 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Conditioned Reasoning in Long-Egocentric Videos
Jan 26, 2026Long-horizon egocentric video presents significant challenges for visual navigation due to viewpoint drift and the absence of persistent geometric context. Although recent vision-language models perform well on image and short-video reasoning, their spatial reasoning capability in long egocentric sequences remains limited. In this work, we study how explicit spatial signals influence VLM-based video understanding without modifying model architectures or inference procedures. We introduce Sanpo-D, a fine-grained re-annotation of the Google Sanpo dataset, and benchmark multiple VLMs on navigation-oriented spatial queries. To examine input-level inductive bias, we further fuse depth maps with RGB frames and evaluate their impact on spatial reasoning. Our results reveal a trade-off between general-purpose accuracy and spatial specialization, showing that depth-aware and spatially grounded representations can improve performance on safety-critical tasks such as pedestrian and obstruction detection.
Motion Focus Recognition in Fast-Moving Egocentric Video
Jan 12, 2026From Vision-Language-Action (VLA) systems to robotics, existing egocentric datasets primarily focus on action recognition tasks, while largely overlooking the inherent role of motion analysis in sports and other fast-movement scenarios. To bridge this gap, we propose a real-time motion focus recognition method that estimates the subject's locomotion intention from any egocentric video. Our approach leverages the foundation model for camera pose estimation and introduces system-level optimizations to enable efficient and scalable inference. Evaluated on a collected egocentric action dataset, our method achieves real-time performance with manageable memory consumption through a sliding batch inference strategy. This work makes motion-centric analysis practical for edge deployment and offers a complementary perspective to existing egocentric studies on sports and fast-movement activities.
Fast 2DGS: Efficient Image Representation with Deep Gaussian Prior
Dec 14, 2025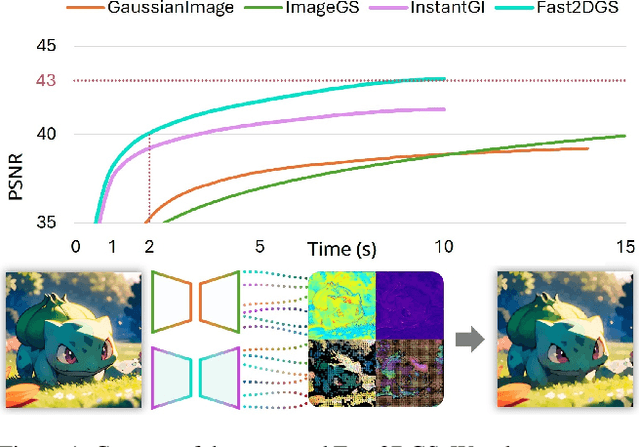

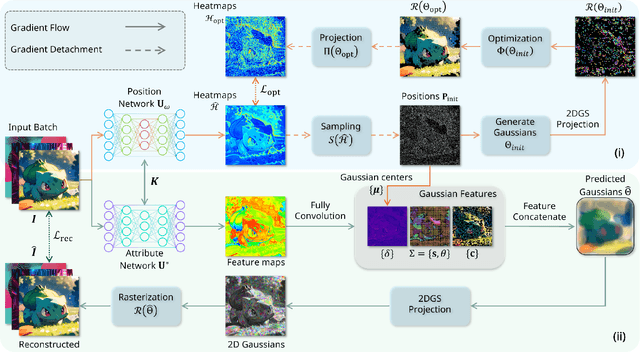
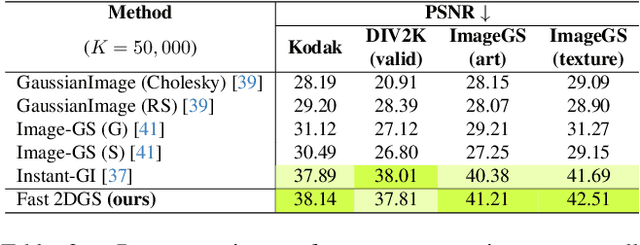
As generative models become increasingly capable of producing high-fidelity visual content, the demand for efficient, interpretable, and editable image representations has grown substantially. Recent advances in 2D Gaussian Splatting (2DGS) have emerged as a promising solution, offering explicit control, high interpretability, and real-time rendering capabilities (>1000 FPS). However, high-quality 2DGS typically requires post-optimization. Existing methods adopt random or heuristics (e.g., gradient maps), which are often insensitive to image complexity and lead to slow convergence (>10s). More recent approaches introduce learnable networks to predict initial Gaussian configurations, but at the cost of increased computational and architectural complexity. To bridge this gap, we present Fast-2DGS, a lightweight framework for efficient Gaussian image representation. Specifically, we introduce Deep Gaussian Prior, implemented as a conditional network to capture the spatial distribution of Gaussian primitives under different complexities. In addition, we propose an attribute regression network to predict dense Gaussian properties. Experiments demonstrate that this disentangled architecture achieves high-quality reconstruction in a single forward pass, followed by minimal fine-tuning. More importantly, our approach significantly reduces computational cost without compromising visual quality, bringing 2DGS closer to industry-ready deployment.
