 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation
Paper and Code
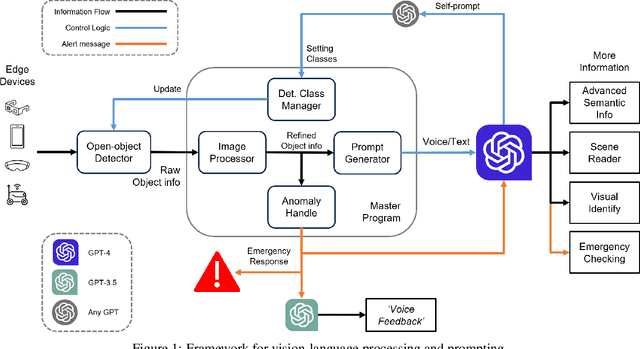
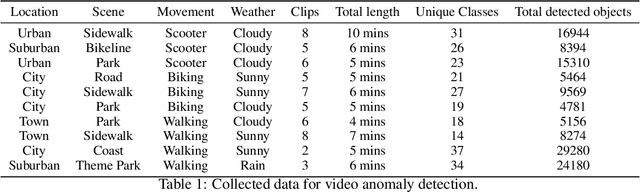
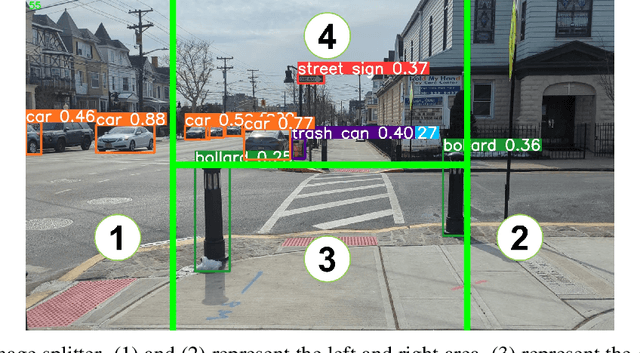

This paper explores the potential of Large Language Models(LLMs) in zero-shot anomaly detection for safe visual navigation. With the assistance of the state-of-the-art real-time open-world object detection model Yolo-World and specialized prompts, the proposed framework can identify anomalies within camera-captured frames that include any possible obstacles, then generate concise, audio-delivered descriptions emphasizing abnormalities, assist in safe visual navigation in complex circumstances. Moreover, our proposed framework leverages the advantages of LLMs and the open-vocabulary object detection model to achieve the dynamic scenario switch, which allows users to transition smoothly from scene to scene, which addresses the limitation of traditional visual navigation. Furthermore, this paper explored the performance contribution of different prompt components, provided the vision for future improvement in visual accessibility, and paved the way for LLMs in video anomaly detection and vision-language understanding.