 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal normative modeling in Alzheimers Disease with introspective variational autoencoders
Feb 08, 2026Normative modeling learns a healthy reference distribution and quantifies subject-specific deviations to capture heterogeneous disease effects. In Alzheimers disease (AD), multimodal neuroimaging offers complementary signals but VAE-based normative models often (i) fit the healthy reference distribution imperfectly, inflating false positives, and (ii) use posterior aggregation (e.g., PoE/MoE) that can yield weak multimodal fusion in the shared latent space. We propose mmSIVAE, a multimodal soft-introspective variational autoencoder combined with Mixture-of-Product-of-Experts (MOPOE) aggregation to improve reference fidelity and multimodal integration. We compute deviation scores in latent space and feature space as distances from the learned healthy distributions, and map statistically significant latent deviations to regional abnormalities for interpretability. On ADNI MRI regional volumes and amyloid PET SUVR, mmSIVAE improves reconstruction on held-out controls and produces more discriminative deviation scores for outlier detection than VAE baselines, with higher likelihood ratios and clearer separation between control and AD-spectrum cohorts. Deviation maps highlight region-level patterns aligned with established AD-related changes. More broadly, our results highlight the importance of training objectives that prioritize reference-distribution fidelity and robust multimodal posterior aggregation for normative modeling, with implications for deviation-based analysis across multimodal clinical data.
DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
May 14, 2025Recent advances in reinforcement learning for language model post-training, such as Group Relative Policy Optimization (GRPO), have shown promise in low-resource settings. However, GRPO typically relies on solution-level and scalar reward signals that fail to capture the semantic diversity among sampled completions. This leads to what we identify as a diversity-quality inconsistency, where distinct reasoning paths may receive indistinguishable rewards. To address this limitation, we propose $\textit{Diversity-aware Reward Adjustment}$ (DRA), a method that explicitly incorporates semantic diversity into the reward computation. DRA uses Submodular Mutual Information (SMI) to downweight redundant completions and amplify rewards for diverse ones. This encourages better exploration during learning, while maintaining stable exploitation of high-quality samples. Our method integrates seamlessly with both GRPO and its variant DR.~GRPO, resulting in $\textit{DRA-GRPO}$ and $\textit{DGA-DR.~GRPO}$. We evaluate our method on five mathematical reasoning benchmarks and find that it outperforms recent strong baselines. It achieves state-of-the-art performance with an average accuracy of 58.2%, using only 7,000 fine-tuning samples and a total training cost of approximately $55. The code is available at https://github.com/xiwenc1/DRA-GRPO.
FIC-TSC: Learning Time Series Classification with Fisher Information Constraint
May 09, 2025



Analyzing time series data is crucial to a wide spectrum of applications, including economics, online marketplaces, and human healthcare. In particular, time series classification plays an indispensable role in segmenting different phases in stock markets, predicting customer behavior, and classifying worker actions and engagement levels. These aspects contribute significantly to the advancement of automated decision-making and system optimization in real-world applications. However, there is a large consensus that time series data often suffers from domain shifts between training and test sets, which dramatically degrades the classification performance. Despite the success of (reversible) instance normalization in handling the domain shifts for time series regression tasks, its performance in classification is unsatisfactory. In this paper, we propose \textit{FIC-TSC}, a training framework for time series classification that leverages Fisher information as the constraint. We theoretically and empirically show this is an efficient and effective solution to guide the model converge toward flatter minima, which enhances its generalizability to distribution shifts. We rigorously evaluate our method on 30 UEA multivariate and 85 UCR univariate datasets. Our empirical results demonstrate the superiority of the proposed method over 14 recent state-of-the-art methods.
How Effective Can Dropout Be in Multiple Instance Learning ?
Apr 21, 2025Multiple Instance Learning (MIL) is a popular weakly-supervised method for various applications, with a particular interest in histological whole slide image (WSI) classification. Due to the gigapixel resolution of WSI, applications of MIL in WSI typically necessitate a two-stage training scheme: first, extract features from the pre-trained backbone and then perform MIL aggregation. However, it is well-known that this suboptimal training scheme suffers from "noisy" feature embeddings from the backbone and inherent weak supervision, hindering MIL from learning rich and generalizable features. However, the most commonly used technique (i.e., dropout) for mitigating this issue has yet to be explored in MIL. In this paper, we empirically explore how effective the dropout can be in MIL. Interestingly, we observe that dropping the top-k most important instances within a bag leads to better performance and generalization even under noise attack. Based on this key observation, we propose a novel MIL-specific dropout method, termed MIL-Dropout, which systematically determines which instances to drop. Experiments on five MIL benchmark datasets and two WSI datasets demonstrate that MIL-Dropout boosts the performance of current MIL methods with a negligible computational cost. The code is available at https://github.com/ChongQingNoSubway/MILDropout.
