 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
Jun 03, 2026Language agents increasingly rely on reusable skills to improve multi-step web automation across related tasks. A growing line of work studies online skill learning, where agents continually induce skills from previous task trajectories and reuse them in future tasks on the fly. However, existing methods mainly reuse skills at the task-level: a fixed set of skills is retrieved based on the initial task instruction and then held fixed throughout execution. This static strategy is misaligned with web execution, where the appropriate next action depends not only on the task goal but also on the current webpage state, which often transitions into situations that the initial skills fail to cover. To address this gap, we propose State-Grounded Dynamic Retrieval (SGDR), an online skill learning method that enables stepwise skill reuse for web agents. SGDR consists of three components: a sliding-window extraction process that turns completed trajectories into reusable sub-procedures invokable at intermediate execution states, a dual text-code representation that connects skill retrieval with executable action, and a state-grounded dynamic retrieval mechanism that matches skills to both the task goal and the current webpage state. Experiments on WebArena across five domains show that SGDR consistently outperforms strong baselines, achieving average success rates of 37.5% with GPT-4.1 and 24.3% with Qwen3-4B, corresponding to relative gains of 10.6% and 10.0% over the strongest baseline, respectively. The code is available at https://github.com/plusnli/skill-dynamic-retrieval.
ProtStructQA: A Denotation Threshold in Protein Structural Reasoning
May 30, 2026Protein-language systems are often evaluated by whether they generate plausible biological text, but a structural question has a sharper semantics: it denotes a measurement in a 3D coordinate system. We introduce ProtStructQA, an executable benchmark for protein structural question answering in which each natural-language question is generated from a hidden typed domain-specific language (DSL) program and the answer is obtained by executing that program on an AlphaFold-predicted structure. ProtStructQA releases 382.2K questions covering confidence, distances, predicted aligned error (PAE), solvent exposure, secondary structure, topology and contacts, and held-out compositions: a 330K active benchmark over 10K proteins from four species, plus a 52.2K hard-negative robustness pool. Without fine-tuning, we evaluate Qwen3 models from 0.6B to 8B under direct prompting, chain-of-thought, grammar-constrained executable voting, executable voting with chain-of-thought, and multi-turn ReAct-style tool use, and replicate the headline finding on Gemma-3-1B and Gemma-3-12B. We find a capability-dependent denotation threshold between Qwen3-1.7B and Qwen3-4B: below it, tool-mediated ReAct dominates because models often fail to produce executable denotations; above it, chain-of-thought flips from mostly harmful to strongly beneficial and becomes the strongest strategy on most splits. Parse-failure and family-level analyses show that the threshold is a transition from unparseable language to executable structural denotation, while grammar and execution remain selectively valuable for PAE and secondary-structure queries. ProtStructQA reframes scientific QA as compilation from language to measurement and provides a diagnostic testbed for when language models can map words to executable 3D structural measurements.
LastAct: Trajectory-Guided Latest-Activity Localization for Real-Time Smart-Home Activity Recognition
May 29, 2026Human Activity Recognition (HAR) from ambient sensors enables smart-home applications such as health monitoring and assisted living. In realistic deployments, however, sensor events arrive as a continuous stream and activity boundaries are unknown. Sliding-window inference therefore produces many windows that straddle transitions and contain mixed activities, creating boundary contamination that violates the pre-segmented instance assumption used by most benchmarks and models. Moreover, many pipelines under-use spatial context by treating sensor IDs as independent tokens. We present LastAct, a trajectory-centric framework for streaming smart-home HAR that targets the most recent activity under mixed windows while explicitly modeling spatial structure. LastAct projects sensor events onto the home floorplan to form a layout-aligned trajectory image sequence that preserves spatial continuity. A lightweight gate identifies contaminated windows, and a boundary localizer estimates the last transition to enable boundary-guided masking that emphasizes post-boundary evidence and suppresses stale context. For efficiency, we reuse a precomputed layout-aligned template cache to avoid repeated rendering. Empirically, across four public smart-home datasets under near-realistic mixed-activity protocols, LastAct achieves competitive or superior performance on pure windows and yields substantial Macro-F1 gains on cross/mixed windows, demonstrating improved robustness under near-realistic sliding-window regimes.
