 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
Automating Expert-Level Medical Reasoning Evaluation of Large Language Models
Jul 10, 2025As large language models (LLMs) become increasingly integrated into clinical decision-making, ensuring transparent and trustworthy reasoning is essential. However, existing evaluation strategies of LLMs' medical reasoning capability either suffer from unsatisfactory assessment or poor scalability, and a rigorous benchmark remains lacking. To address this, we introduce MedThink-Bench, a benchmark designed for rigorous, explainable, and scalable assessment of LLMs' medical reasoning. MedThink-Bench comprises 500 challenging questions across ten medical domains, each annotated with expert-crafted step-by-step rationales. Building on this, we propose LLM-w-Ref, a novel evaluation framework that leverages fine-grained rationales and LLM-as-a-Judge mechanisms to assess intermediate reasoning with expert-level fidelity while maintaining scalability. Experiments show that LLM-w-Ref exhibits a strong positive correlation with expert judgments. Benchmarking twelve state-of-the-art LLMs, we find that smaller models (e.g., MedGemma-27B) can surpass larger proprietary counterparts (e.g., OpenAI-o3). Overall, MedThink-Bench offers a foundational tool for evaluating LLMs' medical reasoning, advancing their safe and responsible deployment in clinical practice.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025



Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Through the Valley: Path to Effective Long CoT Training for Small Language Models
Jun 09, 2025Long chain-of-thought (CoT) supervision has become a common strategy to enhance reasoning in language models. While effective for large models, we identify a phenomenon we call Long CoT Degradation, in which small language models (SLMs; <=3B parameters) trained on limited long CoT data experience significant performance deterioration. Through extensive experiments on the Qwen2.5, LLaMA3 and Gemma3 families, we demonstrate that this degradation is widespread across SLMs. In some settings, models trained on only 8k long CoT examples lose up to 75% of their original performance before fine-tuning. Strikingly, we further observe that for some particularly small models, even training on 220k long CoT examples fails to recover or surpass their original performance prior to fine-tuning. Our analysis attributes this effect to error accumulation: while longer responses increase the capacity for multi-step reasoning, they also amplify the risk of compounding mistakes. Furthermore, we find that Long CoT Degradation may negatively impacts downstream reinforcement learning (RL), although this can be alleviated by sufficiently scaled supervised fine-tuning (SFT). Our findings challenge common assumptions about the benefits of long CoT training for SLMs and offer practical guidance for building more effective small-scale reasoning models.
LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges
May 24, 2025Text-to-SQL is a fundamental task in natural language processing that seeks to translate natural language questions into meaningful and executable SQL queries. While existing datasets are extensive and primarily focus on business scenarios and operational logic, they frequently lack coverage of domain-specific knowledge and complex mathematical reasoning. To address this gap, we present a novel dataset tailored for complex reasoning and chain-of-thought analysis in SQL inference, encompassing physical, arithmetic, commonsense, and hypothetical reasoning. The dataset consists of 4,038 English questions, each paired with a unique SQL query and accompanied by 12,114 step-by-step reasoning annotations, spanning 45 databases across diverse domains. Experimental results demonstrate that LogicCat substantially increases the difficulty for state-of-the-art models, with the highest execution accuracy reaching only 14.96%. Incorporating our chain-of-thought annotations boosts performance to 33.96%. Benchmarking leading public methods on Spider and BIRD further underscores the unique challenges presented by LogicCat, highlighting the significant opportunities for advancing research in robust, reasoning-driven text-to-SQL systems. We have released our dataset code at https://github.com/Ffunkytao/LogicCat.