Anomaly Detection in Cooperative Vehicle Perception Systems under Imperfect Communication
Jan 28, 2025



Anomaly detection is a critical requirement for ensuring safety in autonomous driving. In this work, we leverage Cooperative Perception to share information across nearby vehicles, enabling more accurate identification and consensus of anomalous behaviors in complex traffic scenarios. To account for the real-world challenge of imperfect communication, we propose a cooperative-perception-based anomaly detection framework (CPAD), which is a robust architecture that remains effective under communication interruptions, thereby facilitating reliable performance even in low-bandwidth settings. Since no multi-agent anomaly detection dataset exists for vehicle trajectories, we introduce 15,000 different scenarios with a 90,000 trajectories benchmark dataset generated through rule-based vehicle dynamics analysis. Empirical results demonstrate that our approach outperforms standard anomaly classification methods in F1-score, AUC and showcase strong robustness to agent connection interruptions.
Diffusion Prism: Enhancing Diversity and Morphology Consistency in Mask-to-Image Diffusion
Jan 01, 2025The emergence of generative AI and controllable diffusion has made image-to-image synthesis increasingly practical and efficient. However, when input images exhibit low entropy and sparse, the inherent characteristics of diffusion models often result in limited diversity. This constraint significantly interferes with data augmentation. To address this, we propose Diffusion Prism, a training-free framework that efficiently transforms binary masks into realistic and diverse samples while preserving morphological features. We explored that a small amount of artificial noise will significantly assist the image-denoising process. To prove this novel mask-to-image concept, we use nano-dendritic patterns as an example to demonstrate the merit of our method compared to existing controllable diffusion models. Furthermore, we extend the proposed framework to other biological patterns, highlighting its potential applications across various fields.
RobustFormer: Noise-Robust Pre-training for images and videos
Nov 20, 2024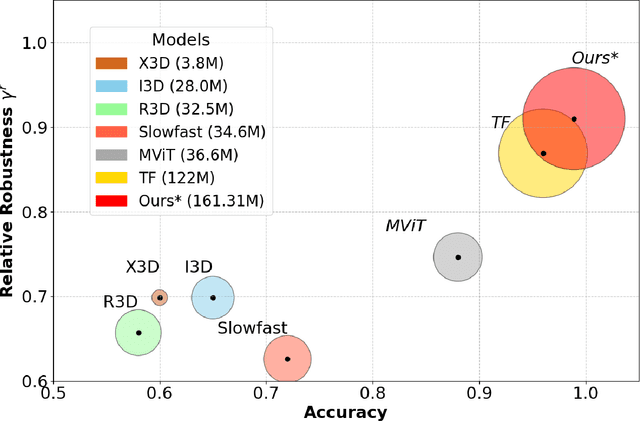
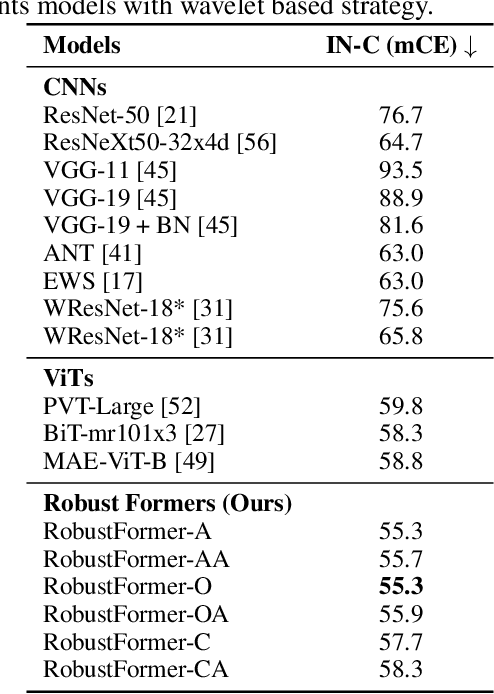
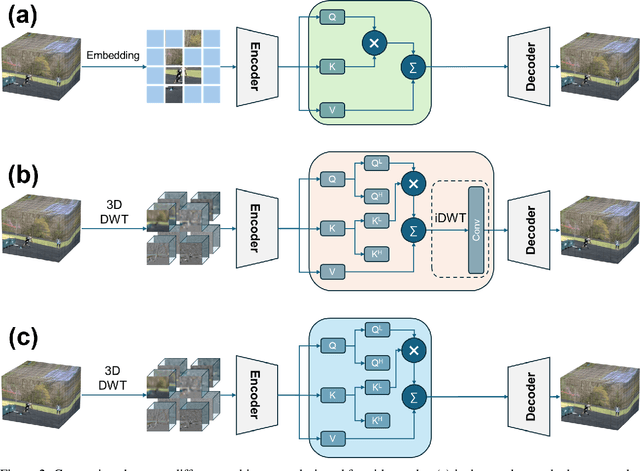
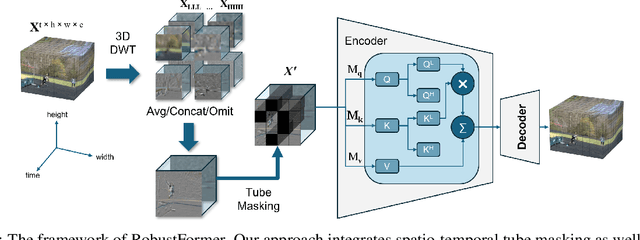