Analysis of the MICCAI Brain Tumor Segmentation -- Metastases (BraTS-METS) 2025 Lighthouse Challenge: Brain Metastasis Segmentation on Pre- and Post-treatment MRI
Apr 16, 2025Despite continuous advancements in cancer treatment, brain metastatic disease remains a significant complication of primary cancer and is associated with an unfavorable prognosis. One approach for improving diagnosis, management, and outcomes is to implement algorithms based on artificial intelligence for the automated segmentation of both pre- and post-treatment MRI brain images. Such algorithms rely on volumetric criteria for lesion identification and treatment response assessment, which are still not available in clinical practice. Therefore, it is critical to establish tools for rapid volumetric segmentations methods that can be translated to clinical practice and that are trained on high quality annotated data. The BraTS-METS 2025 Lighthouse Challenge aims to address this critical need by establishing inter-rater and intra-rater variability in dataset annotation by generating high quality annotated datasets from four individual instances of segmentation by neuroradiologists while being recorded on video (two instances doing "from scratch" and two instances after AI pre-segmentation). This high-quality annotated dataset will be used for testing phase in 2025 Lighthouse challenge and will be publicly released at the completion of the challenge. The 2025 Lighthouse challenge will also release the 2023 and 2024 segmented datasets that were annotated using an established pipeline of pre-segmentation, student annotation, two neuroradiologists checking, and one neuroradiologist finalizing the process. It builds upon its previous edition by including post-treatment cases in the dataset. Using these high-quality annotated datasets, the 2025 Lighthouse challenge plans to test benchmark algorithms for automated segmentation of pre-and post-treatment brain metastases (BM), trained on diverse and multi-institutional datasets of MRI images obtained from patients with brain metastases.
Prompt-OT: An Optimal Transport Regularization Paradigm for Knowledge Preservation in Vision-Language Model Adaptation
Mar 11, 2025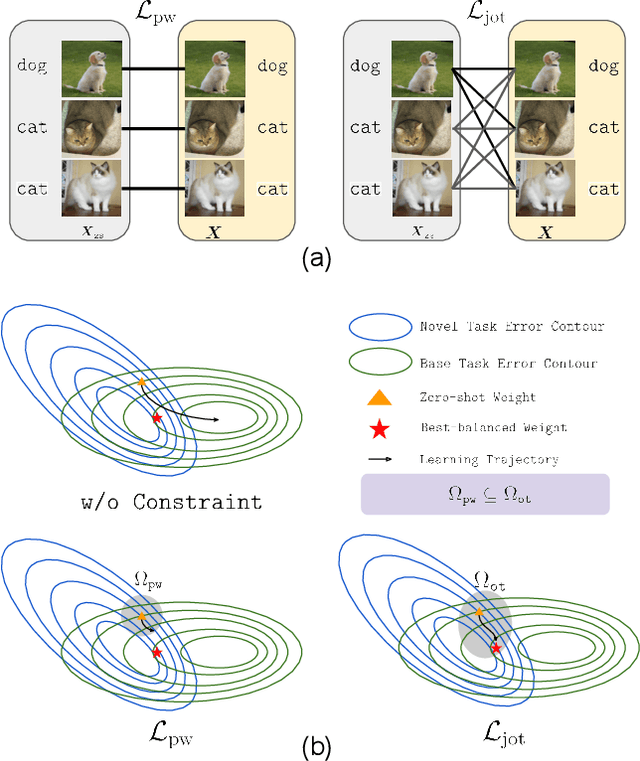



Vision-language models (VLMs) such as CLIP demonstrate strong performance but struggle when adapted to downstream tasks. Prompt learning has emerged as an efficient and effective strategy to adapt VLMs while preserving their pre-trained knowledge. However, existing methods still lead to overfitting and degrade zero-shot generalization. To address this challenge, we propose an optimal transport (OT)-guided prompt learning framework that mitigates forgetting by preserving the structural consistency of feature distributions between pre-trained and fine-tuned models. Unlike conventional point-wise constraints, OT naturally captures cross-instance relationships and expands the feasible parameter space for prompt tuning, allowing a better trade-off between adaptation and generalization. Our approach enforces joint constraints on both vision and text representations, ensuring a holistic feature alignment. Extensive experiments on benchmark datasets demonstrate that our simple yet effective method can outperform existing prompt learning strategies in base-to-novel generalization, cross-dataset evaluation, and domain generalization without additional augmentation or ensemble techniques. The code is available at https://github.com/ChongQingNoSubway/Prompt-OT
Sequence Complementor: Complementing Transformers For Time Series Forecasting with Learnable Sequences
Jan 06, 2025