Casual Inference via Style Bias Deconfounding for Domain Generalization
Mar 21, 2025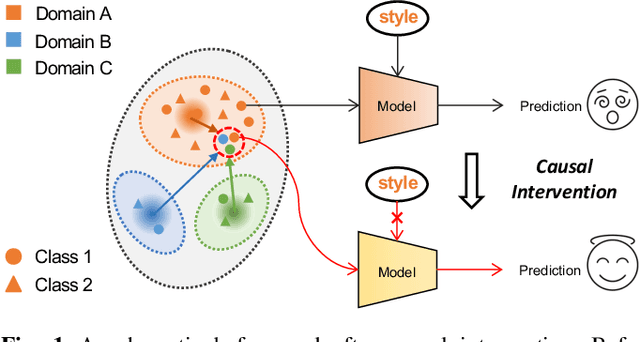
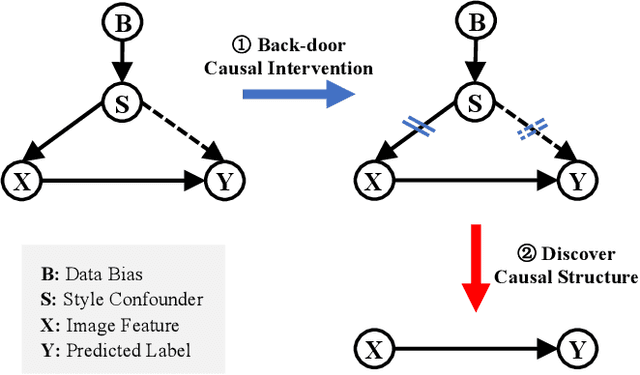
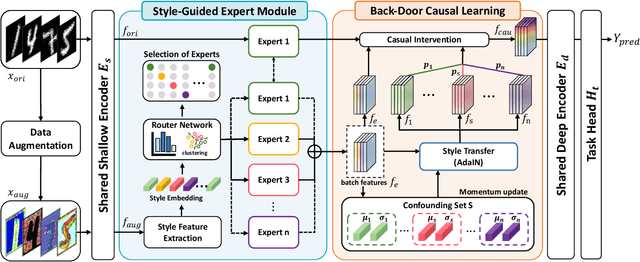
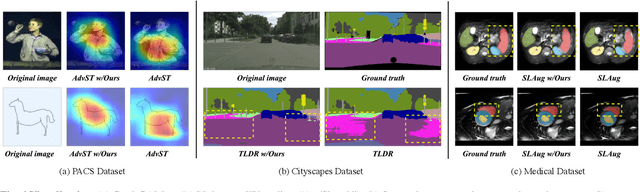
Deep neural networks (DNNs) often struggle with out-of-distribution data, limiting their reliability in diverse realworld applications. To address this issue, domain generalization methods have been developed to learn domain-invariant features from single or multiple training domains, enabling generalization to unseen testing domains. However, existing approaches usually overlook the impact of style frequency within the training set. This oversight predisposes models to capture spurious visual correlations caused by style confounding factors, rather than learning truly causal representations, thereby undermining inference reliability. In this work, we introduce Style Deconfounding Causal Learning (SDCL), a novel causal inference-based framework designed to explicitly address style as a confounding factor. Our approaches begins with constructing a structural causal model (SCM) tailored to the domain generalization problem and applies a backdoor adjustment strategy to account for style influence. Building on this foundation, we design a style-guided expert module (SGEM) to adaptively clusters style distributions during training, capturing the global confounding style. Additionally, a back-door causal learning module (BDCL) performs causal interventions during feature extraction, ensuring fair integration of global confounding styles into sample predictions, effectively reducing style bias. The SDCL framework is highly versatile and can be seamlessly integrated with state-of-the-art data augmentation techniques. Extensive experiments across diverse natural and medical image recognition tasks validate its efficacy, demonstrating superior performance in both multi-domain and the more challenging single-domain generalization scenarios.
WildLong: Synthesizing Realistic Long-Context Instruction Data at Scale
Feb 23, 2025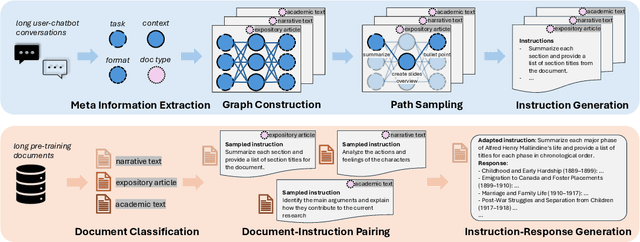
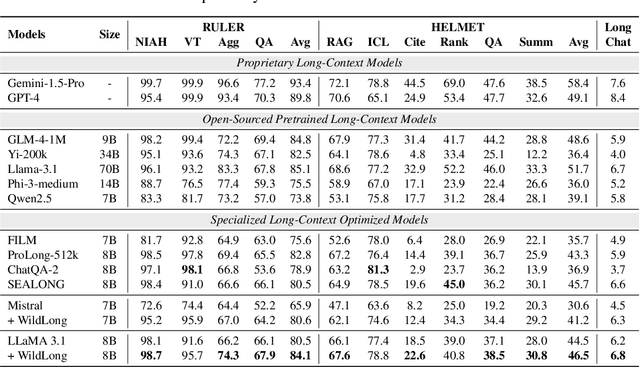
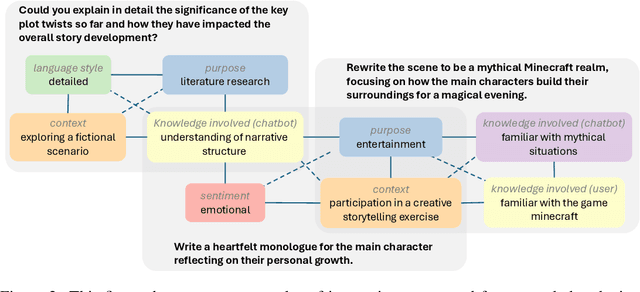
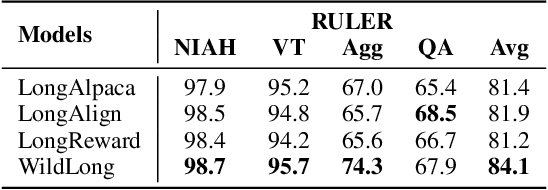
