 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning a Large Vision-Language Model for Artwork's Scoring and Critique
Feb 09, 2026Assessing artistic creativity is foundational to creativity research and arts education, yet manual scoring (e.g., Torrance Tests of Creative Thinking) is labor-intensive at scale. Prior machine-learning approaches show promise for visual creativity scoring, but many rely mainly on image features and provide limited or no explanatory feedback. We propose a framework for automated creativity assessment of human paintings by fine-tuning the vision-language model Qwen2-VL-7B with multi-task learning. Our dataset contains 1000 human-created paintings scored on a 1-100 scale and paired with a short human-written description (content or artist explanation). Two expert raters evaluated each work using a five-dimension rubric (originality, color, texture, composition, content) and provided written critiques; we use an 80/20 train-test split. We add a lightweight regression head on the visual encoder output so the model can predict a numerical score and generate rubric-aligned feedback in a single forward pass. By embedding the structured rubric and the artwork description in the system prompt, we constrain the generated text to match the quantitative prediction. Experiments show strong accuracy, achieving Pearson r > 0.97 and MAE about 3.95 on the 100-point scale. Qualitative evaluation indicates the generated feedback is semantically close to expert critiques (average SBERT cosine similarity = 0.798). The proposed approach bridges computer vision and art assessment and offers a scalable tool for creativity research and classroom feedback.
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
Jan 29, 2026High-definition (HD) maps provide essential semantic information of road structures for autonomous driving systems, yet current HD map construction methods require calibrated multi-camera setups and either implicit or explicit 2D-to-BEV transformations, making them fragile when sensors fail or camera configurations vary across vehicle fleets. We introduce FlexMap, unlike prior methods that are fixed to a specific N-camera rig, our approach adapts to variable camera configurations without any architectural changes or per-configuration retraining. Our key innovation eliminates explicit geometric projections by using a geometry-aware foundation model with cross-frame attention to implicitly encode 3D scene understanding in feature space. FlexMap features two core components: a spatial-temporal enhancement module that separates cross-view spatial reasoning from temporal dynamics, and a camera-aware decoder with latent camera tokens, enabling view-adaptive attention without the need for projection matrices. Experiments demonstrate that FlexMap outperforms existing methods across multiple configurations while maintaining robustness to missing views and sensor variations, enabling more practical real-world deployment.
Spatial-Conditioned Reasoning in Long-Egocentric Videos
Jan 26, 2026Long-horizon egocentric video presents significant challenges for visual navigation due to viewpoint drift and the absence of persistent geometric context. Although recent vision-language models perform well on image and short-video reasoning, their spatial reasoning capability in long egocentric sequences remains limited. In this work, we study how explicit spatial signals influence VLM-based video understanding without modifying model architectures or inference procedures. We introduce Sanpo-D, a fine-grained re-annotation of the Google Sanpo dataset, and benchmark multiple VLMs on navigation-oriented spatial queries. To examine input-level inductive bias, we further fuse depth maps with RGB frames and evaluate their impact on spatial reasoning. Our results reveal a trade-off between general-purpose accuracy and spatial specialization, showing that depth-aware and spatially grounded representations can improve performance on safety-critical tasks such as pedestrian and obstruction detection.
Motion Focus Recognition in Fast-Moving Egocentric Video
Jan 12, 2026From Vision-Language-Action (VLA) systems to robotics, existing egocentric datasets primarily focus on action recognition tasks, while largely overlooking the inherent role of motion analysis in sports and other fast-movement scenarios. To bridge this gap, we propose a real-time motion focus recognition method that estimates the subject's locomotion intention from any egocentric video. Our approach leverages the foundation model for camera pose estimation and introduces system-level optimizations to enable efficient and scalable inference. Evaluated on a collected egocentric action dataset, our method achieves real-time performance with manageable memory consumption through a sliding batch inference strategy. This work makes motion-centric analysis practical for edge deployment and offers a complementary perspective to existing egocentric studies on sports and fast-movement activities.