Since its introduction, the transformer has shifted the development trajectory away from traditional models (e.g., RNN, MLP) in time series forecasting, which is attributed to its ability to capture global dependencies within temporal tokens. Follow-up studies have largely involved altering the tokenization and self-attention modules to better adapt Transformers for addressing special challenges like non-stationarity, channel-wise dependency, and variable correlation in time series. However, we found that the expressive capability of sequence representation is a key factor influencing Transformer performance in time forecasting after investigating several representative methods, where there is an almost linear relationship between sequence representation entropy and mean square error, with more diverse representations performing better. In this paper, we propose a novel attention mechanism with Sequence Complementors and prove feasible from an information theory perspective, where these learnable sequences are able to provide complementary information beyond current input to feed attention. We further enhance the Sequence Complementors via a diversification loss that is theoretically covered. The empirical evaluation of both long-term and short-term forecasting has confirmed its superiority over the recent state-of-the-art methods.
Multimodal Variational Autoencoder: a Barycentric View
Dec 29, 2024Multiple signal modalities, such as vision and sounds, are naturally present in real-world phenomena. Recently, there has been growing interest in learning generative models, in particular variational autoencoder (VAE), to for multimodal representation learning especially in the case of missing modalities. The primary goal of these models is to learn a modality-invariant and modality-specific representation that characterizes information across multiple modalities. Previous attempts at multimodal VAEs approach this mainly through the lens of experts, aggregating unimodal inference distributions with a product of experts (PoE), a mixture of experts (MoE), or a combination of both. In this paper, we provide an alternative generic and theoretical formulation of multimodal VAE through the lens of barycenter. We first show that PoE and MoE are specific instances of barycenters, derived by minimizing the asymmetric weighted KL divergence to unimodal inference distributions. Our novel formulation extends these two barycenters to a more flexible choice by considering different types of divergences. In particular, we explore the Wasserstein barycenter defined by the 2-Wasserstein distance, which better preserves the geometry of unimodal distributions by capturing both modality-specific and modality-invariant representations compared to KL divergence. Empirical studies on three multimodal benchmarks demonstrated the effectiveness of the proposed method.
QCResUNet: Joint Subject-level and Voxel-level Segmentation Quality Prediction
Dec 10, 2024Deep learning has made significant strides in automated brain tumor segmentation from magnetic resonance imaging (MRI) scans in recent years. However, the reliability of these tools is hampered by the presence of poor-quality segmentation outliers, particularly in out-of-distribution samples, making their implementation in clinical practice difficult. Therefore, there is a need for quality control (QC) to screen the quality of the segmentation results. Although numerous automatic QC methods have been developed for segmentation quality screening, most were designed for cardiac MRI segmentation, which involves a single modality and a single tissue type. Furthermore, most prior works only provided subject-level predictions of segmentation quality and did not identify erroneous parts segmentation that may require refinement. To address these limitations, we proposed a novel multi-task deep learning architecture, termed QCResUNet, which produces subject-level segmentation-quality measures as well as voxel-level segmentation error maps for each available tissue class. To validate the effectiveness of the proposed method, we conducted experiments on assessing its performance on evaluating the quality of two distinct segmentation tasks. First, we aimed to assess the quality of brain tumor segmentation results. For this task, we performed experiments on one internal and two external datasets. Second, we aimed to evaluate the segmentation quality of cardiac Magnetic Resonance Imaging (MRI) data from the Automated Cardiac Diagnosis Challenge. The proposed method achieved high performance in predicting subject-level segmentation-quality metrics and accurately identifying segmentation errors on a voxel basis. This has the potential to be used to guide human-in-the-loop feedback to improve segmentations in clinical settings.