Large language models (LLMs) with extended context windows enable tasks requiring extensive information integration but are limited by the scarcity of high-quality, diverse datasets for long-context instruction tuning. Existing data synthesis methods focus narrowly on objectives like fact retrieval and summarization, restricting their generalizability to complex, real-world tasks. WildLong extracts meta-information from real user queries, models co-occurrence relationships via graph-based methods, and employs adaptive generation to produce scalable data. It extends beyond single-document tasks to support multi-document reasoning, such as cross-document comparison and aggregation. Our models, finetuned on 150K instruction-response pairs synthesized using WildLong, surpasses existing open-source long-context-optimized models across benchmarks while maintaining strong performance on short-context tasks without incorporating supplementary short-context data. By generating a more diverse and realistic long-context instruction dataset, WildLong enhances LLMs' ability to generalize to complex, real-world reasoning over long contexts, establishing a new paradigm for long-context data synthesis.
Fact or Guesswork? Evaluating Large Language Model's Medical Knowledge with Structured One-Hop Judgment
Feb 20, 2025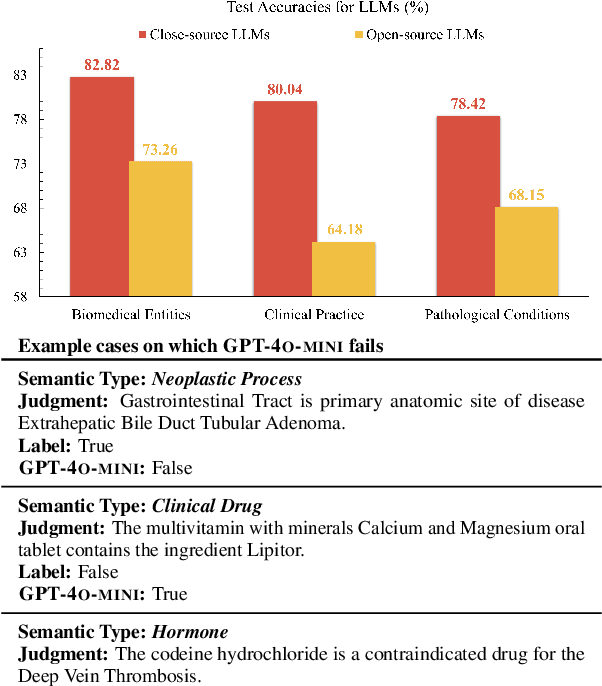
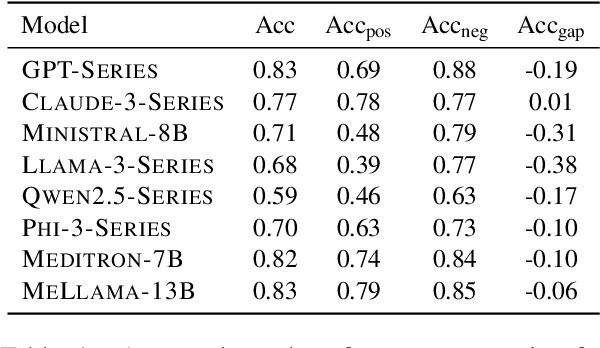
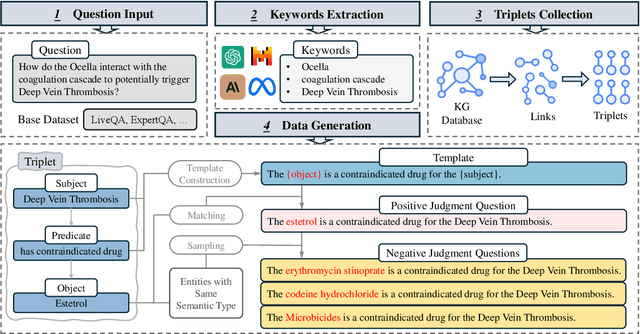
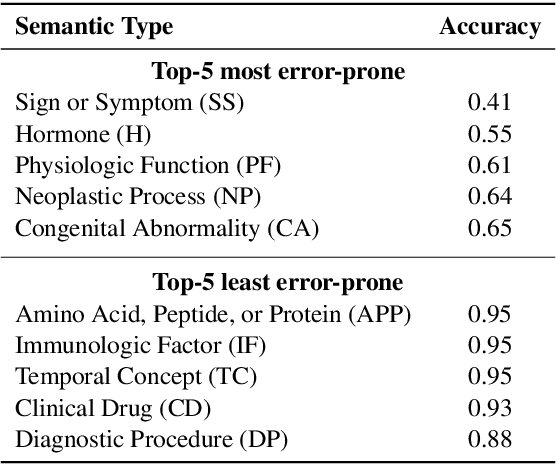
Large language models (LLMs) have been widely adopted in various downstream task domains. However, their ability to directly recall and apply factual medical knowledge remains under-explored. Most existing medical QA benchmarks assess complex reasoning or multi-hop inference, making it difficult to isolate LLMs' inherent medical knowledge from their reasoning capabilities. Given the high-stakes nature of medical applications, where incorrect information can have critical consequences, it is essential to evaluate how well LLMs encode, retain, and recall fundamental medical facts. To bridge this gap, we introduce the Medical Knowledge Judgment, a dataset specifically designed to measure LLMs' one-hop factual medical knowledge. MKJ is constructed from the Unified Medical Language System (UMLS), a large-scale repository of standardized