 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-OT: An Optimal Transport Regularization Paradigm for Knowledge Preservation in Vision-Language Model Adaptation
Paper and Code
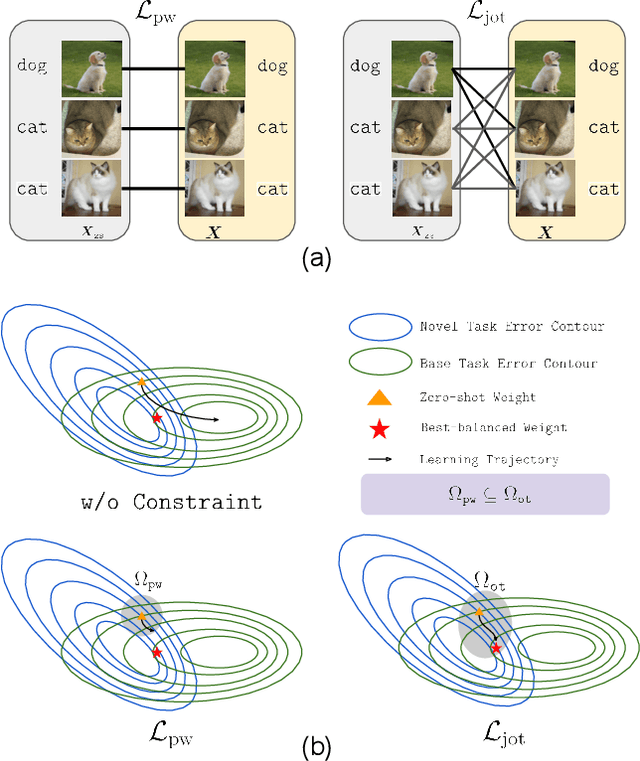



Vision-language models (VLMs) such as CLIP demonstrate strong performance but struggle when adapted to downstream tasks. Prompt learning has emerged as an efficient and effective strategy to adapt VLMs while preserving their pre-trained knowledge. However, existing methods still lead to overfitting and degrade zero-shot generalization. To address this challenge, we propose an optimal transport (OT)-guided prompt learning framework that mitigates forgetting by preserving the structural consistency of feature distributions between pre-trained and fine-tuned models. Unlike conventional point-wise constraints, OT naturally captures cross-instance relationships and expands the feasible parameter space for prompt tuning, allowing a better trade-off between adaptation and generalization. Our approach enforces joint constraints on both vision and text representations, ensuring a holistic feature alignment. Extensive experiments on benchmark datasets demonstrate that our simple yet effective method can outperform existing prompt learning strategies in base-to-novel generalization, cross-dataset evaluation, and domain generalization without additional augmentation or ensemble techniques. The code is available at https://github.com/ChongQingNoSubway/Prompt-OT