Fast 2DGS: Efficient Image Representation with Deep Gaussian Prior
Dec 14, 2025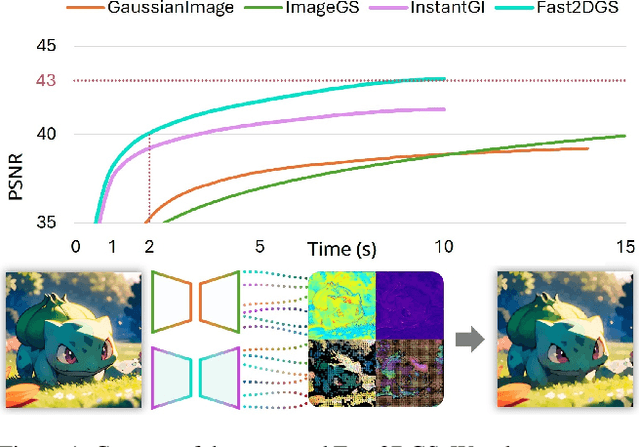

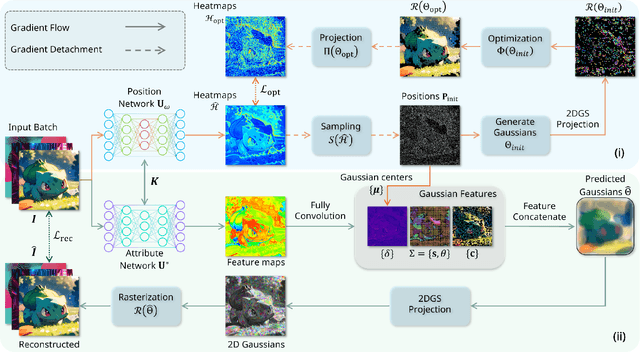
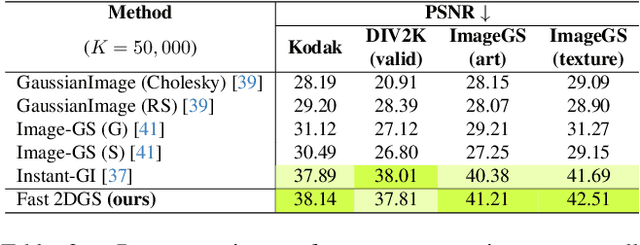
As generative models become increasingly capable of producing high-fidelity visual content, the demand for efficient, interpretable, and editable image representations has grown substantially. Recent advances in 2D Gaussian Splatting (2DGS) have emerged as a promising solution, offering explicit control, high interpretability, and real-time rendering capabilities (>1000 FPS). However, high-quality 2DGS typically requires post-optimization. Existing methods adopt random or heuristics (e.g., gradient maps), which are often insensitive to image complexity and lead to slow convergence (>10s). More recent approaches introduce learnable networks to predict initial Gaussian configurations, but at the cost of increased computational and architectural complexity. To bridge this gap, we present Fast-2DGS, a lightweight framework for efficient Gaussian image representation. Specifically, we introduce Deep Gaussian Prior, implemented as a conditional network to capture the spatial distribution of Gaussian primitives under different complexities. In addition, we propose an attribute regression network to predict dense Gaussian properties. Experiments demonstrate that this disentangled architecture achieves high-quality reconstruction in a single forward pass, followed by minimal fine-tuning. More importantly, our approach significantly reduces computational cost without compromising visual quality, bringing 2DGS closer to industry-ready deployment.
Bézier Splatting for Fast and Differentiable Vector Graphics
Mar 20, 2025



Differentiable vector graphics (VGs) are widely used in image vectorization and vector synthesis, while existing representations are costly to optimize and struggle to achieve high-quality rendering results for high-resolution images. This work introduces a new differentiable VG representation, dubbed B\'ezier splatting, that enables fast yet high-fidelity VG rasterization. B\'ezier splatting samples 2D Gaussians along B\'ezier curves, which naturally provide positional gradients at object boundaries. Thanks to the efficient splatting-based differentiable rasterizer, B\'ezier splatting achieves over 20x and 150x faster per forward and backward rasterization step for open curves compared to DiffVG. Additionally, we introduce an adaptive pruning and densification strategy that dynamically adjusts the spatial distribution of curves to escape local minima, further improving VG quality. Experimental results show that B\'ezier splatting significantly outperforms existing methods with better visual fidelity and 10x faster optimization speed.