biomedical vocabularies and knowledge graphs. We frame knowledge assessment as a binary judgment task, requiring LLMs to verify the correctness of medical statements extracted from reliable and structured knowledge sources. Our experiments reveal that LLMs struggle with factual medical knowledge retention, exhibiting significant performance variance across different semantic categories, particularly for rare medical conditions. Furthermore, LLMs show poor calibration, often being overconfident in incorrect answers. To mitigate these issues, we explore retrieval-augmented generation, demonstrating its effectiveness in improving factual accuracy and reducing uncertainty in medical decision-making.
HELENE: Hessian Layer-wise Clipping and Gradient Annealing for Accelerating Fine-tuning LLM with Zeroth-order Optimization
Nov 16, 2024



Fine-tuning large language models (LLMs) poses significant memory challenges, as the back-propagation process demands extensive resources, especially with growing model sizes. Recent work, MeZO, addresses this issue using a zeroth-order (ZO) optimization method, which reduces memory consumption by matching the usage to the inference phase. However, MeZO experiences slow convergence due to varying curvatures across model parameters. To overcome this limitation, we introduce HELENE, a novel scalable and memory-efficient optimizer that integrates annealed A-GNB gradients with a diagonal Hessian estimation and layer-wise clipping, serving as a second-order pre-conditioner. This combination allows for faster and more stable convergence. Our theoretical analysis demonstrates that HELENE improves convergence rates, particularly for models with heterogeneous layer dimensions, by reducing the dependency on the total parameter space dimension. Instead, the method scales with the largest layer dimension, making it highly suitable for modern LLM architectures. Experimental results on RoBERTa-large and OPT-1.3B across multiple tasks show that HELENE achieves up to a 20x speedup compared to MeZO, with average accuracy improvements of 1.5%. Furthermore, HELENE remains compatible with both full parameter tuning and parameter-efficient fine-tuning (PEFT), outperforming several state-of-the-art optimizers. The codes will be released after reviewing.
