 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-SPPO: Semantic-Calibrated Self-Play Preference Optimization
Jun 01, 2026Aligning Large Language Models (LLMs) with human preferences is often formulated via Direct Preference Optimization (DPO). However, the standard Bradley-Terry instantiation of DPO is limited in modeling common departures from transitivity in human preferences. To address this, recent work has introduced Self-Play Preference Optimization (SPPO), which iteratively refines the policy by training on self-generated win-lose pairs. Our investigation, however, reveals a critical instability in SPPO: the optimization is prone to policy degeneration when the preference oracle assigns overly confident wins to semantically indistinguishable responses. To mitigate this, we propose S-SPPO, a dual-space semantic calibration framework comprising: i) Supervision Calibration via semantic gating, which anneals win rate targets toward the maximum-entropy baseline as semantic overlap increases; and ii) Representation Calibration via latent repulsion to enforce geometric diversity to prevent manifold collapse and maintain latent diversity between chosen and rejected samples. Theoretically, we show that the calibration preserves the constant-sum game structure, facilitating convergence to a Nash Equilibrium. Empirically, S-SPPO avoids the performance degradation seen in prior methods, achieving 52.19% win rate and 47.46% length-controlled win rate on AlpacaEval 2.0 with Llama-3-8B, without using additional human-annotated preferences during training. The code will be available at https://github.com/xiwenc1/s-sppo.
LoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
SOLARIS: Speculative Offloading of Latent-bAsed Representation for Inference Scaling
Apr 13, 2026Recent advances in recommendation scaling laws have led to foundation models of unprecedented complexity. While these models offer superior performance, their computational demands make real-time serving impractical, often forcing practitioners to rely on knowledge distillation-compromising serving quality for efficiency. To address this challenge, we present SOLARIS (Speculative Offloading of Latent-bAsed Representation for Inference Scaling), a novel framework inspired by speculative decoding. SOLARIS proactively precomputes user-item interaction embeddings by predicting which user-item pairs are likely to appear in future requests, and asynchronously generating their foundation model representations ahead of time. This approach decouples the costly foundation model inference from the latency-critical serving path, enabling real-time knowledge transfer from models previously considered too expensive for online use. Deployed across Meta's advertising system serving billions of daily requests, SOLARIS achieves 0.67% revenue-driving top-line metrics gain, demonstrating its effectiveness at scale.
Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
Martingale Foresight Sampling: A Principled Approach to Inference-Time LLM Decoding
Jan 21, 2026Standard autoregressive decoding in large language models (LLMs) is inherently short-sighted, often failing to find globally optimal reasoning paths due to its token-by-token generation process. While inference-time strategies like foresight sampling attempt to mitigate this by simulating future steps, they typically rely on ad-hoc heuristics for valuing paths and pruning the search space. This paper introduces Martingale Foresight Sampling (MFS), a principled framework that reformulates LLM decoding as a problem of identifying an optimal stochastic process. By modeling the quality of a reasoning path as a stochastic process, we leverage Martingale theory to design a theoretically-grounded algorithm. Our approach replaces heuristic mechanisms with principles from probability theory: step valuation is derived from the Doob Decomposition Theorem to measure a path's predictable advantage, path selection uses Optional Stopping Theory for principled pruning of suboptimal candidates, and an adaptive stopping rule based on the Martingale Convergence Theorem terminates exploration once a path's quality has provably converged. Experiments on six reasoning benchmarks demonstrate that MFS surpasses state-of-the-art methods in accuracy while significantly improving computational efficiency. Code will be released at https://github.com/miraclehetech/EACL2026-Martingale-Foresight-Sampling.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
C2AL: Cohort-Contrastive Auxiliary Learning for Large-scale Recommendation Systems
Oct 02, 2025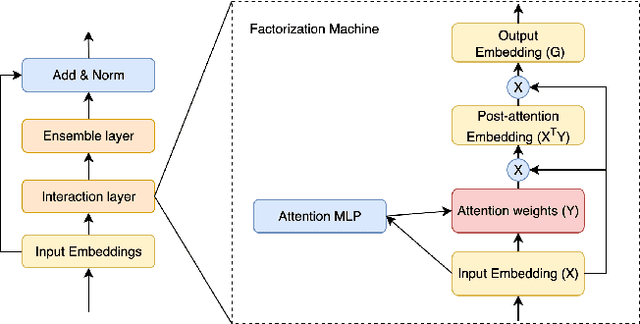
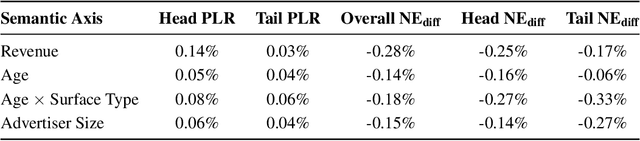
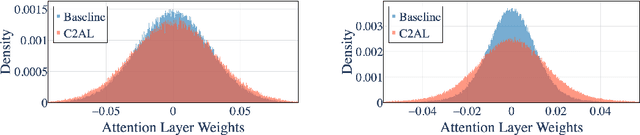