DMC-Net: Lightweight Dynamic Multi-Scale and Multi-Resolution Convolution Network for Pancreas Segmentation in CT Images
Oct 03, 2024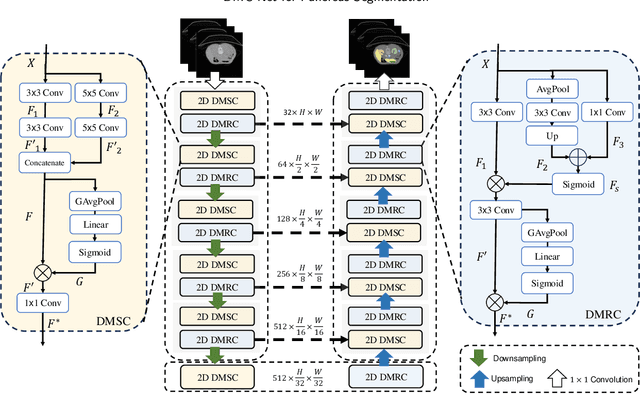
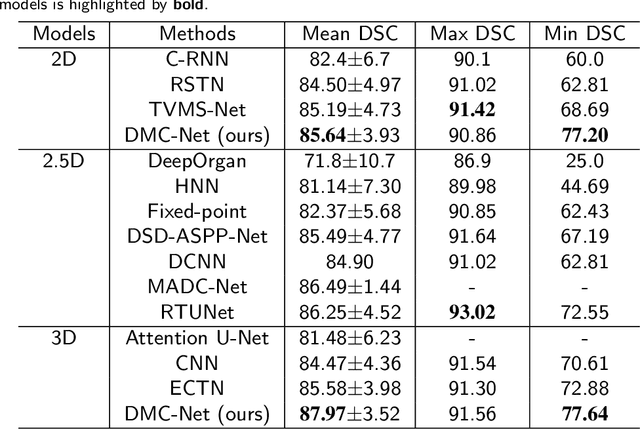
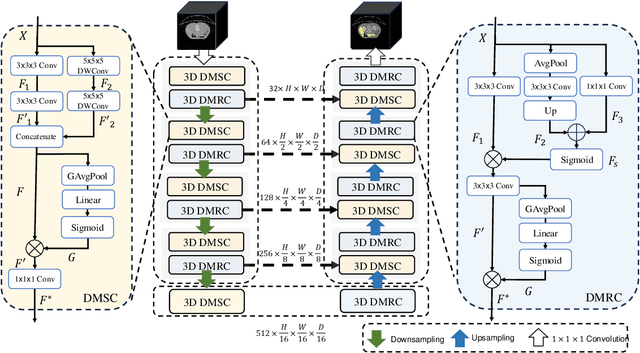
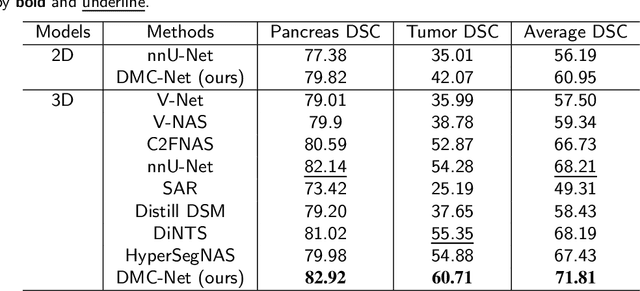
Convolutional neural networks (CNNs) have shown great effectiveness in medical image segmentation. However, they may be limited in modeling large inter-subject variations in organ shapes and sizes and exploiting global long-range contextual information. This is because CNNs typically employ convolutions with fixed-sized local receptive fields and lack the mechanisms to utilize global information. To address these limitations, we developed Dynamic Multi-Resolution Convolution (DMRC) and Dynamic Multi-Scale Convolution (DMSC) modules. Both modules enhance the representation capabilities of single convolutions to capture varying scaled features and global contextual information. This is achieved in the DMRC module by employing a convolutional filter on images with different resolutions and subsequently utilizing dynamic mechanisms to model global inter-dependencies between features. In contrast, the DMSC module extracts features at different scales by employing convolutions with different kernel sizes and utilizing dynamic mechanisms to extract global contextual information. The utilization of convolutions with different kernel sizes in the DMSC module may increase computational complexity. To lessen this burden, we propose to use a lightweight design for convolution layers with a large kernel size. Thus, DMSC and DMRC modules are designed as lightweight drop-in replacements for single convolutions, and they can be easily integrated into general CNN architectures for end-to-end training. The segmentation network was proposed by incorporating our DMSC and DMRC modules into a standard U-Net architecture, termed Dynamic Multi-scale and Multi-resolution Convolution network (DMC-Net). The results demonstrate that our proposed DMSC and DMRC can enhance the representation capabilities of single convolutions and improve segmentation accuracy.