OWLed: Outlier-weighed Layerwise Pruning for Efficient Autonomous Driving Framework
Nov 12, 2024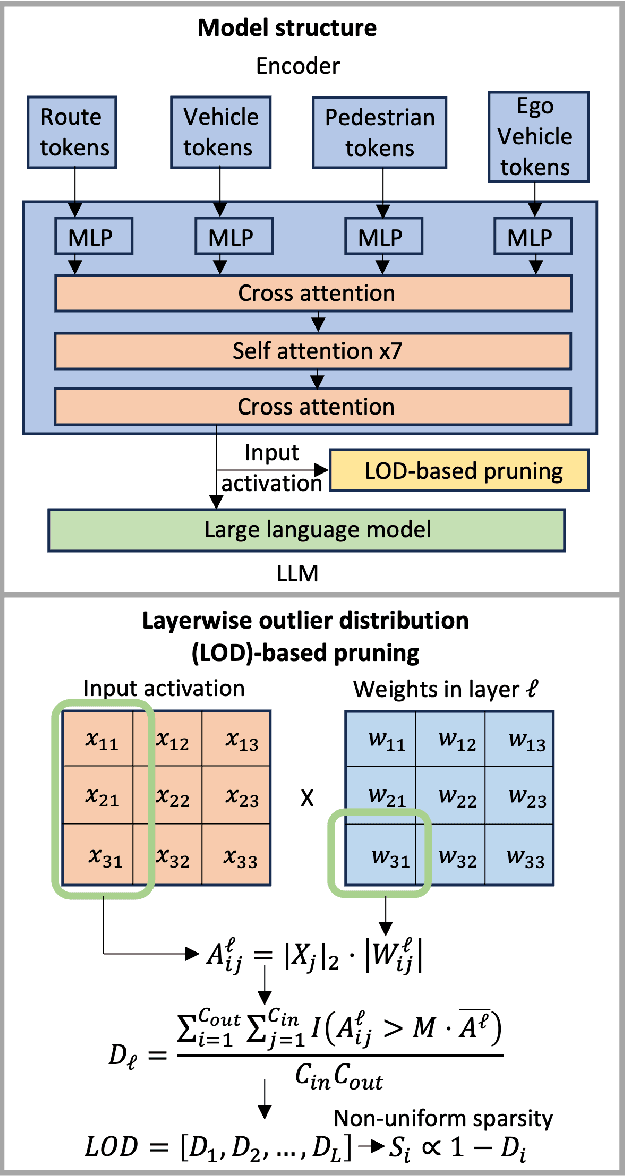
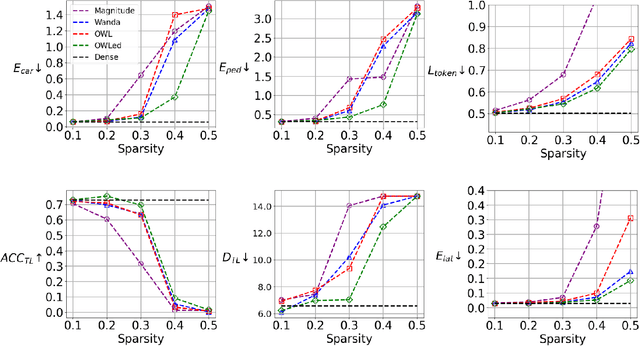
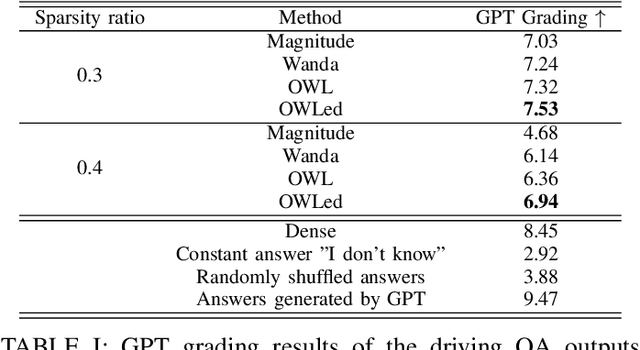
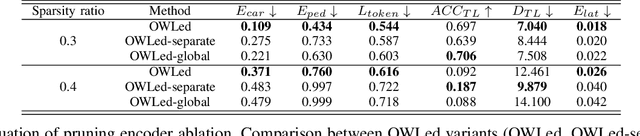
The integration of Large Language Models (LLMs) into autonomous driving systems offers promising enhancements in environmental understanding and decision-making. However, the substantial computational demands of deploying LLMs locally on vehicles render this approach unfeasible for real-world automotive applications. To address this challenge, we introduce OWLed, the Outlier-Weighed Layerwise Pruning for Efficient Autonomous Driving Framework that leverages outlier-weighted layerwise sparsity for model compression. Our method assigns non-uniform sparsity ratios to different layers based on the distribution of outlier features, significantly reducing the model size without the need for fine-tuning. To ensure the compressed model adapts well to autonomous driving tasks, we incorporate driving environment data into both the calibration and pruning processes. Our empirical studies reveal that the encoder component is more sensitive to pruning than the LLM, highlighting its critical role in the system. Experimental results demonstrate that OWLed outperforms existing methods in perception, action prediction, and language understanding while substantially lowering computational requirements. These findings underscore the potential of combining advanced pruning techniques with LLMs to develop efficient and robust autonomous driving systems capable of handling complex scenarios. Code will be made publicly available.