MindZero: Learning Online Mental Reasoning With Zero Annotations
May 29, 2026Effective real-world assistance requires AI agents with robust Theory of Mind (ToM): inferring human mental states from their behavior. Despite recent advances, several key challenges remain, including (1) online inference with robust uncertainty updates over multiple hypotheses; (2) efficient reasoning suitable for real-time assistance; and (3) the lack of ground-truth mental state annotations in real-world domains. We address these challenges by introducing MindZero, a self-supervised reinforcement learning framework that trains multimodal large language models (MLLMs) for efficient and robust online mental reasoning. During training, the model is rewarded for generating mental state hypotheses that maximize the likelihood of observed actions estimated by a planner, similar to model-based ToM reasoning. This method thus eliminates the need for explicit mental state annotations. After training, MindZero internalizes model-based reasoning into fast single-pass inference. We evaluate MindZero against baselines across challenging mental reasoning and AI assistance tasks in gridworld and household domains. We found that LLMs alone are insufficient; model-based methods improve accuracy but are slow, costly, and limited by backbone MLLM capacity. In contrast, MindZero enhances MLLMs' intrinsic ToM ability and significantly outperforms model-based methods in both accuracy and efficiency, showing that mental reasoning can be effectively learned as a self-supervised skill.
Palette: A Modular, Controllable, and Efficient Framework for On-demand Authorized Safety Alignment Relaxation in LLMs
May 22, 2026Current safety alignment of foundation models largely follows a \emph{one-size-fits-all} paradigm, applying the same refusal policy across users and contexts. As a result, models may refuse requests that are unsafe for general users but legitimate for authorized professionals, limiting helpfulness in specialized professional settings. Existing approaches either require costly realignment or rely on inference-time steering that suffers from imprecise control and added latency. To this end, we propose \textsc{Palette}, a modular, controllable, and efficient framework that selectively relaxes refusal behavior on authorized target domains while preserving standard safety elsewhere. Our method identifies a refusal direction via multi-objective search and internalizes it into the model through lightweight adaptation. \textsc{Palette} further supports modular composition: it learns domain-specific safety controls independently and composes them through parameter merging, enabling on-demand multi-domain authorization without retraining. Experiments across four safety benchmarks, multiple model variants, and both LLMs and VLMs show that \textsc{Palette} delivers precise safety control without sacrificing general utility, offering a practical path toward foundation models that adapt to diverse professional needs.
LARV: Data-Free Layer-wise Adaptive Rescaling Veneer for Model Merging
Feb 10, 2026Model merging aims to combine multiple fine-tuned models into a single multi-task model without access to training data. Existing task-vector merging methods such as TIES, TSV-M, and Iso-C/CTS differ in their aggregation rules but treat all layers nearly uniformly. This assumption overlooks the strong layer-wise heterogeneity in large vision transformers, where shallow layers are sensitive to interference while deeper layers encode stable task-specific features. We introduce LARV, a training-free, data-free, merger-agnostic Layer-wise Adaptive Rescaling Veneer that plugs into any task-vector merger and assigns a per-layer scale to each task vector before aggregation, and show it consistently boosts diverse merging rules. LARV adaptively suppresses shallow-layer interference and amplifies deeper-layer alignment using a simple deterministic schedule, requiring no retraining or modification to existing mergers. To our knowledge, this is the first work to perform layer-aware scaling for task-vector merging. LARV computes simple data-free layer proxies and turns them into scales through a lightweight rule; we study several instantiations within one framework (e.g., tiered two/three-level scaling with fixed values, or continuous mappings) and show that tiered choices offer the best robustness, while continuous mappings remain an ablation. LARV is orthogonal to the base merger and adds negligible cost. On FusionBench with Vision Transformers, LARV consistently improves all task-vector baselines across 8/14/20-task settings; for example, Iso-C + LARV reaches 85.9% on ViT-B/32, 89.2% on ViT-B/16, and 92.6% on ViT-L/14. Layerwise analysis and corruption tests further indicate that LARV suppresses shallow-layer interference while modestly amplifying deeper, task-stable features, turning model merging into a robust, layer-aware procedure rather than a uniform one.