Latent Radiance Fields with 3D-aware 2D Representations
Feb 13, 2025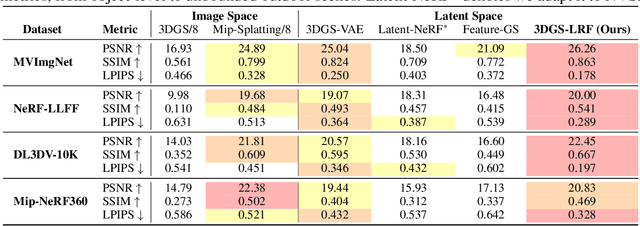
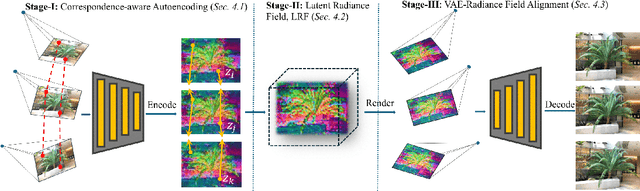


Latent 3D reconstruction has shown great promise in empowering 3D semantic understanding and 3D generation by distilling 2D features into the 3D space. However, existing approaches struggle with the domain gap between 2D feature space and 3D representations, resulting in degraded rendering performance. To address this challenge, we propose a novel framework that integrates 3D awareness into the 2D latent space. The framework consists of three stages: (1) a correspondence-aware autoencoding method that enhances the 3D consistency of 2D latent representations, (2) a latent radiance field (LRF) that lifts these 3D-aware 2D representations into 3D space, and (3) a VAE-Radiance Field (VAE-RF) alignment strategy that improves image decoding from the rendered 2D representations. Extensive experiments demonstrate that our method outperforms the state-of-the-art latent 3D reconstruction approaches in terms of synthesis performance and cross-dataset generalizability across diverse indoor and outdoor scenes. To our knowledge, this is the first work showing the radiance field representations constructed from 2D latent representations can yield photorealistic 3D reconstruction performance.
3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors
Oct 21, 2024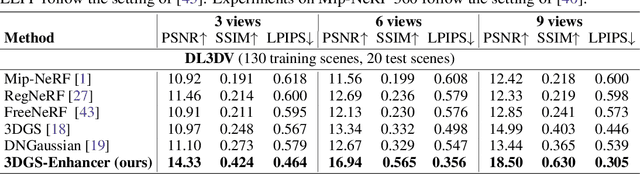
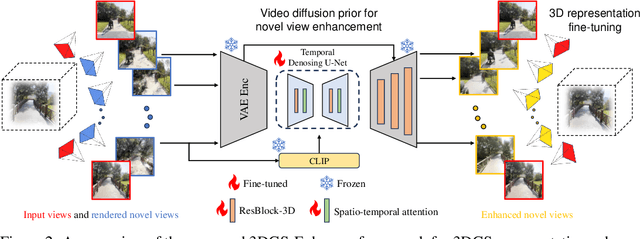
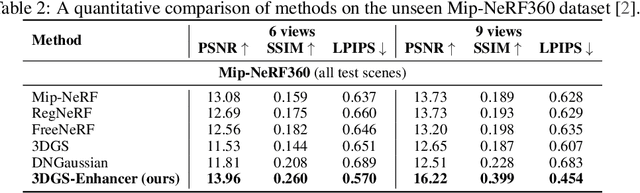

Novel-view synthesis aims to generate novel views of a scene from multiple input images or videos, and recent advancements like 3D Gaussian splatting (3DGS) have achieved notable success in producing photorealistic renderings with efficient pipelines. However, generating high-quality novel views under challenging settings, such as sparse input views, remains difficult due to insufficient information in under-sampled areas, often resulting in noticeable artifacts. This paper presents 3DGS-Enhancer, a novel pipeline for enhancing the representation quality of 3DGS representations. We leverage 2D video diffusion priors to address the challenging 3D view consistency problem, reformulating it as achieving temporal consistency within a video generation process. 3DGS-Enhancer restores view-consistent latent features of rendered novel views and integrates them with the input views through a spatial-temporal decoder. The enhanced views are then used to fine-tune the initial 3DGS model, significantly improving its rendering performance. Extensive experiments on large-scale datasets of unbounded scenes demonstrate that 3DGS-Enhancer yields superior reconstruction performance and high-fidelity rendering results compared to state-of-the-art methods. The project webpage is https://xiliu8006.github.io/3DGS-Enhancer-project .