 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotor Focus: Ego-Motion Prediction with All-Pixel Matching
Apr 25, 2024Motion analysis plays a critical role in various applications, from virtual reality and augmented reality to assistive visual navigation. Traditional self-driving technologies, while advanced, typically do not translate directly to pedestrian applications due to their reliance on extensive sensor arrays and non-feasible computational frameworks. This highlights a significant gap in applying these solutions to human users since human navigation introduces unique challenges, including the unpredictable nature of human movement, limited processing capabilities of portable devices, and the need for directional responsiveness due to the limited perception range of humans. In this project, we introduce an image-only method that applies motion analysis using optical flow with ego-motion compensation to predict Motor Focus-where and how humans or machines focus their movement intentions. Meanwhile, this paper addresses the camera shaking issue in handheld and body-mounted devices which can severely degrade performance and accuracy, by applying a Gaussian aggregation to stabilize the predicted motor focus area and enhance the prediction accuracy of movement direction. This also provides a robust, real-time solution that adapts to the user's immediate environment. Furthermore, in the experiments part, we show the qualitative analysis of motor focus estimation between the conventional dense optical flow-based method and the proposed method. In quantitative tests, we show the performance of the proposed method on a collected small dataset that is specialized for motor focus estimation tasks.
VisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation
Mar 19, 2024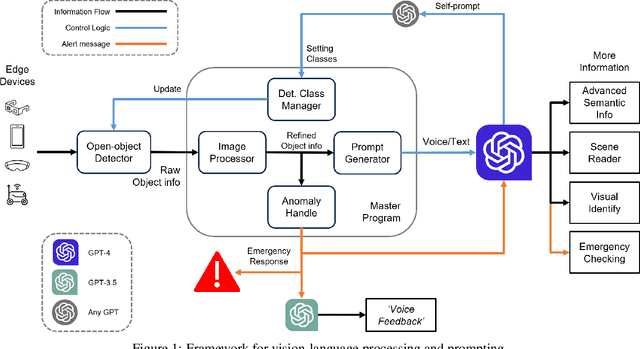
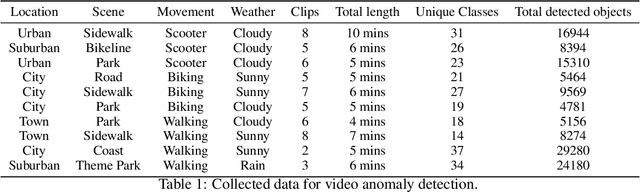
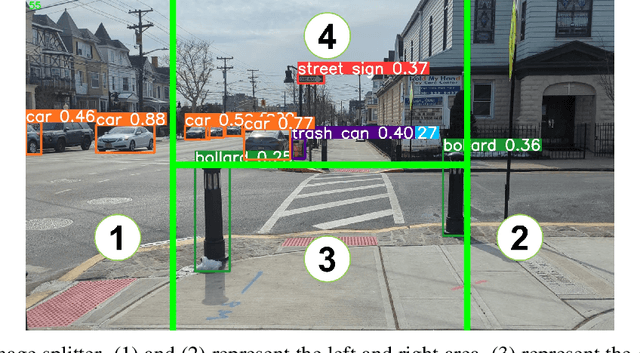

This paper explores the potential of Large Language Models(LLMs) in zero-shot anomaly detection for safe visual navigation. With the assistance of the state-of-the-art real-time open-world object detection model Yolo-World and specialized prompts, the proposed framework can identify anomalies within camera-captured frames that include any possible obstacles, then generate concise, audio-delivered descriptions emphasizing abnormalities, assist in safe visual navigation in complex circumstances. Moreover, our proposed framework leverages the advantages of LLMs and the open-vocabulary object detection model to achieve the dynamic scenario switch, which allows users to transition smoothly from scene to scene, which addresses the limitation of traditional visual navigation. Furthermore, this paper explored the performance contribution of different prompt components, provided the vision for future improvement in visual accessibility, and paved the way for LLMs in video anomaly detection and vision-language understanding.