MARAuder's Map: Motion-Aware Real-time Activity Recognition with Layout-Based Trajectories
Nov 08, 2025Ambient sensor-based human activity recognition (HAR) in smart homes remains challenging due to the need for real-time inference, spatially grounded reasoning, and context-aware temporal modeling. Existing approaches often rely on pre-segmented, within-activity data and overlook the physical layout of the environment, limiting their robustness in continuous, real-world deployments. In this paper, we propose MARAuder's Map, a novel framework for real-time activity recognition from raw, unsegmented sensor streams. Our method projects sensor activations onto the physical floorplan to generate trajectory-aware, image-like sequences that capture the spatial flow of human movement. These representations are processed by a hybrid deep learning model that jointly captures spatial structure and temporal dependencies. To enhance temporal awareness, we introduce a learnable time embedding module that encodes contextual cues such as hour-of-day and day-of-week. Additionally, an attention-based encoder selectively focuses on informative segments within each observation window, enabling accurate recognition even under cross-activity transitions and temporal ambiguity. Extensive experiments on multiple real-world smart home datasets demonstrate that our method outperforms strong baselines, offering a practical solution for real-time HAR in ambient sensor environments.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
ADLGen: Synthesizing Symbolic, Event-Triggered Sensor Sequences for Human Activity Modeling
May 23, 2025

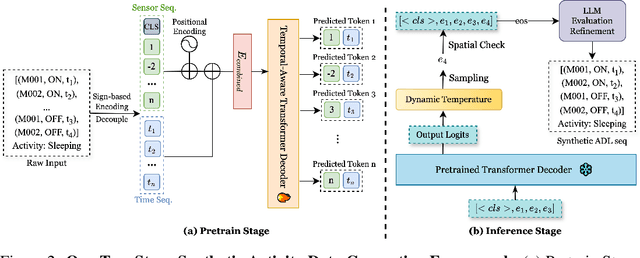

Real world collection of Activities of Daily Living data is challenging due to privacy concerns, costly deployment and labeling, and the inherent sparsity and imbalance of human behavior. We present ADLGen, a generative framework specifically designed to synthesize realistic, event triggered, and symbolic sensor sequences for ambient assistive environments. ADLGen integrates a decoder only Transformer with sign based symbolic temporal encoding, and a context and layout aware sampling mechanism to guide generation toward semantically rich and physically plausible sensor event sequences. To enhance semantic fidelity and correct structural inconsistencies, we further incorporate a large language model into an automatic generate evaluate refine loop, which verifies logical, behavioral, and temporal coherence and generates correction rules without manual intervention or environment specific tuning. Through comprehensive experiments with novel evaluation metrics, ADLGen is shown to outperform baseline generators in statistical fidelity, semantic richness, and downstream activity recognition, offering a scalable and privacy-preserving solution for ADL data synthesis.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025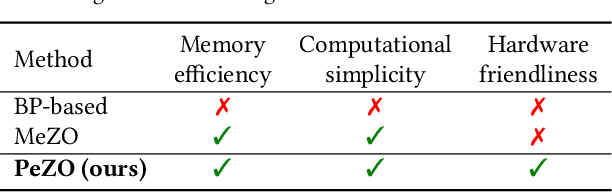
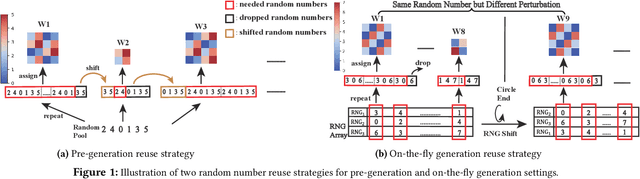
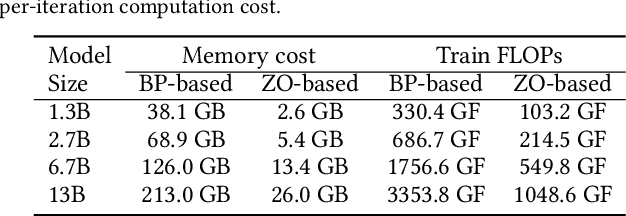
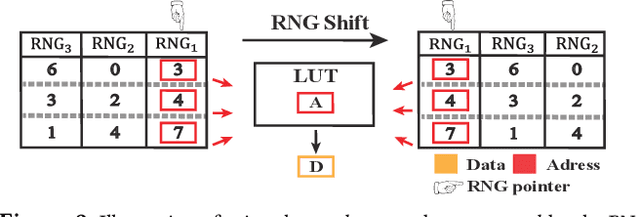
Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.