While deep learning models are powerful tools that revolutionized many areas, they are also vulnerable to noise as they rely heavily on learning patterns and features from the exact details of the clean data. Transformers, which have become the backbone of modern vision models, are no exception. Current Discrete Wavelet Transforms (DWT) based methods do not benefit from masked autoencoder (MAE) pre-training since the inverse DWT (iDWT) introduced in these approaches is computationally inefficient and lacks compatibility with video inputs in transformer architectures. In this work, we present RobustFormer, a method that overcomes these limitations by enabling noise-robust pre-training for both images and videos; improving the efficiency of DWT-based methods by removing the need for computationally iDWT steps and simplifying the attention mechanism. To our knowledge, the proposed method is the first DWT-based method compatible with video inputs and masked pre-training. Our experiments show that MAE-based pre-training allows us to bypass the iDWT step, greatly reducing computation. Through extensive tests on benchmark datasets, RobustFormer achieves state-of-the-art results for both image and video tasks.
Motor Focus: Ego-Motion Prediction with All-Pixel Matching
Apr 25, 2024Motion analysis plays a critical role in various applications, from virtual reality and augmented reality to assistive visual navigation. Traditional self-driving technologies, while advanced, typically do not translate directly to pedestrian applications due to their reliance on extensive sensor arrays and non-feasible computational frameworks. This highlights a significant gap in applying these solutions to human users since human navigation introduces unique challenges, including the unpredictable nature of human movement, limited processing capabilities of portable devices, and the need for directional responsiveness due to the limited perception range of humans. In this project, we introduce an image-only method that applies motion analysis using optical flow with ego-motion compensation to predict Motor Focus-where and how humans or machines focus their movement intentions. Meanwhile, this paper addresses the camera shaking issue in handheld and body-mounted devices which can severely degrade performance and accuracy, by applying a Gaussian aggregation to stabilize the predicted motor focus area and enhance the prediction accuracy of movement direction. This also provides a robust, real-time solution that adapts to the user's immediate environment. Furthermore, in the experiments part, we show the qualitative analysis of motor focus estimation between the conventional dense optical flow-based method and the proposed method. In quantitative tests, we show the performance of the proposed method on a collected small dataset that is specialized for motor focus estimation tasks.
VisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation
Mar 19, 2024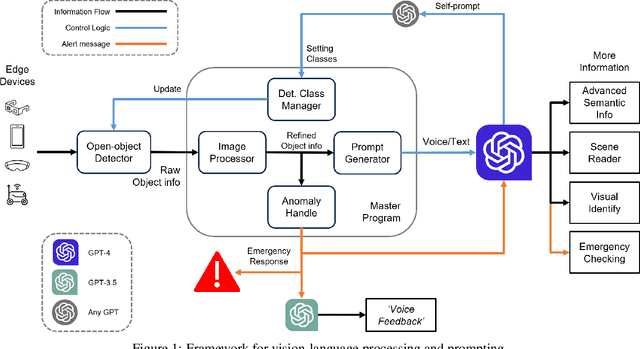
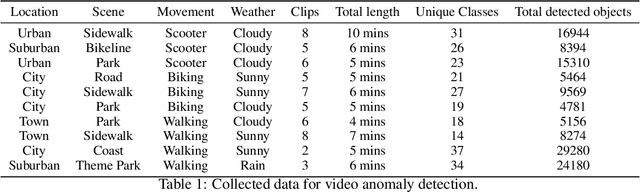
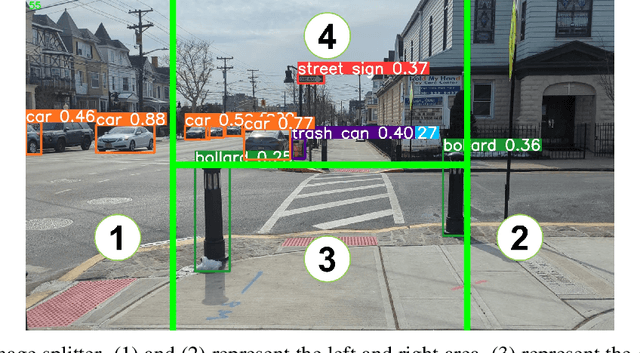

This paper explores the potential of Large Language Models(LLMs) in zero-shot anomaly detection for safe visual navigation. With the assistance of the state-of-the-art real-time open-world object detection model Yolo-World and specialized prompts, the proposed framework can identify anomalies within camera-captured frames that include any possible obstacles, then generate concise, audio-delivered descriptions emphasizing abnormalities, assist in safe visual navigation in complex circumstances. Moreover, our proposed framework leverages the advantages of LLMs and the open-vocabulary object detection model to achieve the dynamic scenario switch, which allows users to transition smoothly from scene to scene, which addresses the limitation of traditional visual navigation. Furthermore, this paper explored the performance contribution of different prompt components, provided the vision for future improvement in visual accessibility, and paved the way for LLMs in video anomaly detection and vision-language understanding.
FLAME Diffuser: Grounded Wildfire Image Synthesis using Mask Guided Diffusion
Mar 06, 2024



The rise of machine learning in recent years has brought benefits to various research fields such as wide fire detection. Nevertheless, small object detection and rare object detection remain a challenge. To address this problem, we present a dataset automata that can generate ground truth paired datasets using diffusion models. Specifically, we introduce a mask-guided diffusion framework that can fusion the wildfire into the existing images while the flame position and size can be precisely controlled. In advance, to fill the gap that the dataset of wildfire images in specific scenarios is missing, we vary the background of synthesized images by controlling both the text prompt and input image. Furthermore, to solve the color tint problem or the well-known domain shift issue, we apply the CLIP model to filter the generated massive dataset to preserve quality. Thus, our proposed framework can generate a massive dataset of that images are high-quality and ground truth-paired, which well addresses the needs of the annotated datasets in specific tasks.
Driving Towards Inclusion: Revisiting In-Vehicle Interaction in Autonomous Vehicles
Jan 26, 2024



This paper presents a comprehensive literature review of the current state of in-vehicle human-computer interaction (HCI) in the context of self-driving vehicles, with a specific focus on inclusion and accessibility. This study's aim is to examine the user-centered design principles for inclusive HCI in self-driving vehicles, evaluate existing HCI systems, and identify emerging technologies that have the potential to enhance the passenger experience. The paper begins by providing an overview of the current state of self-driving vehicle technology, followed by an examination of the importance of HCI in this context. Next, the paper reviews the existing literature on inclusive HCI design principles and evaluates the effectiveness of current HCI systems in self-driving vehicles. The paper also identifies emerging technologies that have the potential to enhance the passenger experience, such as voice-activated interfaces, haptic feedback systems, and augmented reality displays. Finally, the paper proposes an end-to-end design framework for the development of an inclusive in-vehicle experience, which takes into consideration the needs of all passengers, including those with disabilities, or other accessibility requirements. This literature review highlights the importance of user-centered design principles in the development of HCI systems for self-driving vehicles and emphasizes the need for inclusive design to ensure that all passengers can safely and comfortably use these vehicles. The proposed end-to-end design framework provides a practical approach to achieving this goal and can serve as a valuable resource for designers, researchers, and policymakers in this field.