Training large-scale recommendation models under a single global objective implicitly assumes homogeneity across user populations. However, real-world data are composites of heterogeneous cohorts with distinct conditional distributions. As models increase in scale and complexity and as more data is used for training, they become dominated by central distribution patterns, neglecting head and tail regions. This imbalance limits the model's learning ability and can result in inactive attention weights or dead neurons. In this paper, we reveal how the attention mechanism can play a key role in factorization machines for shared embedding selection, and propose to address this challenge by analyzing the substructures in the dataset and exposing those with strong distributional contrast through auxiliary learning. Unlike previous research, which heuristically applies weighted labels or multi-task heads to mitigate such biases, we leverage partially conflicting auxiliary labels to regularize the shared representation. This approach customizes the learning process of attention layers to preserve mutual information with minority cohorts while improving global performance. We evaluated C2AL on massive production datasets with billions of data points each for six SOTA models. Experiments show that the factorization machine is able to capture fine-grained user-ad interactions using the proposed method, achieving up to a 0.16% reduction in normalized entropy overall and delivering gains exceeding 0.30% on targeted minority cohorts.
DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
May 14, 2025Recent advances in reinforcement learning for language model post-training, such as Group Relative Policy Optimization (GRPO), have shown promise in low-resource settings. However, GRPO typically relies on solution-level and scalar reward signals that fail to capture the semantic diversity among sampled completions. This leads to what we identify as a diversity-quality inconsistency, where distinct reasoning paths may receive indistinguishable rewards. To address this limitation, we propose $\textit{Diversity-aware Reward Adjustment}$ (DRA), a method that explicitly incorporates semantic diversity into the reward computation. DRA uses Submodular Mutual Information (SMI) to downweight redundant completions and amplify rewards for diverse ones. This encourages better exploration during learning, while maintaining stable exploitation of high-quality samples. Our method integrates seamlessly with both GRPO and its variant DR.~GRPO, resulting in $\textit{DRA-GRPO}$ and $\textit{DGA-DR.~GRPO}$. We evaluate our method on five mathematical reasoning benchmarks and find that it outperforms recent strong baselines. It achieves state-of-the-art performance with an average accuracy of 58.2%, using only 7,000 fine-tuning samples and a total training cost of approximately $55. The code is available at https://github.com/xiwenc1/DRA-GRPO.
FIC-TSC: Learning Time Series Classification with Fisher Information Constraint
May 09, 2025



Analyzing time series data is crucial to a wide spectrum of applications, including economics, online marketplaces, and human healthcare. In particular, time series classification plays an indispensable role in segmenting different phases in stock markets, predicting customer behavior, and classifying worker actions and engagement levels. These aspects contribute significantly to the advancement of automated decision-making and system optimization in real-world applications. However, there is a large consensus that time series data often suffers from domain shifts between training and test sets, which dramatically degrades the classification performance. Despite the success of (reversible) instance normalization in handling the domain shifts for time series regression tasks, its performance in classification is unsatisfactory. In this paper, we propose \textit{FIC-TSC}, a training framework for time series classification that leverages Fisher information as the constraint. We theoretically and empirically show this is an efficient and effective solution to guide the model converge toward flatter minima, which enhances its generalizability to distribution shifts. We rigorously evaluate our method on 30 UEA multivariate and 85 UCR univariate datasets. Our empirical results demonstrate the superiority of the proposed method over 14 recent state-of-the-art methods.
Prompt-OT: An Optimal Transport Regularization Paradigm for Knowledge Preservation in Vision-Language Model Adaptation
Mar 11, 2025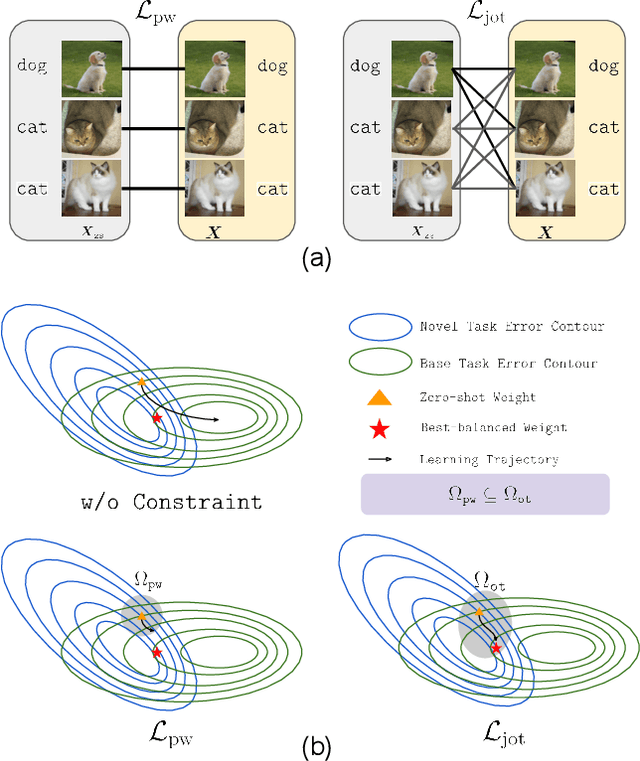



Vision-language models (VLMs) such as CLIP demonstrate strong performance but struggle when adapted to downstream tasks. Prompt learning has emerged as an efficient and effective strategy to adapt VLMs while preserving their pre-trained knowledge. However, existing methods still lead to overfitting and degrade zero-shot generalization. To address this challenge, we propose an optimal transport (OT)-guided prompt learning framework that mitigates forgetting by preserving the structural consistency of feature distributions between pre-trained and fine-tuned models. Unlike conventional point-wise constraints, OT naturally captures cross-instance relationships and expands the feasible parameter space for prompt tuning, allowing a better trade-off between adaptation and generalization. Our approach enforces joint constraints on both vision and text representations, ensuring a holistic feature alignment. Extensive experiments on benchmark datasets demonstrate that our simple yet effective method can outperform existing prompt learning strategies in base-to-novel generalization, cross-dataset evaluation, and domain generalization without additional augmentation or ensemble techniques. The code is available at https://github.com/ChongQingNoSubway/Prompt-OT