and introduces system-level optimizations to enable efficient and scalable inference. Evaluated on a collected egocentric action dataset, our method achieves real-time performance with manageable memory consumption through a sliding batch inference strategy. This work makes motion-centric analysis practical for edge deployment and offers a complementary perspective to existing egocentric studies on sports and fast-movement activities.
Factorized Transport Alignment for Multimodal and Multiview E-commerce Representation Learning
Dec 19, 2025The rapid growth of e-commerce requires robust multimodal representations that capture diverse signals from user-generated listings. Existing vision-language models (VLMs) typically align titles with primary images, i.e., single-view, but overlook non-primary images and auxiliary textual views that provide critical semantics in open marketplaces such as Etsy or Poshmark. To this end, we propose a framework that unifies multimodal and multi-view learning through Factorized Transport, a lightweight approximation of optimal transport, designed for scalability and deployment efficiency. During training, the method emphasizes primary views while stochastically sampling auxiliary ones, reducing training cost from quadratic in the number of views to constant per item. At inference, all views are fused into a single cached embedding, preserving the efficiency of two-tower retrieval with no additional online overhead. On an industrial dataset of 1M product listings and 0.3M interactions, our approach delivers consistent improvements in cross-view and query-to-item retrieval, achieving up to +7.9% Recall@500 over strong multimodal baselines. Overall, our framework bridges scalability with optimal transport-based learning, making multi-view pretraining practical for large-scale e-commerce search.
Fast 2DGS: Efficient Image Representation with Deep Gaussian Prior
Dec 14, 2025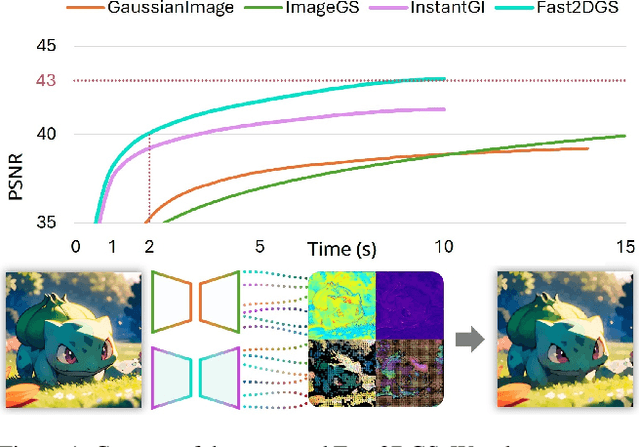

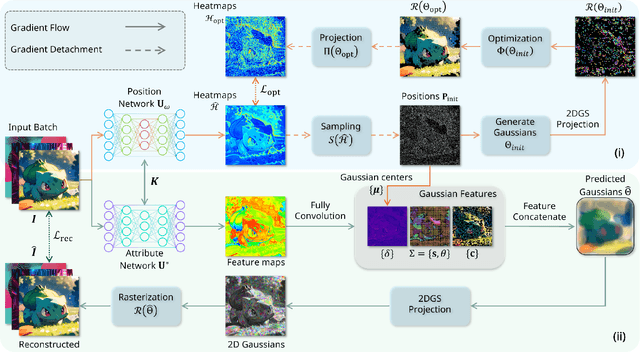
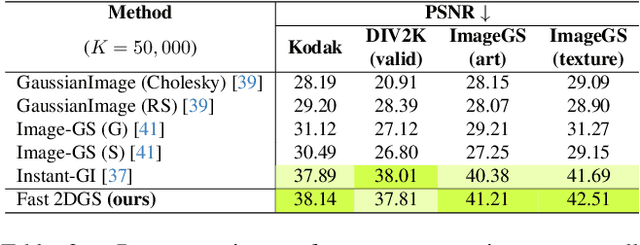
As generative models become increasingly capable of producing high-fidelity visual content, the demand for efficient, interpretable, and editable image representations has grown substantially. Recent advances in 2D Gaussian Splatting (2DGS) have emerged as a promising solution, offering explicit control, high interpretability, and real-time rendering capabilities (>1000 FPS). However, high-quality 2DGS typically requires post-optimization. Existing methods adopt random or heuristics (e.g., gradient maps), which are often insensitive to image complexity and lead to slow convergence (>10s). More recent approaches introduce learnable networks to predict initial Gaussian configurations, but at the cost of increased computational and architectural complexity. To bridge this gap, we present Fast-2DGS, a lightweight framework for efficient Gaussian image representation. Specifically, we introduce Deep Gaussian Prior, implemented as a conditional network to capture the spatial distribution of Gaussian primitives under different complexities. In addition, we propose an attribute regression network to predict dense Gaussian properties. Experiments demonstrate that this disentangled architecture achieves high-quality reconstruction in a single forward pass, followed by minimal fine-tuning. More importantly, our approach significantly reduces computational cost without compromising visual quality, bringing 2DGS closer to industry-ready deployment.